[부스트캠프 AI Tech][Week03]Day 14 - Recurrent Neural Networks
Week03 - DL Basic
[Day 14] - Recurrent Neural Networks
1. RNN 기초
이번 시간에는 Sequence 데이터의 개념과 특징 그리고 Sequence 데이터를 처리하기 위한 알고리즘인 RNN, Recurrent Neural Networks에 대해서 배우게 됩니다. RNN 알고리즘의 역전파 방법인 BPTT와 기울기 소실 문제에 대해서도 다루게 됩니다.
Sequence 데이터만이 가지는 특징과 종류, 처리 방법 그리고 이를 위한 RNN의 구조를 CNN 혹은 MLP와 비교하여 차이점을 이해하는 것이 중요합니다. RNN의 역전파 방법인 BPTT(Back Propagation Through Time)를 수식적으로 이해하고 해당 과정에서 발생하는 기울기 소실 문제와 이에 대한 해결책을 중심으로 RNN의 기본적인 개념을 배울 수 있습니다.
1) Sequence data
Sequence 라는 영어 단어의 의미를 보면 '(일련의) 연속적인 사건들[행동들/숫자들 등]'이라는 것을 확인할 수 있습니다. 그렇다면 Sequence data 는 시간 순서에 따라 나열된 데이터를 의미한다고 볼 수 있습니다. sequence의 특징을 가지고 있는 데이터로는 소리, 문자열과 언어, 주가 등을 예시로 들 수 있습니다. 시퀀스 데이터는 독립항등분포(i.i.d) 가정을 통상적으로 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 되는 것을 유념해야합니다.
❗️독립항등분포(i.i.d., independent and identically distributed): 각각의 확률변수가 상호독립적이며, 모두 동일한 확률분포를 가지고 있을 때, 독립항등분포를 따른다고 합니다.
2) Sequence data 처리
시퀀스 데이터를 처리하기 위해서는 데이터와 데이터 사이에 존재하는 순서라는 개념을 먼저 인지해야 합니다. 그렇다면 이전 시퀀스의 정보를 가지고, 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부확률을 이용할 수 있습니다.
시퀀스 데이터에서는 베이즈 법칙을 통해서 부터 까지의 결합분포를 에 대한 조건부확률 분포와 부터 까지 결합확률을 곱해주어 구할 수 있습니다. 이러한 조건부확률을 반복적으로 분해하게 된다면, 부터 까지의 데이터로 를 추론하는 조건부확률의 곱으로 나타낼 수 있습니다. 왜냐하면 또한 를 구한 방법으로 똑같이 구할 수 있기 때문입니다.

즉, 시퀀스 데이터는 순서의 개념이 도입되기 때문에, 이전 시퀀스의 정보라는 조건으로 앞으로 발생할 데이터의 확률분포를 다룰 수 있음을 알 수 있습니다. 하지만 해당 과정이 과거 정보를 무조건적으로 모두 필요하거나 활용한다는 의미는 아닙니다. 또한 시퀀스 데이터를 다루기 위해서는 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요합니다.
고정된 길이 T만큼의 시퀀스만 사용하는 경우 AR(Autoregressive Model), 자기회귀모델이라고 부르며, 바로 이전 정보를 제외한 나머지 정보들을 다른 잠재변수로() 인코딩해서 활용하는 모델을 잠재 AR 모델이라고 합니다. 자귀회귀모델에서 를 인코딩하는 방법을 해결하기 위해서 적용된 알고리즘이 RNN입니다. Neural network를 통해서 직전 이전의 정보들을 인코딩하여 현재 정보를 예측하는 모델 구조를 구축할 수도 있습니다.

3) Recurrent Neural Network
RNN에서 라는 잠재변수를 인코딩하는 과정은 MLP의 layer에서 발생하는 계산 과정과 유사합니다.
MLP에서는 입력 데이터 X는 가중치 행렬의 곱과 bias의 합으로 선형결합이 이뤄지고, 활성화 함수를 거쳐 잠재변수로 거듭나게 됩니다. 다음 layer에서는 해당 잠재변수에 반복적인 선형결합과 활성화 함수를 통해 최종 출력이 나오게 되는데, 곱해지는 가중치 행렬 과 는 시퀀스와 상관없이 불변인 행렬로 이해할 수 있습니다.
하지만 RNN에서는 과거의 정보를 안에 담기 위해서 이 전 잠재변수()로 부터 정보를 전달받게 되는 새로운 가중치 행렬인 가 필요하게 됩니다. 즉, 이전 잠재변수가 다음 잠재변수를 생성하는 과정에서 결합되기 때문에 정보를 어느정도 보존된 상태에서 새로운 출력을 구성할 수 있다는 개념입니다.
RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산됩니다. 출력과 다음 시점에서의 잠재변수의 gradient vector가 입력되면서 학습이 이뤄집니다.

4) Back Propagation Through Time
BPTT를 통해 RNN의 가중치행렬의 미분을 계산해보면 아래와 같이 미분의 곱으로 이루어진 항이 계산됩니다. 최종적으로 나오게 되는 i시점부터 t시점까지의 모든 잠재변수에 대한 미분값의 곱은 시퀀스 길이가 길어질수록 불안정할 가능성이 높습니다.

항들의 값이 1보다 크게 되면 미분값이 매우 커지게 되고, 1보다 작게 되면 미분값이 매우 작게 됩니다. 그렇기 때문에 일반적인 BPTT를 모든 시점에 적용하게 되면 RNN의 학습이 불안정하게 됩니다. 특히 기울기 소실 문제인 gradient vanishing problem이 발생하게 되면 과거 시점에 대한 예측이 거의 불가하기 때문에 미분값의 범위를 정해 계산하는 truncated BPTT 방법이 있습니다. 하지만 truncated BPTT 또한 gradient vanishing을 무조건적으로 해결할 수 있는 것은 아니기 때문에 LSTM, GRU 등과 같은 새로운 개념들이 제안되었습니다.

2. Sequential Models - RNN
Sequential data는 시작과 끝이라는 시점 혹은 순서의 특징을 가지고 있으며 주식 혹은 언어 데이터 시퀀스 데이터에 해당합니다. 이러한 Sequential data에 적용하기 위한 Sequential model의 정의와 종류에 대해 배우게 됩니다. 딥러닝에서는 시퀀스 데이터 중 자연어처리 분야가 굉장히 활발하게 발전하고 있으며 시퀀스 데이터와 자연어처리 과제에서 굉장히 기본적으로 사용되는 알고리즘인 RNN의 정의와 RNN 기반 모델의 종류에 대해 알아보겟습니다.
1) Sequential Model
sequential model의 가장 기본적인 목적은 데이터가 순차적으로 입력되었을 때, 다음 입력이 무엇일지 예측하는 것입니다. 해당 모델의 가장 큰 특징으로는 특정 시점의 예측을 위한 조건이 시점에 따라 매번 달라진다는 것입니다. 위에서 를 위한 조건부확률의 결합과 의 조건부확률의 결합이 다를 수 밖에 없는 것이 이를 의미합니다.
- Autoregressive model: 모든 시점의 조건으로 과거 시점의 데이터의 개수를 정하는 모델
- Markov model: 특정 시점의 이전 시점의 정보만을 활용하는 모델
- Latent autogressive model: 과거의 정보를 함축하여 잠재변수를 생성하여 정보를 활용하는 모델
2) Recurrent Neural Network 개요
RNN의 기본적인 구조는 MLP와 거의 유사합니다. 하지만 위에서 살펴본 Sequential data를 다루기 위해서 자기 자신의 정보를 한번 더 참고하는 Recurrent(재순환) 구조가 추가되었다고 볼 수 있습니다.
재순환 구조가 적용된 모델을 시계열적으로 풀게되면 다음과 같은 형태의 구조를 가지게 됩니다. 해당 구조는 단순하게 바라보면 사실상 입력이 굉장히 많은 fully connected layer로 표현된 것이라 이해할 수 있습니다. 하지만 많은 입력이 모두 독립적이라기보다는 연결되어 있는, sequential한, 순차적인 개념으로 생각하면 좋습니다.

3) Long-term dependencies
RNN의 가장 대표적인 단점으로 long-term dependecy가 있습니다. 처음이라는 시점과 마지막이라는 시점이 존재하는 시퀀스 데이터에서는 정보를 최대한 보존하기 위해서 특정 시점에서 그 시점 이전의 데이터를 모두 활용하는 것이 가장 좋다고 생각할 수 있습니다.
하지만 시퀀스 데이터의 크기가 크게 되면, 후반 시점과 초기 시점의 간격이 차이나게 되면서 초기 시점의 정보를 잃어버려 활용할 수 없게 되는 것이 long-term dependecy problem 입니다.

4) LSTM, Long Short Term Memory
RNN 학습되는 과정은 다음과 같습니다. 모든 시점은 이 전 시점의 잠재변수로 생성된 를 활용해서 다시 새로운 잠재변수를 생성하게 됩니다. 이런 과정으로 계산된 잠재변수가 계속해서 중첩되는 구조가 되면서 가중치를 곱하고 활성화 함수를 통과하게 되면서 정보의 가치를 잃어버릴 수 있게 됩니다.
이 때, 활성화 함수에 따라서 정보가 너무 압축되거나 폭발하는 vanishing / exploding gradient 문제가 발생하게 됩니다.

기본 RNN의 위와 같은 문제를 해결하기 위해서 다양한 컴포넌트를 추가함으로써 Long-term dependecy를 어느정도 해결할 수 있었습니다. LSTM의 전체적인 구조는 RNN의 일반적인 구조와 동일하지만 입력과 출력이 이뤄지는 과정에서 다양한 컴포넌트가 해당 문제를 해결하기 위해 움직입니다.

특정 시점에서 입력된 데이터가 출력되고 다음 시점으로 전달되는 과정을 보다 구체적으로 보면 다음과 같습니다. 해당 모델을 언어 모델로 가정한다면 시점에서의 입력 데이터는 단어(토큰)가 될 가능성이 높습니다. 보통 언어 모델에서는 해당 입력 데이터는 임베딩 데이터가 입력되게 됩니다. 출력 데이터는 잠재변수, hidden state이며 3개의 gate를 통해서 다음 입력에서 이 전의 정보를 활용하고자 합니다. LSTM 구조에 존재하는 다양한 컴포넌트의 개념을 알아보도록 하겠습니다.

- Forget Gate: Decide which information to throw away
- 어떤 정보를 버릴지 선택하는 구간
- 이전의 hidden state와 새로운 입력인 x가 forget gate로 들어가게 됨
- 시그모이드를 통해서 항상 0~1 사이의 값만을 가지게 되며 cell state 정보와 결합하게 됨

- Input Gate: Decide which information to store in the cell state
- 어떤 정보를 살릴지 선택하는 구간
- 이전 hidden state와 입력 x를 결합하여 각각 와 를 형성함
- 각각 생성된 두 개의 값을 결합하여 어떠한 정보를 업데이트할지 정하게 됨

- Update cell: Update the cell state
- forget gate의 결과와 이전 hidden state와의 결합과 input gate의 결과를 더해 새로운 cell state를 업데이트함

- Output Gate: Make output using the updated cell state
- 마지막으로 새롭게 생성된 cell state 정보와 output gate의 정보를 결합함으로써 해당 시점의 최종 hidden state를 출력하게 됨
- Output gate를 생략한 과정이 GRU임

3. Sequential Models - Transformer
Sequential model의 한계점과 이를 해결하기 위해 Transformer 라는 새로운 구조가 등장하기도 했습니다. Transformer 구조는 등장 이후부터 자연어처리 분야뿐만 아니라 굉장히 다양한 분야에서 활용되고 있습니다. 이번에는 Transformer의 구조 중 Encoder와 Multi Head Attention의 구조와 개념에 대해 알아보겠습니다.
1) Transformer 개요
Sequential data는 순서라는 개념이 존재함으로써 생략, 뒤바뀜 등의 특징을 가지고 있으며 이러한 특징을 고려해서 sequential modeling을 하기에는 분명 다른 데이터들보다 어려움이 존재합니다. 예를 들어, 의사소통함에 있어 사람들은 백퍼센트 문법을 지키지 않는 경우가 대부분이며 대명사 혹은 문맥에 의한 생략이 정말 많습니다. 모델은 데이터 그 자체를 보기 때문에 이러한 특징을 보이는 sequential data를 모델링하기에 한계점이 존재합니다.
RNN 혹은 LSTM과 같은 모델로는 이러한 문제를 해결하는 것에 어려움을 보였으며, Transformer는 이러한 문제를 보다 해결할 수 있는 구조를 가지고 있습니다. Transformer가 처음 소개 된 Attention is All You Need(NIPS, 2017) 논문에서는 Transformer에 대한 첫 소개를 다음과 같이 말합니다.
Tranformer is the first sequence transduction model based entirely on attention
Transformer 구조는 이 전 정보가 반복적으로 혹은 재귀적으로 입력되는 과정인 RNN의 구조와 다른 Attention 매커니즘을 활용하여 sequential data를 다룬 새로운 구조를 선보이게 됩니다.
해당 논문에서는 Transformer 구조를 기계번역 문제에 초점을 맞추고 있지만 Transformer는 sequential data를 처리하고 인코딩하는 방법으로 기계번역 뿐만 아니라 이미지 classification, detection, visual transformer 등의 분야에서 다양하게 활용되고 있습니다.

2) Transformer 구조
Transformer는 기본적으로 encoder로 입력되는 문장을 decoder로 출력되는 문장으로 바꾸는 기계번역 알고리즘에 해당합니다.

Transformer는 RNN 알고리즘처럼 입력 데이터 N번의 재귀적 순환이 존재하는 것이 아닌, 한번에 입력 데이터 N개를 인코딩하는 과정인 self-attention 구조를 거칩니다. Transformer에 대한 구조를 보다 정확하게 이해하기 위해서는 구조 내부에서 발생하는 3가지 과정에 대한 이해가 필요합니다.
- N개의 데이터가 순환 구조를 가지지 않고 인코딩 되는 과정에 대한 이해
- encoder와 decoder간 어떤 상호작용이 발생하는 지에 대한 이해
- decoder가 generation 하는 과정에 대한 이해
먼저, 입력 데이터로 3개의 단어가 self-attention layer를 통과하게 됩니다. self-attention layer를 통과하게 되면 각 단어(토큰)는 입력된 벡터에 따라 매핑되는 벡터가 출력되는데, 이 때의 벡터는 단순 MLP의 결과라기 보다는, 입력 데이터 간의 정보가 반영된 벡터라고 볼 수 있습니다.

3) self-attention
그렇다면 어떤 과정으로 입력 데이터 간의 정보가 반영된 벡터가 매핑되는지 알아보겠습니다. 다음과 같은 문장이 예시로 주어졌을 때, 컴퓨터가 it 단어를 그 자체로 인식하기 보다는 문장에서 다른 단어와의 관계 정보가 포함된 의미를 파악하는 것이 self-attention의 핵심이며 문장 번역에서 보다 효과적이라고 할 수 있습니다.
self-attention 과정을 거치게 된다면, it 과 다른 단어와의 관계 정보가 포함된 벡터를 출력하게 되며, 여기서는 animal 단어와 굉장히 밀접한 관계를 가지고 있음을 확인할 수 있습니다.
The animal didn't cross the street beacuase it was too tired.

새로운 벡터를 출력하기 위해서 self-attention 구조는 기본적으로 Query, Key, Value 라는 3가지 벡터를 만들어내게 됩니다. 각 입력 데이터마다 Q, K, V 벡터가 생성되고 3개의 벡터의 계산을 통해 하나의 임베딩 벡터가 출력됩니다.

n_batch, d_K, d_V = 3,128,256 # n_batch는 입력 데이터 N개
n_Q, n_K, n_V = 30,50,50
Q = torch.rand(n_batch,n_Q,d_K) # Q 벡터는 각 데이터 30 * 128 차원의 벡터로 표현
K = torch.rand(n_batch,n_K,d_K) # K 벡터는 각 데이터 50 * 128 차원의 벡터로 표현
V = torch.rand(n_batch,n_V,d_V) # V 벡터는 각 데이터 50 * 256 차원의 벡터로 표현결과적으로 attention 매커니즘은 입력 데이터의 Q, K, V 벡터를 통해 score 벡터를 생성해줍니다.
- score 벡터를 계산하기 위해서 인코딩을 하고자하는 단어의 Q 벡터와 나머지 단어의 K 벡터를 내적함으로써 관계도 혹은 유사도를 구할 수 있습니다.

- Q 벡터와 나머지 모든 데이터의 K 벡터가 내적된 상태로 값이 개별로 존재하게 된다면, hyperparameter로 정해진 차원의 루트로 정규화(Normalize)해줍니다. 그 이후에 score 벡터를 softmax를 취함으로써 sum to 1이 되게 만들어주면서 다른 단어와의 interaction을 의미하는 스칼라로 표현할 수 있습니다.

- 정규화, softmax를 거친 score 값을 각 V 벡터를 곱하고 더해서(weighted-sum) 하나의 스칼라로 나오는 것이 해당 단어의 최종 attention value라고 할 수 있습니다.

- 최종적으로 self-attetnion으로 벡터를 표현하고자하는 입력 데이터의 attention value를 다음과 같이 정리할 수 있습니다.

Transformer가 보다 효과적으로 sequential data를 임베딩하여 표현할 수 있는 이유는 다음과 같습니다. 이미지를 MLP 혹은 CNN을 통해 벡터로 표현하고자 할 때, 신경망 구조가 동일하다면, 동일한 이미지에서는 동일한 출력이 나오게 됩니다.
하지만 Transformer의 경우에는 같은 단어 혹은 토큰임에도 주변 단어와 데이터에 따라 출력값이 달라지기 때문에 보다 풍부한 표현이 가능하다고 볼 수 있습니다.
4) Multi-head attention
Multi-head attention은 말그대로 attention 과정을 여러번 거치는 것입니다. 하나의 sequential data 셋에 Q, K, V 벡터를 한번만 생성하는 attention 과정을 한번만 거치는 것이 아닌 N번 수행함으로써 Q, K, V 벡터도 N번 생성되는 것을 의미합니다.
Multi-head attention을 함으로써 서로 다른 N개의 임베딩된 벡터(결과)를 얻을 수 있게 되며 concat 후 weight matrix를 내적함으로써 최종 attention values를 구할 수 있게 됩니다,

4) Positional encoding
positional encoding이 필요한 이유는 sequential data가 가지는 순차적인 특징을 attention 과정에 반영하기 위해서 입니다. 사실 attention 과정은 순서에 독립적이기 때문에 [a, b, c, d, e]와 [b, c, d, e, a]가 동일한 출력값을 가지게 됩니다.
최종 결과인 각 단어의 attention value에 positional한 정보를 반영하기 위해서 pre-defiend 된 벡터를 look-up 하는 형식으로 추가해줍니다.

5) Decoder
Transformer 구조에서 Encoder 부분의 입력부터 발생하는 여러 부분에 대해서 알아보았습니다. 마지막 내가 번역하고자 하는 문장 부분을 담당하고 있는 Decoder의 개념 또한 Encoder의 개념과 크게 차이가 나지는 않습니다.
Transformer 구조에서는 먼저 Encoder에서 시퀀스 데이터가 입력되면서 전체 과정이 시작됩니다. 입력된 시퀀스 데이터들은 Encoder의 출력으로 attention 벡터들인 적절한 k, v로 변환됩니다. 각 데이터들이 k, v라는 벡터로 representative되었다면, Decoder의 'Encoder-Decoder attention layer'에서 decoder가 입력 데이터의 적절한 위치에 집중할 수 있도록 도와줍니다.
Decoder에서는 각 스텝마다 하나의 element를 출력하게 됩니다. element란 간단하게 말하면, 기계 번역에서는 하나의 토큰을 의미한다고 볼 수 있습니다. 해당 Decoder 과정은 문장의 끝을 의미하는 special 기호인 < end of sequence >를 마주칠 때까지 반복됩니다.
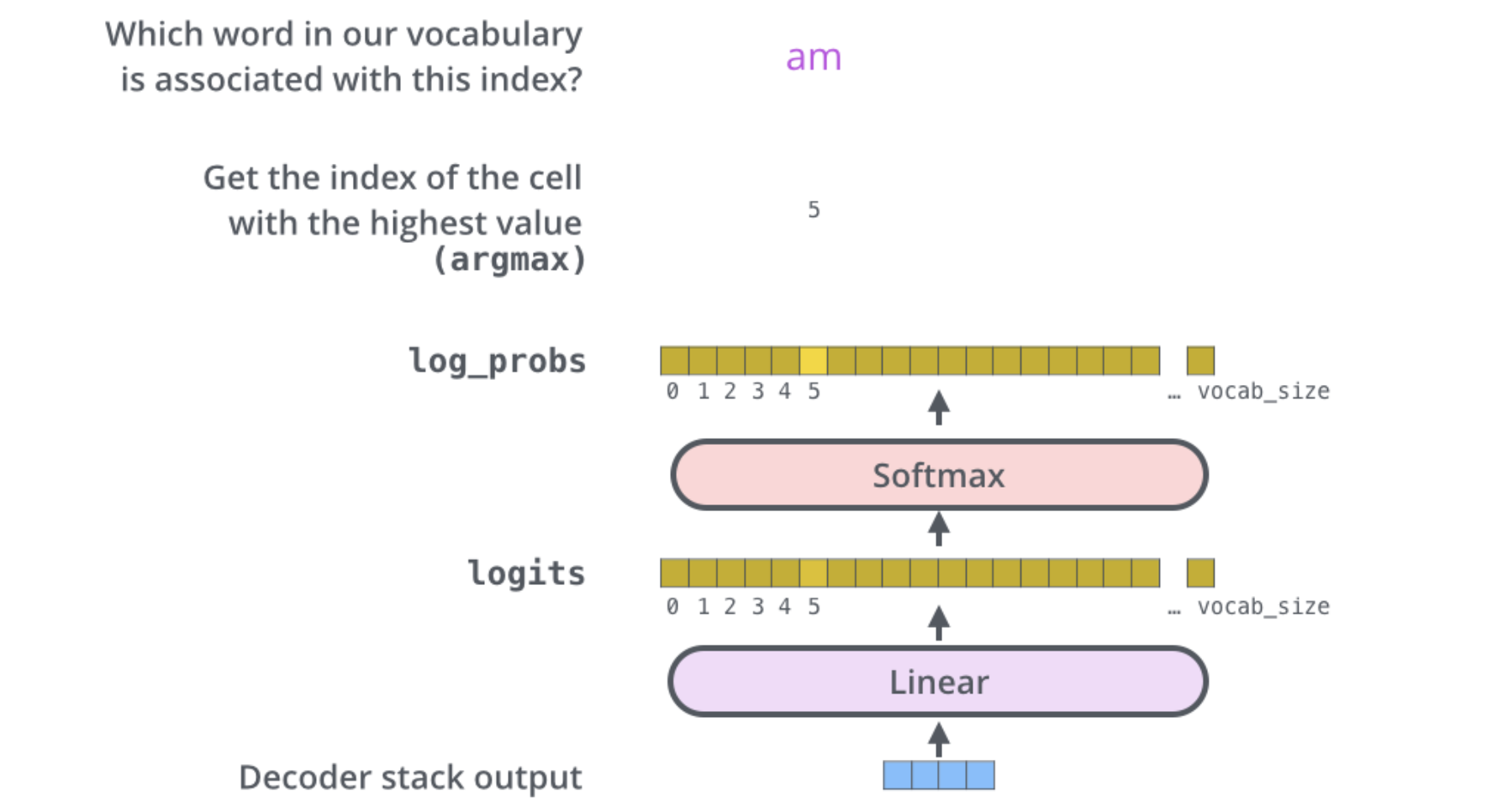
6) Linear layer & Softmax layer
결국 우리는 Encoder와 Decoder의 attention 과정을 거친 벡터를 가지고 최종 결과물로 단어를 예측해야합니다. 사실 Linear layer와 Softmax layer는 Multi-label classification이라고 봐도 무방하다고 생각합니다.
vocab size 만큼의 softmax logit을 계산해줌으로써, 가장 높은 확률로 분류된 label을 최종 output으로 결정하게 됩니다.

잘 보고 갑니다!