Fundamental Node 12
머신러닝 알고리즘의 유형
- 지도 학습 (Supervised learning)
- Classification
- Regression
- Forecasting
-
준지도 학습 (Semi-supervised learning) : 소량의 분류(labeled) 데이터와 미분류 데이터로 학습
-
비지도(자율) 학습 (Unsupervised learning) : 미분류 데이터로 학습
- Clustering : 특정 기준에 따라 유사한 데이터끼리 그룹화함
- Dimension Reduction : 고려해야할 변수를 줄이는 작업, 변수와 대상간 진덩한 관계를 도출하기 용이
- 강화 학습 (Reinforcement learning) : 환경으로부터의 피드백을 기반으로 행위자(agent)의 행동을 분석하고 최적화
- Trial and Error, Delayed Reward 방식이 적용
- Monte Carlo methods
- Q-Learning
- Policy Gradient methods
특정 알고리즘을 사용하는 시점
-
선형 회귀(Linear regression)와 로지스틱 회귀(Logistic regression)
-
선형(Linear) SVM 및 커널(Kernel) SVM
-
트리와 앙상블 트리 (ensemble tree)
- Decision tree : 트리의 깊이가 깊어지면 overfitting현상 발생
- Random forest
- Gradient boosting
- 신경망과 딥러닝
- 신경망 구성 : input layer, hidden layers, output layer
- K-평균/K-모드(k-means/k-modes), 가우시안 혼합 모델(GMM:Gaussian mixture model) 클러스터링
- n개의 관측치(observations)를 k개의 클러스터로 나누는 것
- K-평균 : 표본을 하나의 클러스터에만 강하게 결속시키는 hard assignment를 정의
- GMM : 각 표본이 확률 값을 가짐으로써 어느 한 클러스터에만 결속되지 않는 soft assignment를 정의
- DBSCAN(density-based spatial clustering)
- 클러스터 k의 수가 주어지지 않았을 때에는 밀도 확산(density diffusion)을 통해 표본을 연결함으로써 DBSCAN을 사용할 수 있다.
-
계층적 군집화(Hierarchical clustering)
-
PCA, SVD, LDA
- PCA(principle component analysis) : 주성분 분석, 비지도 클러스터링 방식
- SVD(singular value decomposition) : 특이값 분해, 영화 추천 시스템, NLP과정에서 latent semantic analysis로 알려진 주세 모델링(topic modeling)도구로 널리 사용
- LDA(latent dirichlet allocation) : 잠재 디리클레 할당, NLP와 관련된 기법, LDA는 확률적 주제 모델(probabilistic topic model)로 가우시안 혼합 모델(GMM)이 연속 데이터를 가우시안 밀도로 분해하는 것과 비슷한 방식으로 문서를 주제를 기준으로 분리합니다. GMM과 다르게 LDA는 이산 데이터(discrete data, 문서 내 단어)를 모델링하고, 주제는 디리클레 분포(Dirichlet distribution)에 따라 연역적(priori)으로 분포돼야 하는 제약
워크 플로우
- 문제를 정의한다. 어떤 문제를 해결하고 싶은가?
- 단순하게 시작한다. 데이터와 기준이 되는 결과(baseline results)를 잘 인지하고 있어야 한다.
- 그리고 나서 복잡한 것들을 시도한다.
사이킷런 알고리즘 선택
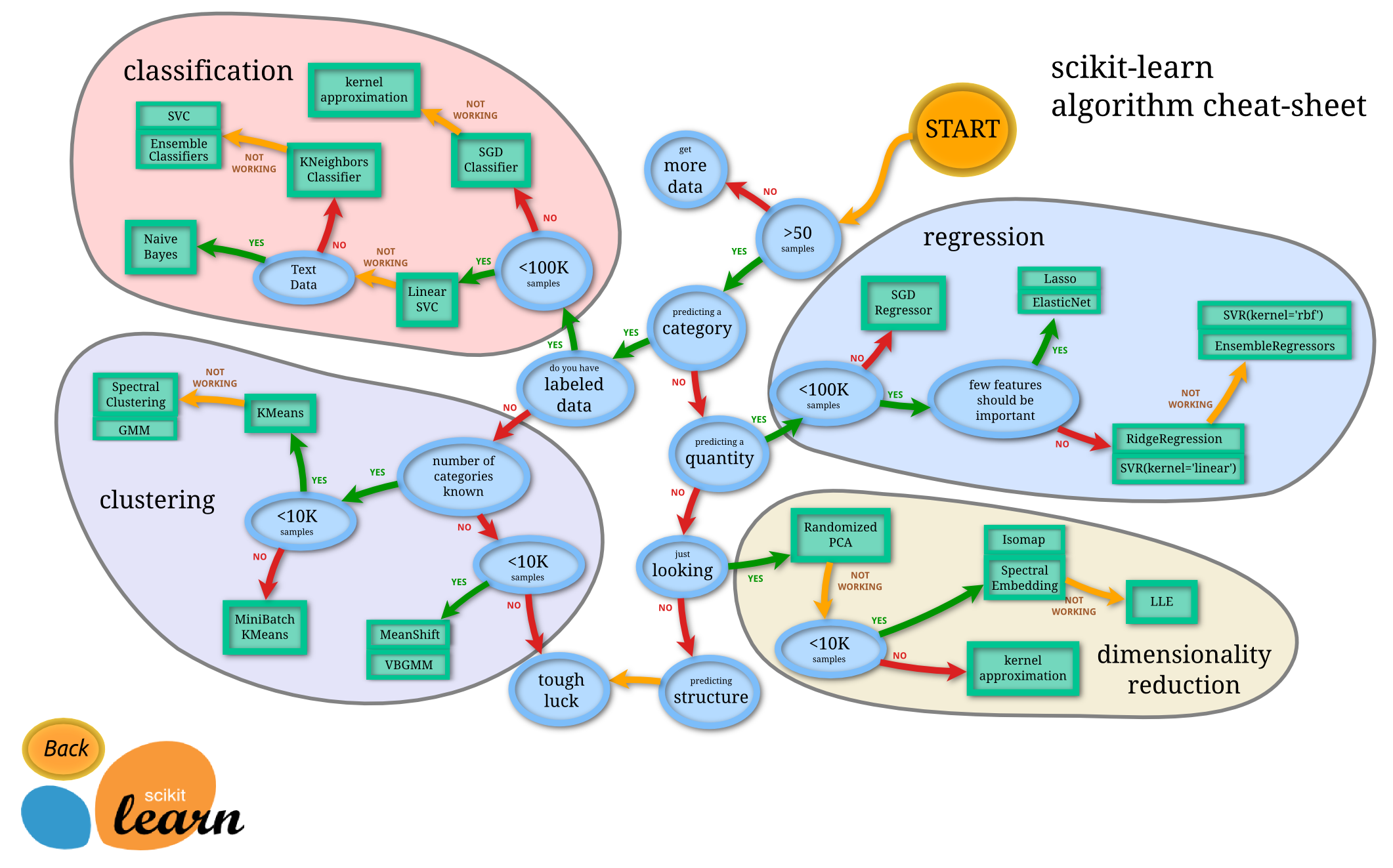
-
transformer()와 Estimator객체의 fit()과 predict()메소드가 중요한것 같습니다. 모델 셀렉션 안의
train_test_split()이란 함수를 이용해 훈련데이터와 테스트데이터를 랜덤하게 섞어줍니다. -
사이킷런은 파이썬 기반 머신러닝 라이브러리로 Scipy 및 NumPy 와 비슷한 데이터 표현과 수학 관련 함수를 갖고 있습니다. 일반적으로 머신러닝에서 데이터 가공(ETL)을 거쳐 모델을 훈련하고 예측하는 과정을 거치는데 ETL부분은 ScikitLearn의 transformer()를 제공하고, 모델의 훈련과 예측은 Estimator 객체를 통해 수행되며, Estimator에는 각각 fit()(훈련), predict()(예측)을 행하는 메소드가 있습니다. 모델의 훈련과 예측이 끝나면 이 2가지는 작업을 Pipeline()으로 묶어 검증을 수행합니다.
-
transformer() : Scikit-Learn 에서 ETL역할을 수행하는 함수
-
Estormator : Sckit-Learn에서 Model로 표현되는 클라스, fit(), predict() 메서드
-
Pipeline : transformer()와 Estimator 기능을 포함
-
Data -> Pipeline(Transformer -> Estimator) -> Output
est_list = [('scalar', 알리고리즈1), ('meta', 알고리즘2)]
model = Pipeline(est_list)
model = StackedClassifier(est_list)사이킷런 주요 모듈

