
데이터베이스
장애회복(recovery)시스템
장애 회복은 트랜잭션의 특성과 관계가 있다.
- Atomicity
- 트랜잭션 장애 발생 시 실행된 operation은 전부 rollback되어야 한다.
- Durability
- 장애 이후에도 commit된 트랜잭션의 데이터에는 영향이 없어야 함
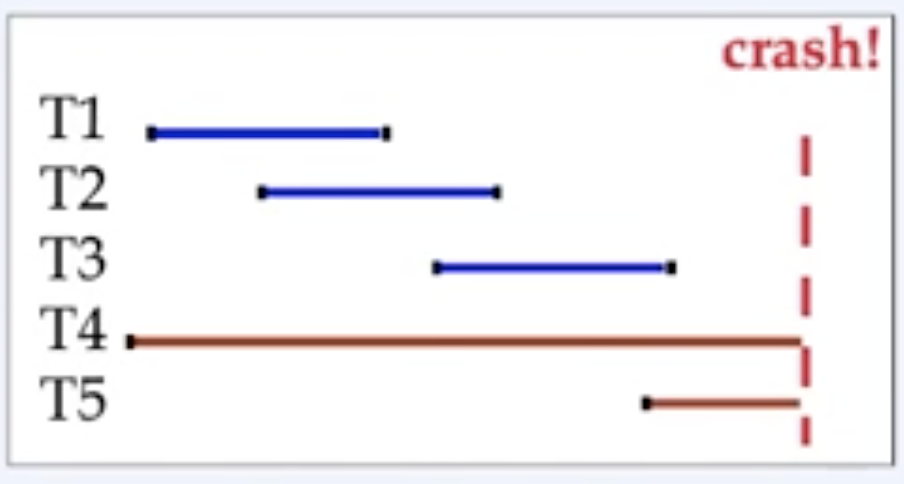
crash 지점에서 장애가 발생했다면, commit이 완료된 t1, t2, t3는 db에 저장되어 있어야 하고 t4, t5는 commit 전에 장애가 났으므로 장애 복구 이후에도 operation이 반영되어 있으면 안된다.
Logging
UNDO
- 모든 액션은 과거 값을 가진채로 log record 생성
- disk 업데이트 전에 log record disk에 적는다.
- commit 로그가 flush되기 전 트랜잭션의 모든 변경사항은 disk에 반영
과거 값을 갖고 있는 로그를 기반으로 지금까지 실행되었던 모든 변경 연산을 취소하는 방법으로 데이터베이스를 복구할 수 있다.
트랜잭션의 commit이나 abort가 없는 경우 정상적으로 종료되지 않은 트랜잭션이기 때문에, 로그를 역순으로 조회하면서 이런 트랜잭션들의 로그에 기록된 과거 값으로 db를 전부 되돌리는 방법이다.
REDO
- 모든 액션은 변경완료된 new 값을 가진채로 log record 생성
- disk 업데이트 이전에 log record를 disk에 적는다.
- 모든 log record를 commit할 때 flush한다.
- 변경 사항이 disk에 반영된 이후에 END log record Write
로그에서 commit은 되었으나 end가 없는 경우, 즉 트랜잭션은 완료되었으나 디스크에 정상적으로 반영되었다고 볼 수 없는 경우에는 연산을 다시 replay해 디스크까지 값을 정상적으로 반영될 수 있도록 한다.
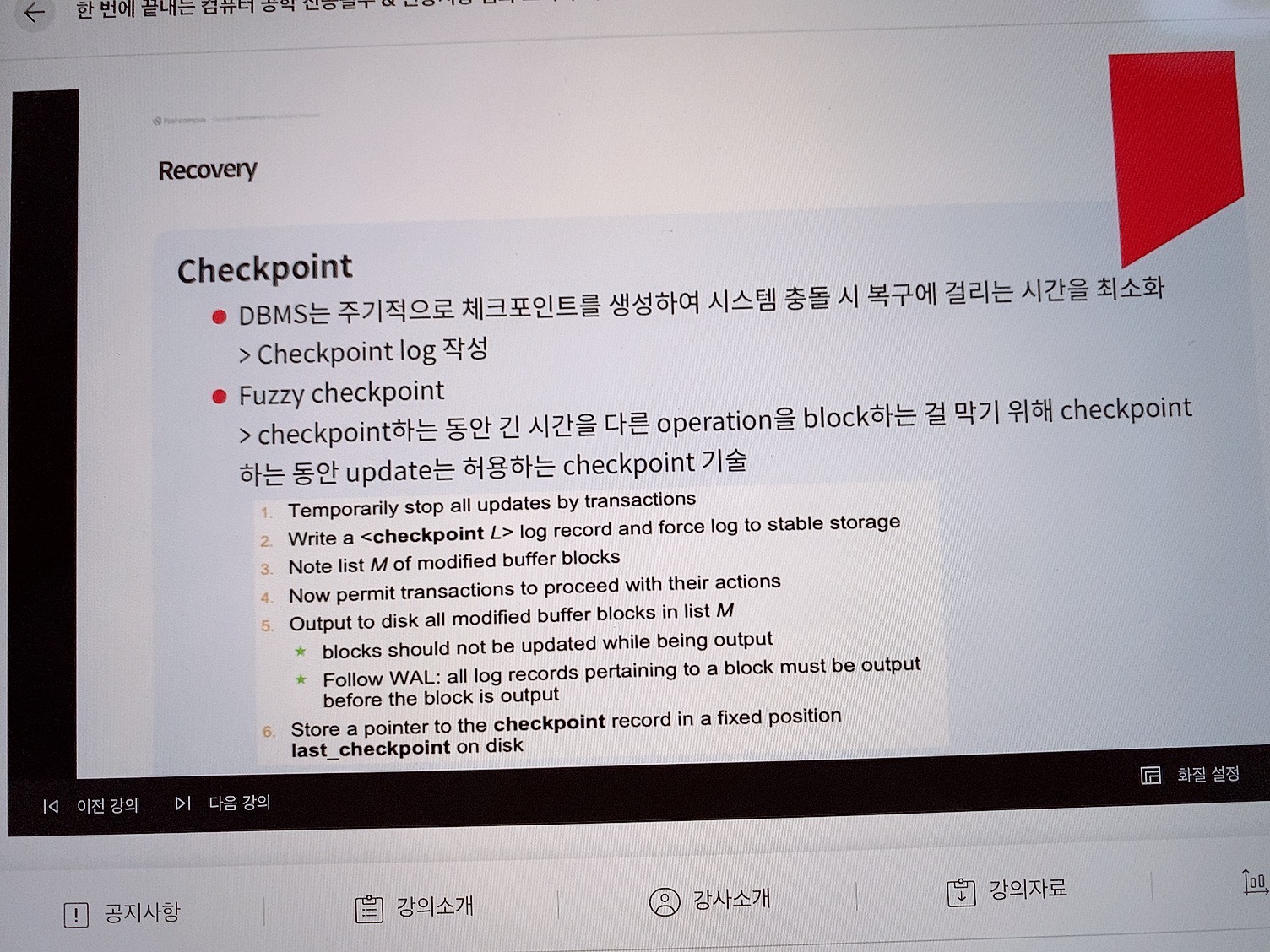
Checkpoint
- 기록되어 있는 모든 UNDO와 REDO를 조회하는 것은 비효율적이다.
- DBMS는 주기적으로 checkpint image(snapshot)를 만들어 여기서부터는 UNDO / REDO 연산을 하지 않아도 된다는 표시를 한다.
Fuzzy checkpoint
checkpoint를 만드는 동안 다른 연산을 허용하기 위해 checkpoint를 생성하는 동안 update는 허용하는 checkpoint 기술
https://bit.ly/3FVdhDa
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.

Devops, AWS에 관심있어요.