0.개요
BERT는 Bidirectional Encoder Representations from Transformers의 약자로 18년 10월에 논문이 공개된 구글의 새로운 Language Representation Model 이다.
입력문장을 양방향으로 분석하는 모델로, 주어진 시퀀스 다음 다음 단어를 맞추는 것에서 벗어나, 일단 문장 전체를 모델에 알려주고 빈칸[MASK]에 해당하는 단어가 어떤 단어일지 예측하는 과정에서 학습한다.
이를 마스크 언어 모델이라 하며,이 덕분에 BERT의 임베딩 품질이 기존 다른 모델보다 좋다.(Dynamic embedding)
BERT를 이용한 자연어처리는 2단계로 나눈다. 거대 Encoder가 입력 문장들을 임베딩 하여 언어를 모델링하는 언어 모델링 구조 과정과(Pre-train) 이를 fine-tuning하여 여러 자연어 처리 Task를 수행하는 과정이다.
프리트레인을 마친 단어 임베딩(문장임베딩)은 말뭉치의 의미적 문법적 정보를 충분히 담고 있고, 다운스트림 태스크를 수행하기 위한 파인튜닝 추가학습을 통해 임베딩을 다운스트림 태스크에 맞게 업데이트 하게 된다.
--> 최근 자연어 처리 연구동향:
BERT가 등장한 이후로, 특정 자연어 처리 관련 문제를 풀기 위한 연구의 방향성이 “기학습된 언어 모델(pre-trained language model)을 어떻게 활용할 것인가”로 바뀌고 있는 흐름
1.설명
Key Idea:
"Transformer 모델 에서 Encoder부분 만 사용하여 Input을 Embedding한다."
1.1) Architecture
1.2 BERT Architect
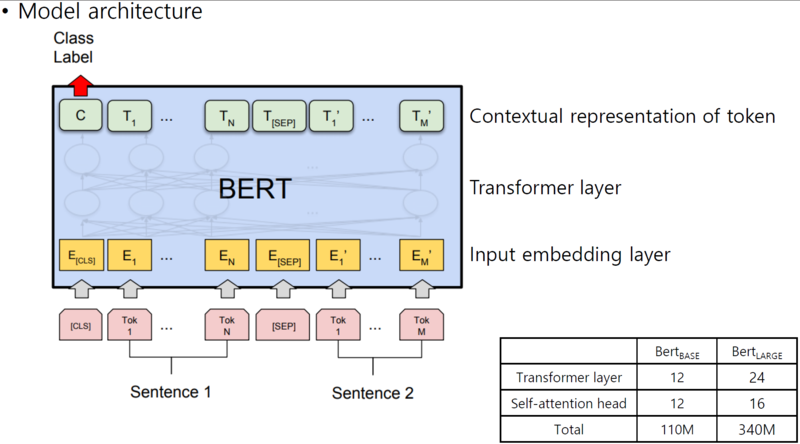
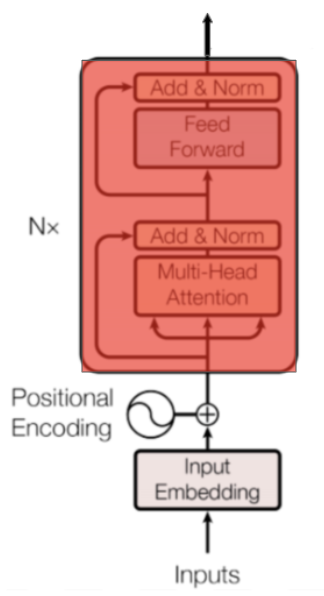
BERT 모델은 Transformer를 기반으로 한다. Transformer 인코더-디코더로 이루어진 모델이며 기존 인코더-디코더 모델들과 다르게 Transformer는 CNN, RNN을 이용하지 않고 Self-attention이라는 개념을 도입하였다. BERT는 Transformer의 인코더-디코더 중 인코더만 사용하는 모델이다.
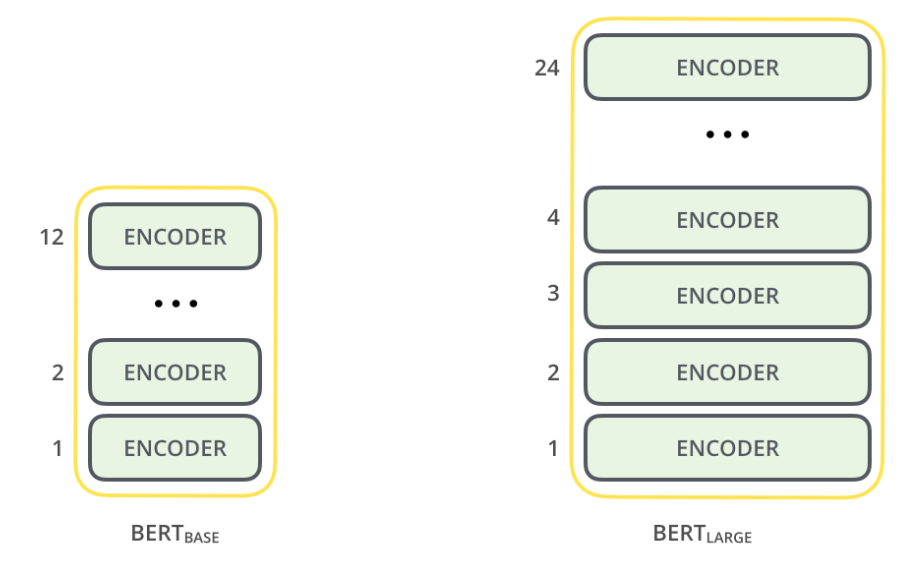
BERT는 2가지 버전이 있다. BERT-base(L=12, H=768, A=12), BERT-large(L=24, H=1024, A=16)이다. L은 Transformer 블록의 숫자이고 H는 hidden size, A는 Transformer의 Attention block 숫자이다. 즉 L, H, A가 크다는 것은 블록을 많이 쌓았고, 표현하는 은닉층이 크며 Attention 개수를 많이 사용하였다는 뜻이다. BERT-base는 1.1억개의 학습 파라미터, BERT-large는 3.4억개의 학습 파라미터가 있다.
(각 Encoder는 이전의 출력값을 입력값으로 사용)
**BERT Base model**
* Sequence=512
L=12
H=768
A=12
Total parameters = 110M
**BERT Large model**
* Sequence=512
L=24
H=1024
A=16
Total parameters = 340M
L: 레이어(Transformer Block)의 수
H: hidden size
A: Self-attention heads의 수
2. 학습 방법(Pre-Train)
2-1) 임베딩 레이어
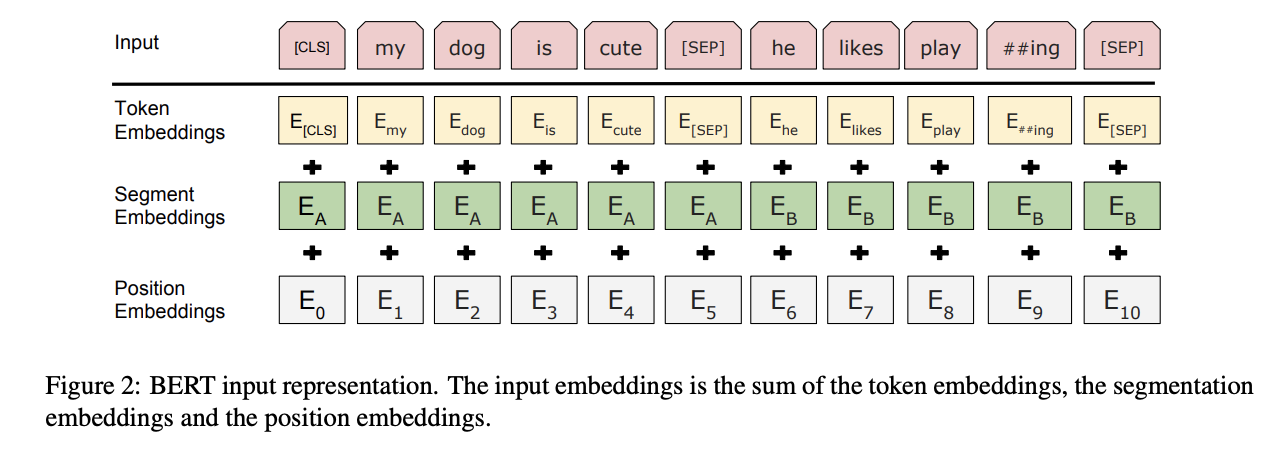
NLP에서 Embedding 레이어의 역할 중 가장 중요한 것은 자연어를 인공신경망이 이해(학습)할 수 있는 차원으로 변환하는 것으로,tokenizer를 통해서 입력 문장을 토큰단위로 쪼개고, 해당 토큰을 vocab에 매칭하여 id(숫자)로 입력한다.
vocab의 사이즈는 보통 5만정도를 사용하고 있고, 이것을 직접 입력하여 BERT 모델을 구축하면 학습해야하는 파라미터의 수가 엄청나게 많아지기 때문에 차원을 낮추기 위해서 embedding layer를 사용한다. 이러한 임베딩 작업을 통해 토큰을 벡터로서 표현하기 때문에 상대적으로 적은 차원의 수로 표현할 수 있게 된다.
생성된 Token Embedding에, 각 토큰의 위치 정보를 임베딩하는 Positional Embedding과, 문장을 구분하는 segment embedding까지 총 3개의 embedding을 결합하여 임베딩 표현한다.
## token embeding + position embeding + segment embeding
e = self.tok_embed(x) + self.pos_embed(pos) + self.seg_embed(seg)Masked Language Model(MLM)과 Next Sentence Prediction(NSP)을 사용하여 Bi-Direction으로 학습한다.
토큰수가 11개인 문장이라면 트랜스포머 블록의 입력 행렬 크기는
11*차원수 가 된다.
토큰 세그먼트 포지션 벡터를 만들때 참조하는 행렬은 프리트레인 태스크 수행을 잘하는 방향으로 다른 학습 파라미터와 함께 업데이트 된다.
2.2 인코딩(트랜스포머의 인코딩단만 사용) 레이어
BERT는 N개의 인코더 블럭을 지니고 있다. Base 모델은 12개, Large 모델은 24개로 구성되는데, 이는 입력 시퀀스 전체의 의미를 N번 만큼 반복적으로 구축하는 것을 의미한다. 당연히 인코더 블럭의 수가 많을수록 단어 사이에 보다 복잡한 관계를 더 잘 포착할 수 있다.
(인코더 블럭은 이전 출력값을 현재의 입력값으로 하는 RNN과 유사한 특징을 지니고 있다. 따라서 이 부분은 병렬 처리가 아닌 Base 모델은 12번, Large 모델은 24번, 전체가 Recursive하게 반복 처리되는 형태로 구성)
- 셀프 어텐션
인코더 블럭의 가장 핵심적인 부분은 Multi-Head Attention 이다. 말 그대로 헤드가 여러개인 어텐션을 뜻하는데, 서로 다른 가중치 행렬을 이용해 어텐션을
h번 계산한 다음 이를 서로 연결Concatenates한 결과를 갖는다.
BERT-Base 모델의 경우 각각의 토큰 벡터 768차원을 헤드 수 만큼인 12등분 하여 64개씩 12조각으로 차례대로 분리한다. 여기에 Scaled Dot-Product Attention을 적용하고 다시 768차원으로 합친다. 그렇게 되면 768차원 벡터는 각각 부위별로 12번 Attention 받은 결과가 된다.
- 피드 포워드 네트워크
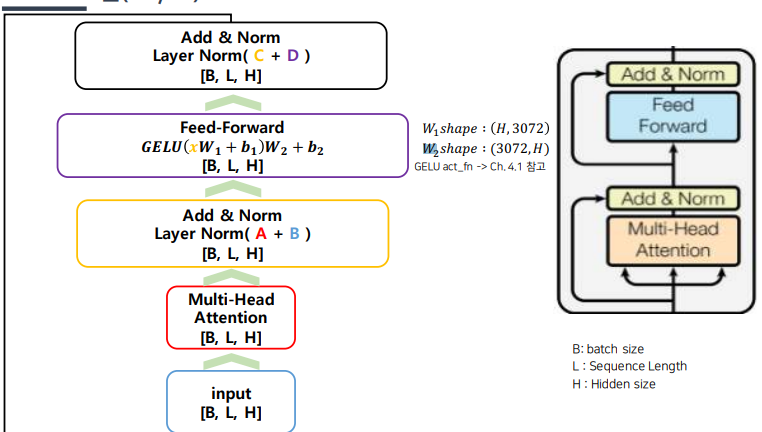
셀프 어텐션을 거치고 난 출력은 Feedforwad 네트워크 레이어에서는 두번의 선형변환(linear transform)을 하게 된다.
(2개의 레이어는 첫번째는 GeLU를 거치는 비선형, 두번째 레이어는 선형으로 출력된다.)
이때 중간의 히든 차원 수를 원래 차원의 네배까지 늘렸다가 다시 원상복구 시킨다.이렇게 고무줄처럼 차원이 늘었다가 줄어드는게 블록이 계속될때마다 반복된다.
셀프 어텐션을 통해 나온 정보를 피드 포워드 네트워크를 통과시켜 정보를 정리하는데, 첫번째 층은 비선형성을 추가해주고 두번째는 선형으로 연산함 신경망 2레이어 이상으로 히든 유닛이 충분히 사용되면 어떠한 연속 함수도 표현(근사)이 가능.
이런 성질을 이용하여 학습하면서 W와 b들을 통해 셀프 어텐션에서 나온 정보를 통과 시켜 정리하는 효과를 얻음
(BERT가 사용하는 트랜스포머 블록에서 원조 트랜스포머와 가장 큰 차이점을 보이는 대목은 Pointwise Feedforward Network 쪽이다. 우선 활성함수를 기존의 ReLu 대신 GeLu 를 쓴다. 정규분포의 누적분포 함수인 GELU는 ReLU보다 0주위에서 부드럽게 변화해 학습 성능을 높인다.)
2.3) 목적함수 -
Masked Language Model(MLM) 과 Next Sentence Prediction(NSP)의 loss를 더한 결과 loss를 줄이는 방향으로 학습.
1) Masked Language Model(MLM)
문장의 랜덤한 단어를 마스킹하고 이를 예측하는 방법으로,
Word2Vec의 CBOW와 유사
마스킹은 학습 데이터 토큰의 15% 중, 80%는 [mask]로 치환, 10%는 랜덤한 단어로 치환, 나머지 10%는 그대로 둔다.
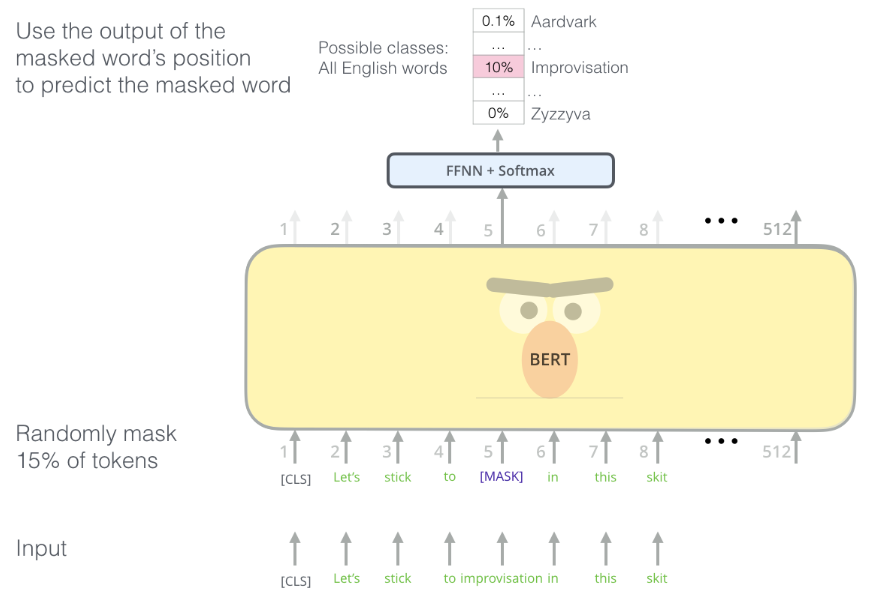
Masked Language Model 은 문장 내 단어의 일부를 [mask] 라는 special token 으로 치환한 뒤, 이 단어가 원래 무엇이었는지를 맞추는 문제이다. Word2Vec 이 앞/뒤의 w개의 단어를 이용하여 가운데 단어를 맞추는 것과 비슷한데, 각 문장마다 15 % 의 단어를 임의로 맞출 것으로, 그 15 % 의 단어를 모두 [mask] 로 치환하지는 않는다. 15 % 중 80 % 는 실제로 [mask] 로 치환하고, 10 % 는 상관없는 임의의 단어, 나머지 10 % 는 단어를 그대로 유지한다. 그리고 모두 다 원래 무슨 단어였는지를 맞추게 된다.
“my dog is [mask]” (80%)
“my dog is apple” (10%)
“my dog is hairy” (10%)
2) Next Sentence Prediction(NSP)
두 문장을 주고 두 번째 문장이 글에서 첫 번째 문장의 바로 다음에 오는지 예측하는 방법이다.
위의 MLM외에도, 한 가지 pre-training task(Next Sentence Prediction(NSP)) 를 동시에 푼다. 두 개의 문장이 연속되기 때문에 앞의 문장을 input 으로, 뒤의 문장이 실로 뒤에 위치하는지 판별하는 문제를 푸는 태스크.( 이를 위하여 50 % 는 실제 문장으로, 나머지 50 % 는 데이터에서 임의로 선택한 문장을 가지고 온다. 이는 Q&A 와 같이 두 개의 문장을 동시에 이용하는 tasks 를 위하여 문장 내 상관성을 BERT 모델에 학습하기 위해 수행됨)
ex)문장 순서를 학습하여 다음에 나온 문장이 순서에 맞는 문장인지 학습
=> 문장1: 저 남자는 회사에 출근했다
=> 문장2: 회사에 출근하자마자 저 남자는 커피를 끓여 마셨다. (순서가 맞음)
=> 문장3: 저 여자는 퇴근하려 한다.
=> 문장4: 강아지는 예쁘다. (순서가 틀린 문장)
3. Fine-Tuning
Fine-Tuning은 Pre-train된 버트모델을 이용해 수행하고자 하는 task를 추가 학습한다.
전이학습은 BERT의 언어 모델의 출력에 추가적인 모델을 쌓아 만든다. 일반적으로 복잡한 CNN, LSTM, Attention을 쌓지 않고 간단한 DNN만 쌓아도 성능이 잘 나오며 별 차이가 없다고 알려져 있다.
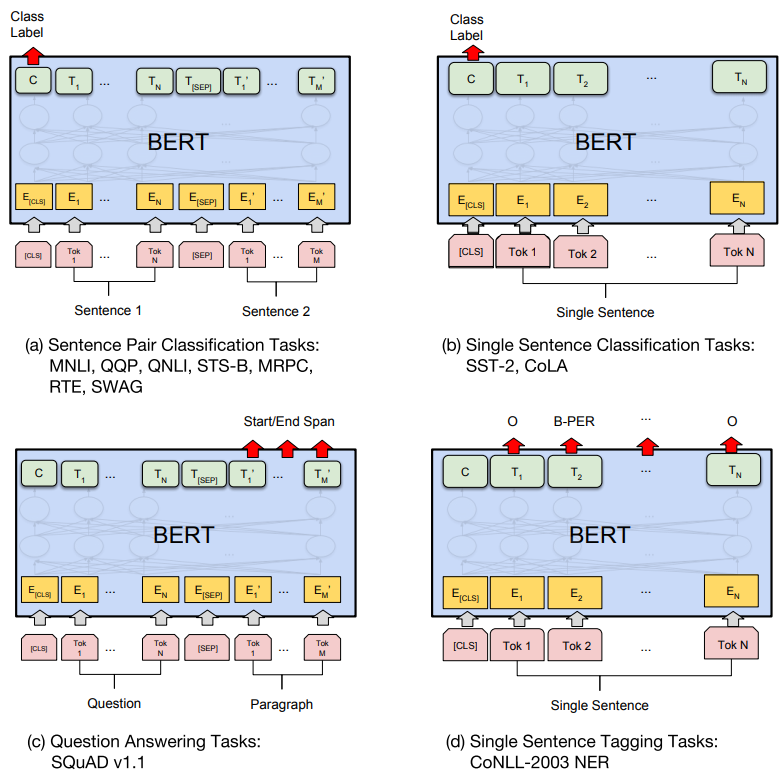
BERT를 각 Task에 쓰기위한 예시는 위 그림과 같다.
(a)는 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간 관계를 구한다.
(b)는 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제이다.
(c)는 문장이나 문단 내에서 원하는 정답 위치의 시작과 끝을 구한다.
(d)는 입력 문장 Token들의 개체명(Named entity recognigion)을 구하거나 품사(Part-of-speech tagging) 를 구하는 문제이다. 다른 Task들과 다르게 입력의 모든 Token들에 대해 결과를 구한다.
ex) 파인튜닝으로 입력 문장의 종류(긍/부정)를 분류 하는 task의 경우 classification layer 추가
하이퍼 파라미터 :
몇가지를 제외하고는 pre-training때의 hyper parameter와 대부분 동일하며,다르게 설정하는 부분은 batch size, learning rate, trainig epochs수
4. 한국어 BERT
한국어 Pre-trained model :
1.KoBERT (SKT):
https://github.com/SKTBrain/KoBERT
2.HanBERT(TwoBlockAI):
https://github.com/tbai2019/HanBert-54k-N
3.KoBERT(ETRI(+Saltlux):
http://aiopen.etri.re.kr/service_dataset.php (사용신청을 따로 진행해야 함)
4.Multilingual BERT:
Google에서 발표한 BERT의 다국어 버전으로 104개 언어의 위키피디아 코퍼스를 모두 사용하여 pre-training을 진행,한국어 사용시 어느정도 성능 나옴
Ref) 경량화 모델 (나중에 서비스로 배포할때 고려해야할 부분,추가검토)
- DistilBert:
한국어 DistllKoBERT
(https://github.com/monologg/DistilKoBERT)
ALBERT
RoBERTa
XLnet
MobileBERT
Ref)
0) BERT paper:
https://arxiv.org/pdf/1810.04805.pdf
1)Transformer
Seq2Seq와 비슷, 인코더, 디코더 안에서 Self Attention을 하여 각 item(word 등)간의 연관성을 반영
Encoder(Multi-Head Self Attention + Feed Forward) ->
Decoder(Multi-Head Self Attention + Encoder-Decoder Attention + Feed Forward)
-vector => word, Linear + Softmax
최종적으로 나온 결과를 word로 바꾸기 위해, linear, softmax의 과정을 거친다
2)Attention
Ref) Attention is all you need
https://arxiv.org/pdf/1706.03762.pdf
-
특정 벡터에 집중하여 성능을 높이는 기법으로 아래의 문제점을 해결
-
기존 RNN으로 seq2seq을 풀 때 문제점
- 첫째, 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생한다.
둘째, RNN의 고질적인 문제인 기울기 소실(Vanishing Gradient) 문제가 존재한다.
- 첫째, 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생한다.
-
핵심 아이디어
Seq2Seq에서의 Attention
- I like cat -> 나는 고양이를 좋아해 로 번역할 때, 인코더가 like로 만든 벡터가 디코더가 좋아해를 예측할 때 쓰는 벡터와 유사할 것이다. 즉, 좋아해를 예측할 때 like 벡터를 더 집중적으로 보는 것이다.

BERT 활용하는 부분을 그림으로 보니까 이해가 잘 되네요. 감사합니다.