[논문]Graph Convolutional Neural Networks for Web-Scale Recommender Systems(2018, Rex Ying)
📄 Graph Convolutional Neural Networks for Web-Scale Recommender Systems(2018, Rex Ying)
0. 포스팅 개요
부스트캠프와 투빅스 스터디에서 그래프(Graph)에 대해 배우게 되면서 그래프 분야에 관심을 가지게 되었습니다. 특히 관계가 표현되는 그래프의 특징이 추천 시스템에서 충분히 활용될 수 있기 때문에 그래프 기반 추천 모델에 대해서 공부해보면 좋을 것 같다고 생각하게 되었습니다.
사실, 이전 와인 추천 프로젝트에서 오늘 리뷰하는 PinSAGE를 적용해보게 되었는데 본인이 담당했던 부분이 아니었기에 해당 모델에 대해서 깊이 이해하지는 못했었습니다. 그래서 이번 기회에 논문을 읽으면서 정리해보려고 합니다.
PinSAGE에서는 추천을 위해 표현되는 유저-아이템과의 관계가 아닌 아이템-아이템과의 관계를 기반(아이템과 아이템과의 관계를 정의하는 것은 유저이긴 합니다.)으로 추천에 활용하게 됩니다. 추가적으로 해당 Github에서 코드로 구현된 PinSAGE 모델에 대해 자세히 알아볼 수 있습니다.
ABSTRACT
-
그래프 구조 기반 데이터에서 최근 딥러닝의 발전은 추천 시스템 성능에서 SOTA의 성능을 보이고 있습니다만, 여전히 수백만개의 아이템과 수백만명의 유저를 활용해서 실제 모델을 배포하는 것은 도전 과제로 남아 있다고 합니다.
-
그래프 구조와 노드 feature information까지 노드 임베딩에 사용한 Graph convolution 연산과 효율적인 random walk를 적용한 GCN 알고리즘 기반인 Pinsage를 Pinterest에 실제 적용하고 발전시킨 내용에 대해서 다루고자 합니다.
-
GCN 알고리즘의 접근법과 비교해보았을 때, random walk 부분을 보다 효율적이게 발전시킬 수 있었고 보다 강건한 모델을 만드는 것에 성공했습니다.
-
Pinterst의 Pinsage를 학습함에 있어, 그래프 상의 약 75억개의 example과 pin과 board로 이루어진 3억개의 노드 그리고 18억개의 엣지를 활용했습니다.
1. INTRODUCTION
-
딥러닝 기술은 이미지, 텍스트, 그리고 개별적인 유저의 저차원 임베딩을 유용하게 학습할 수 있기에 추천 시스템 분야에서 점차 중요한 부분으로 자리잡고 있습니다.
-
딥러닝 모델로 학습된 representations(수치로 표현된 무언가로 이해했습니다. 아이템 임베딩 혹은 유저 임베딩과 같은..)은 보충 자료?로 활용할 수 있으며, collaborative filtering 같은 전통적인 추천 알고리즘을 대체할 수도 있습니다.
- 예를 들어, 아이템 임베딩은 아이템-아이템 추천과 같은 어떠한 컨텐츠를 추천해주는 과정과 같은 다양한 추천 과제에서 사용될 수 있습니다.
-
특히 최근에는, 소셜 그래프 혹은 유저-아이템의 상호작용 그래프와 같은 그래프 기반 구조의 데이터에서 딥러닝을 활용한 추천 시스템이 상당한 발전을 보이고 있습니다.
-
추천 시스템에서 그래프 분야가 발전하게 된 저명한 이유로는 당연히 Graph Convolutional Networks, GCNs라고 알려진 딥러닝 구조 덕분일 것입니다.
-
GCN의 핵심 아이디어는 인공신경망을 활용해서 그래프의 지역적 이웃의 정보를 반복적으로 집계하여 학습하는 것입니다.
-
content-based 딥러닝 모델과는 달리, GCN은 content 정보뿐만 아니라 그래프 구조 또한 사용하게 됩니다. (그래프 구조는 유저와 아이템과의 상호작용이 반영되어 있는 구조일 것입니다.)
-
그러나 GCN 기반 방법들은 성능은 굉장히 좋지만 매우 많은 유저와 아이템을 학습하는 과정에 사용하기 때문에 아직까지는 실제 product하는 단계에 있어서 약간의 시행착오를 겪고 있습니다.
-
-
Pinsage의 기존 GCN 기반 방법들과의 차이점을 2가지 측면에서 살펴볼 수 있습니다.
-
먼저 fundamental advancements in scalability 측면에서의 improvements는 다음과 같습니다.
- On-the-fly convolutions
- 기존 GCN 알고리즘이 전체 그래프 Laplacian의 feature를 graph convolution 연산하는 것과 달리, Pinsage는 효율적으로 노드 주변의 이웃을 샘플링하여 지역적으로 convolution 연산을 적용하고 샘플링된 이웃을 바탕으로 computation graph를 구성합니다.
- 노드의 모든 이웃을 활용하는 것 대신에, 샘플링을 통해 노드를 선별함으로써 보다 효율적인 계산 방식을 적용할 수 있었다고 이해했습니다.
- Producer-consumer minibatch construction
- 효과적인 SGD 학습을 위해 pre-defined computation graphs를 GPU-bound Tensorflow Model에 태운 뒤, GPU를 최대한 활용한 미니배치 구조를 학습 과정에 반영했다고 합니다.
- Efficient MapReduce inference
- GCN으로 노드의 임베딩 벡터를 추출해내는 과정에서 분산 처리 파이프라인을 구축하여 반복적인 과정을 최소화했습니다.
- On-the-fly convolutions
-
다음은 new training techniques and algorithmic innovations 측면으로, improvements는 다음과 같습니다.
-
해당 측면의 improvements가 노드 임베딩 벡터의 representation의 질을 높일 수 있었고 추천 측면에서의 성공적인 성능에 많은 부분 기여했다고 합니다.
-
Constructing convolutions via random walks
- 앞서 언급했듯이, 모든 이웃 노드를 활용하는 것은 많은 계산량을 요구함으로 샘플링을 진행하였는데, 랜덤 샘플링이 아닌 short random walks 라는 새로운 테크닉으로 이웃 노드를 샘플링 했습니다.
- 해당 방법으로 노드의 importance score를 구해 집계하는 과정에서 활용할 수 있었습니다.
-
Importance pooling
- 그래프 연산에서 핵심 요소는 이웃 노드의 feature information을 집계하는 것입니다.
- short random walks 기법에 의거한 node feature 집계 방법으로 평가 방법의 46%의 성능 향상을 이끌었습니다.(해당 테크닉에 대한 자세한 방법은 추후에 나올 듯 합니다..)
-
Curriculum training
- 학습 과정에 있어 harder-and-harder(더 어려운..?) 학습 데이터를 제공하는 curriculum training 방식으로 12%의 성능 향상을 가져왔습니다.(curriculum 이라고 말하는 것이, 보통 curriculum, 교육과정이 쉬운 단원부터 어려운 단원을 다루는 것(harder-and-harder)을 의미한다고 이해했습니다.)
-
-
유저와 온라인 상에 존재하는 visual bookmarks인 pins과의 상호작용에 대한 인기있는 컨텐츠와 개인화된 컨텐츠를 Pinterest의 여러 추천 문제를 위해 PinSage를 활용했다고 합니다.
-
유저는 유사한 pins을 모을 수 있는 boards에 pins을 수집할 수도 있으며, 그렇기 때문에 Pinterest는 유저와 pin과의 그래프 관계가 세계적으로 가장 큰 규모로 형성될 수 있었습니다.
2. RELATED WORK
3. METHOD
-
이번 목차에서는 학습된 PinSage 모델을 사용해서 효율적이게 임베딩을 뽑아낸 MapReduce 파이프라인 뿐만 아니라 PinSage의 모델 구조 및 학습에 대한 구체적인 테크닉에 대해서 알아보겠습니다.
-
PinSage의 주요 동력은 localized graph convolution 입니다.
-
노드의 임베딩을 생성하기 위해서, 노드의 지역적 이웃의 feature information을 집계하기 위한 복수의 convolutional modules를 적용하게 됩니다.
-
각 module은 small graph neighborhood 로부터 어떻게 정보를 집계할지 학습하게 되며, 다수의 module을 stacking함으로써 지역적인 정보를 얻을 수 있습니다.(smaal graph neighborhood가 정확히 어떤 의미로 사용되었는지 이해하지는 못했습니다만, 해당 노드의 이웃들만을 말하기에, 전체 graph보다 small 하다고 표현한 것 같습니다.)
-
중요한 것은 이러한 convolutional module의 파라미터는 모든 노드에 걸쳐 공유되기 때문에 입력되는 그래프 크기에 따라 parameter complexity이 독립적이게 됩니다.
-
3.1 Problem Setup
-
Pinterest는 (content discovery application) 컨텐츠를 찾는 어플리케이션으로 유저와 pin이 상호작용하게 됩니다.(pin은 컨텐츠에 대한 이미지라고 이해하면 좋을 것 같습니다.)
-
유저는 pin 들을 boards 라는 공간에 보관 및 저장할 수 있으며, boards 는 유저가 생각하기에 연관이 있는 pin 들을 카테고리별로 구분할 수 있습니다.
-
Pinterest 에는 20억개의 pins 과 10억개의 boards 그리고 180억개의 엣지라는 그래프가 존재한다고 볼 수 있습니다.
-
결론적으로 가장 주요 과제는, 유저에게 pin 을 추천해주기 위해서 광범위한 그래프를 기반으로 high-quality embeddings or representations of pins 을 뽑아내는 것입니다.
-
임베딩을 학습하기 위해서, pin을 의미하는 I 노드 집합과 board를 의미하는 C 노드 집합이 따로 존재하는 bipartite graph(이분 그래프) 로 Pinterest 그래프를 이해할 수 있습니다.
-
그렇다면 여기서 약간의 의문이 발생하게 되는데, 보통 추천 문제에 있어서는 유저와 아이템의 관계가 그래프로 표현되지만, Pinterest 그래프에서는 아이템의 집합을 의미하는 I 와 유저를 정의하는 Context 혹은 Collections의 집합인 C로 표현되고 있습니다. (boards는 pin의 집합인데, boards가 유저를 정의하는 context로 표현한 것은 pin이 모이는 board에 유저 개인의 성향이 반영되기 때문인지... 정확히 이해하지 못했습니다..)
-
노드의 정보를 의미하는 node feature 와 그래프 정보를 기반으로 high-quality embeddings 을 추출하는 것이 PinSage의 목표이며, nearest neighbor lookup과 같은 유사 기반 알고리즘을 통해서 추천 후보군을 형성하는 것 혹은 모델의 feature 형태로 활용될 수 있습니다.
-
본 논문에서는 전체 그래프의 노드 집합을 라고 할 수 있으며, 사실 pin과 board를 명확하게 구분하지는 않습니다.
-
3.2 Model Architecture

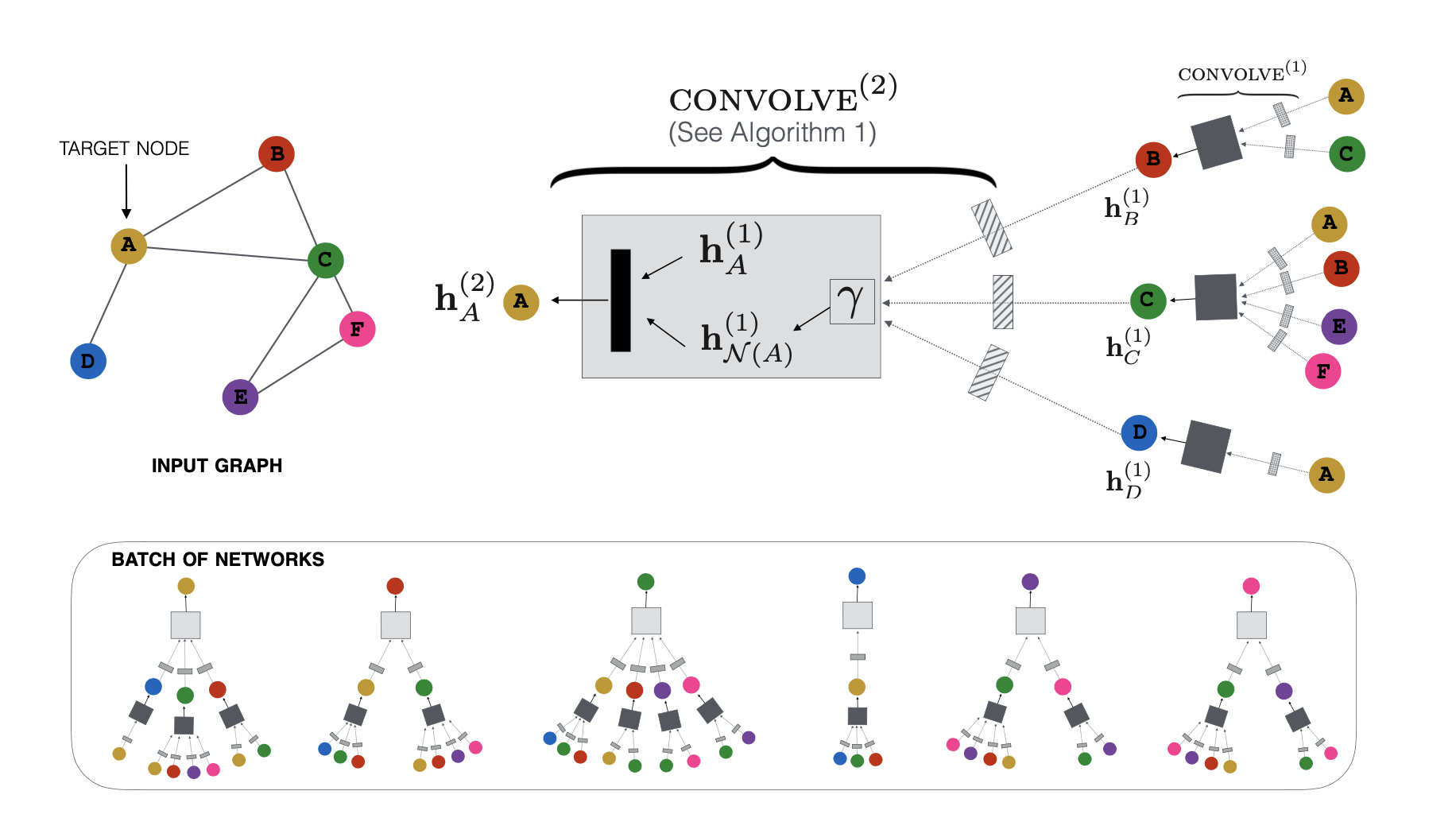
Forward propagation algorithm - Algorithm 1
-
노드 에 대한 임베딩 를 얻기 위해서 노드의 feature information과 해당 노드의 이웃들을 활용하게 됩니다.
-
notation은 다음과 같습니다.
- : 노드 의 이웃 노드 집합 를 정의하기 위한
- : 노드 의 이웃 노드 집합으로부터 집계된 임베딩 벡터(이웃 노드 정보)
- : 의 원소 노드의 information (node feature로 이해했습니다.)
- : aggregation function, 집계 함수로 element-wise
mean or weighted sum 등이 될 수 있다고 합니다. - : 노드 의 임베딩 벡터
-
임베딩 벡터 가 출력되는 과정은 다음과 같으며, GraphSage랑 굉장히 유사하다고 볼 수 있었습니다.
- (1) 이웃 노드의 집합인 의 node feature를 집계하는 과정()을 거치고 dense layer를 활용해서 를 출력함
- (2) 노드 의 임베딩 와 이웃 노드 정보인 를 CONCAT 후 다시 dense layer를 활용해서 업데이트된 를 출력함
- (2-1) 와 를 결합하는 과정에서 average(평균)보다 concat이 보다 성능 향상에 좋았다고 합니다.
- (3) normalization 과정을 가지며, 학습에 보다 안정적이며 nomalized vector로 가까운 vector를 찾는 것에 보다 효율적이라고 합니다.
Importance-based neighborhoods
-
사실 위 과정은 많은 블로그에서도 언급하듯이, GraphSage와 많은 차이를 보이고 있지는 않습니다만 PinSage가 가지는 혁신적인 접근법은 바로 노드 의 이웃 노드 집합 를 정의하기 위한 Importance-based neighborhoods 방법에 있습니다.
-
이전 GCN 알고리즘은 k-hop(k차 연결)인 모든 노드를 이웃으로 활용하는 구조였지만 PinSage의 경우에는 해당 노드 에 가장 많은 영향을 미치는 T개의 노드를 선별하여 활용하는 구조를 가지게 됩니다.
- (1) 노드 에서 random walk를 시뮬레이션 하게 됩니다.
- (2) random walk를 통해 방문하게 되는 노드의 방문 횟수(visit count)를 기록하고 L1-normalized 하여 계산합니다.
- (3) 노드 에 대한 이웃 노드의 normalized visit count 모두 구한 후 상위 T개를 이웃으로 정의하게 됩니다.
-
Importance-based neighborhoods 접근법에는 2가지 장점이 있습니다.
-
모든 노드가 아닌 선별된 노드만의 node feature를 집계하는 것은 학습 과정에서 메모리를 충분히 절약할 수 있습니다.
-
노드의 임베딩을 형성하는 과정에서 이웃 노드의 중요성을 고려했다는 점입니다.
-
-
추가적으로, Algorithm 1 에서 이웃 노드의 node feature를 집계하는 과정에서 Importance-based neighborhoods에서 계산한 normalized visit count를 가중치로 활용할 수도 있으며, 이를 importance pooling 이라고 합니다.
Stacking convolutions
-
Algorithm 1(convolve) 과정을 거치게 되면 항상 노드 에 대한 임베딩 를 얻을 수 있게 되며, 해당 과정을 stack함으로써 노드 에 대한 이웃 정보를 보다 얻을 수 있습니다.
-
여러 층의 layer가 쌓이게 되면, 처음 input은 node feature 자체를 의미하게 되며, 각 k th-layer의 input은 k-1 th-layer의 output이 될 것입니다.
-
이는 각 layer에 존재하는 파라미터 (Q, q, W, w)가 layer 안에서는 공유되며 layer 간데는 독립적임을 의미합니다.

- Algorithm 2 는 미니배치 조건에서 여러 층의 convolution 계산이 이뤄지는 과정을 보여줍니다.
3.3 Model Training
-
PinSage의 loss function은 Max-margin Ranking Loss를 기반으로 학습되었습니다.
-
item query 에 대한 좋은 추천 후보 쌍을 라고 표현하게 될 때, PinSage의 파라미터는 이미 라벨링된 를 가지고 아이템 와 아이템 가 가까워지도록 최적 학습한다고 할 수 있습니다.
Loss Function
-
위에서 언급한 Max-margin Raniking Loss의 기본적인 아이디어는 로 이미 라벨링된 아이템에 맞춰 학습하는 것이지만, 반대로 가깝지 않은(관계가 보다 적은으로 이해해도 될 것 같습니다.) 쌍에 대한 학습도 당연히 필요하게 됩니다.
-
그렇기 때문에, 기본적으로 positive example에 대해서는 두 임베딩 벡터의 내적을 크게 하고 negative example에 대해서는 두 임베딩 벡터의 내적을 작게 함으로써 학습이 진행됩니다.
- 는 아이템 의 negative example에 대한 분포를 의미하며 는 margin hyper-parameter라고 하지만, 여기서는 negative example을 선별하는 과정에 대해서는 뒤에서 언급하게 됩니다.
Multi-GPU training with large minibatches
Producer-consumer minibatch construction
Sampling negative items
-
large batch sizes에서 학습의 효율성을 개선하기 위해서, 각 미니배치에서 모든 학습 example이 공유할 수 있는 500개의 negative items를 선별했습니다.
-
하지만 공통적인 negative item 500개가 positive item의 내적보다 당연히 작기 때문에 너무 '쉽다'라고 표현할 수 있으며, 학습에 있어 충분한 '해결책(resolution)이라고 할 수 없다고 합니다.
-
'즉, 미니배치에 따른 positive item 모두 다른 분포와 패턴을 가지고 있기 때문에 배치 학습에 있어 모두 학습이 가능하지만 배치에 따른 negative item은 몇 억개 중 겨우 500개의 분포와 패턴밖에 존재하지 않기 때문에 충분히 negative에 대한 특징이 학습되지 않을 것이다' 라고 이해했습니다..ㅎㅎ
-
그러므로 학습에 있어 가장 negative item을 뽑아내야하는데, 이러한 문제를 해결하기 위해서 아이템 에 대한 아이템을 PageRank score를 통해서 가장 negative한(hard한) 아이템을 뽑아내는 것입니다.

-
이렇게 hard negative item을 활용하게 된다면 학습 과정에서 2배의 Epoch을 거쳐야 하는 Curriculumn Training 방식을 통해 수렴하게 됩니다.
-
1 Epoch에서는 hard negative item을 사용하지 않고 loss를 빠르게 줄일 수 있는 파라미터를 찾게 되고 2 Epoch에서 hard negative item을 활용함으로써 positive와 negative 아이템의 특징의 차이를 학습하게 됩니다.
