1260. DFS와 BFS
문제
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
예시
input:
4 5 1
1 2
1 3
1 4
2 4
3 4
output:
1 2 4 3
1 2 3 4풀이
import sys
sys.setrecursionlimit(10**6)
def dfs(current):
visited[current] = True
dfs_list.append(current)
for node in adj[current]:
if not visited[node]:
dfs(node)
def bfs(root):
visited[root] = True
que = []
que.append(root)
while que:
current = que.pop(0)
bfs_list.append(current)
for node in adj[current]:
if not visited[node]:
que.append(node)
visited[node] = True
N, M, V = map(int, sys.stdin.readline().split())
adj = [[] for _ in range(N+1)]
for _ in range(M):
u, v = map(int, sys.stdin.readline().split())
adj[u].append(v)
adj[v].append(u)
[node.sort() for node in adj]
dfs_list = []
bfs_list = []
visited = [False] * (N + 1)
dfs(V)
print(*dfs_list)
visited = [False] * (N + 1)
bfs(V)
print(*bfs_list)백준은 리트코드와 다르게 input을 받는 부분부터 코드를 작성해야하기 때문에 알고리즘 초보인 나에게 런타임 에러를 벗어나는 것은 굉장히 오랜 시간이 걸렸다. 이번 문제는 앞서 언급했던 그래프를 탐색하는 2가지 방법인 DFS와 BFS의 기본 문제이다.
그래프를 탐색하기 위해서는 먼저 그래프를 만들어줘야한다. 그래프를 만들기 위해서는 각 노드가 연결되어 있는 노드들로 구성되어 있는 리스트를 만들어 주어야 한다. 각 노드를 리스트의 인덱스라고 한다면, 예시의 경우에는 [[], [2,3,4], [1,4], [1,4], [1,2,3]] 으로 그래프가 리스트로 표현될 수 있다.
인접노드리스트를 만들었다면 이제 DFS와 BFS의 특징에 따라 그래프를 탐색하게 되면 된다. DFS의 경우에는 연결되는 첫번째 노드를 먼저 탐색하기 때문에 재귀를 사용해서 첫번째 노드의 깊이가 끝날 때까지 탐색하는 과정을 거친다. 다음 BFS는 인접노드리스트에 속한 노드들을 먼저 저장 및 탐색하면서 처음 탐색했던 노드의 다음 노드들을 그 뒤에 저장하는 과정을 거치면서 한 층씩 탐색하게 된다.
추가
- DFS
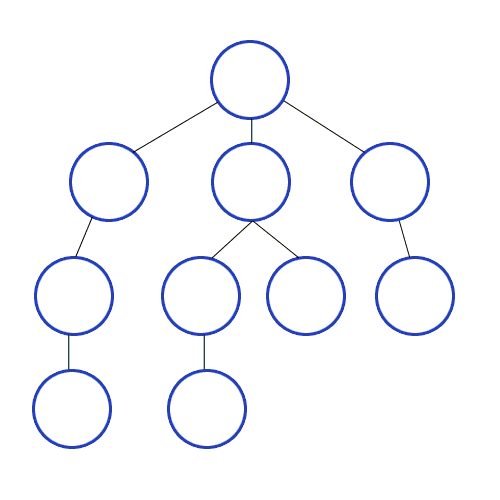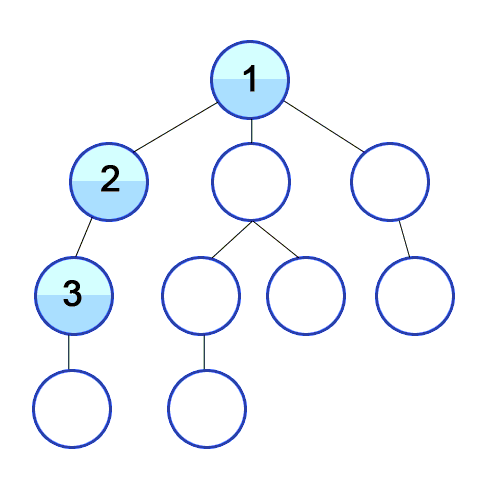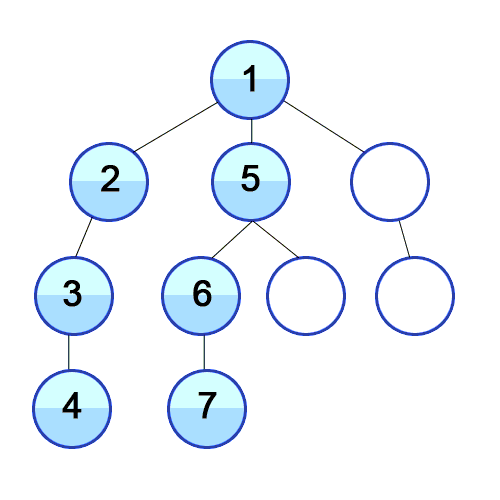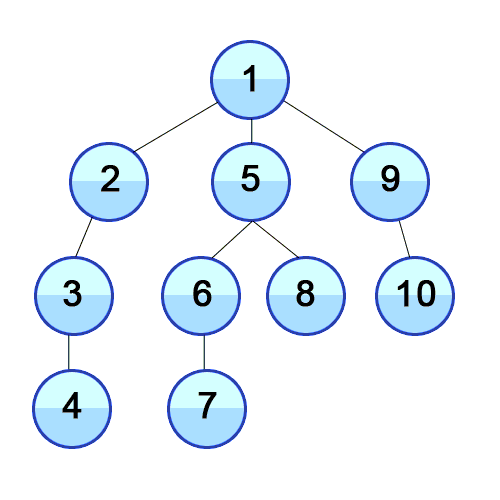
- BFS
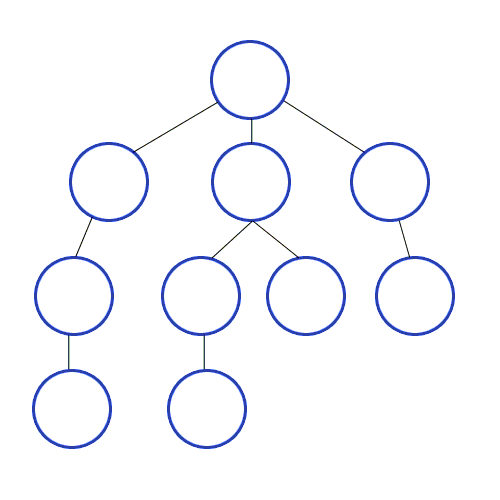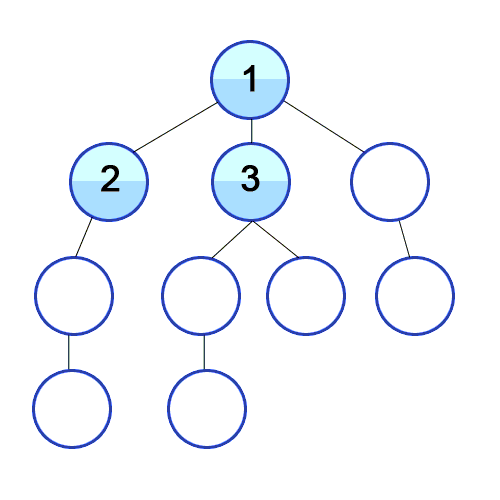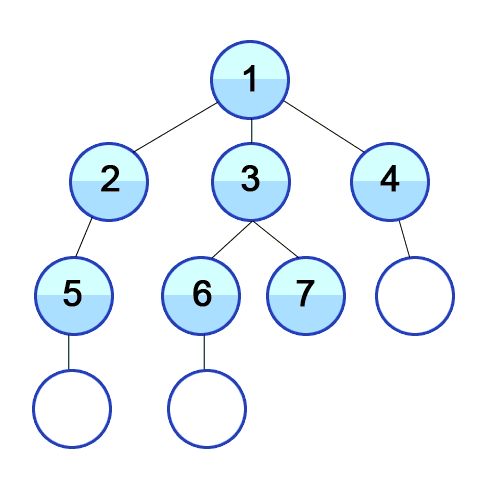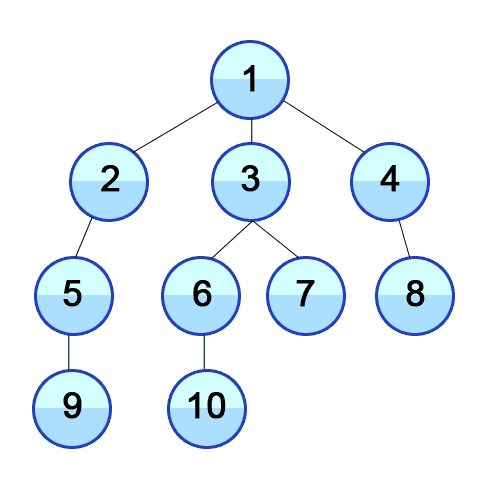
출처 : DFS, Wikimedia Commons
위 그림을 보게 되면 DFS와 BFS의 차이를 확실히 할 수 있다. 언뜻보면 비슷한 두 개의 그래프 탐색 방법은 약간 다른 자료구조를 가지고 알고리즘을 구현할 수 있다. DFS는 stack, BFS는 queue 라는 자료구조를 사용하게 된다.
stack과 queue의 차이점을 간단하게 설명하자면 stack은 가장 마지막에 추가된 자료가 가장 먼저 삭제되는 후입선출(LIFO, Last-In-First-Out)의 구조를 가지고 queue는 가장 먼저 추가된 자료가 가장 먼저 삭제되는 선입선출(FIFO, First-In-First-Out)의 구조를 가진다.
예시를 활용해보자면, DFS에서 1번 노드와 연결된 2, 3, 4 중 2번 노드를 먼저 추가함으로써 2번 노드와 연결된 노드들을 먼저 탐색하게 된다. 반면에 BFS는 1번 노드와 연결된 2, 3, 4를 모두 queue에 추가함으로써 2, 3, 4를 탐색하고 가장 먼저 들어온 2번 노드와 연결된 노드들을 다시 queue 뒤에 추가함으로써 그래프를 전체 탐색하게 된다.
