웹 페이지를 화면을 통해서 우리 눈으로 보기 위해서는 내부적으로 어떤 일이 일어날까요?
우리는 뉴스 등을 보기 위해서 네이버 웹 페이지에 접속한다고 가정해보겠습니다. 이는 네이버에서 웹 서비스를 제공하기 위해 개발자가 구현한 코드(프로그램)를, 어떠한 구조를 통해 접근할 수 있도록 해놨고 우리는 이를 웹브라우저(chrome, firefox 등)를 통해서 요청(Request)하고 받아와서(응답, Response) 실행시키고 네이버 메인의 뉴스 등이 다양한 컨텐츠를 볼 수 있게 되는 것을 말합니다.
https://www.naver.com/ 을 브라우저 창에 검색 했다고 생각하며 시작해보겠습니다.
요청(Request)과 응답(Response)
개발자에 의해 작성된 웹 페이지를 사용자의 기기(PC, 모바일 등)에서 실행하기 위해, 코드을 요청하고 이를 다운로드 받는 것을 말합니다.
그런데, 누구한테 요청하나요?
이런 역할을 하는 담당자는 바로 서버(server)인데요, 크게 두 가지로 볼 수 있습니다.
- DNS(Domain Name System) 서버
- 코드(프로그램)를 올려놓은 곳에서 이를 꺼내서 반납해주는 서버
http://www.naver.com 를 웹 브라우저에서 검색하면
- host(도메인)인
www.naver.com을 DNS 서버에 요청하여 실제 주소 값인 IP 주소를 받아옵니다. (네이버의 경우223.130.200.104:443이 값이네요!) - 이 주소로 루트 요청(프로토콜(https), host(223.130.200.104:443), /)을 합니다. (
https://223.130.200.104:443/) - 네이버 서버는, 페이지 로드에 필요한 리소스(2진수로 된 html/css 코드, JS 파일, 폰트, 사진 등)를 사용자가 실행한 웹 브라우저에 응답합니다.
- 웹 브라우저는 이를 다운로드 합니다.
실제로 chrome의 network 탭을 열어서 확인해보면 요청과 동시에 아래와 같이 수많은 리소스가 다운로드 되는 것을 보실 수 있습니다.
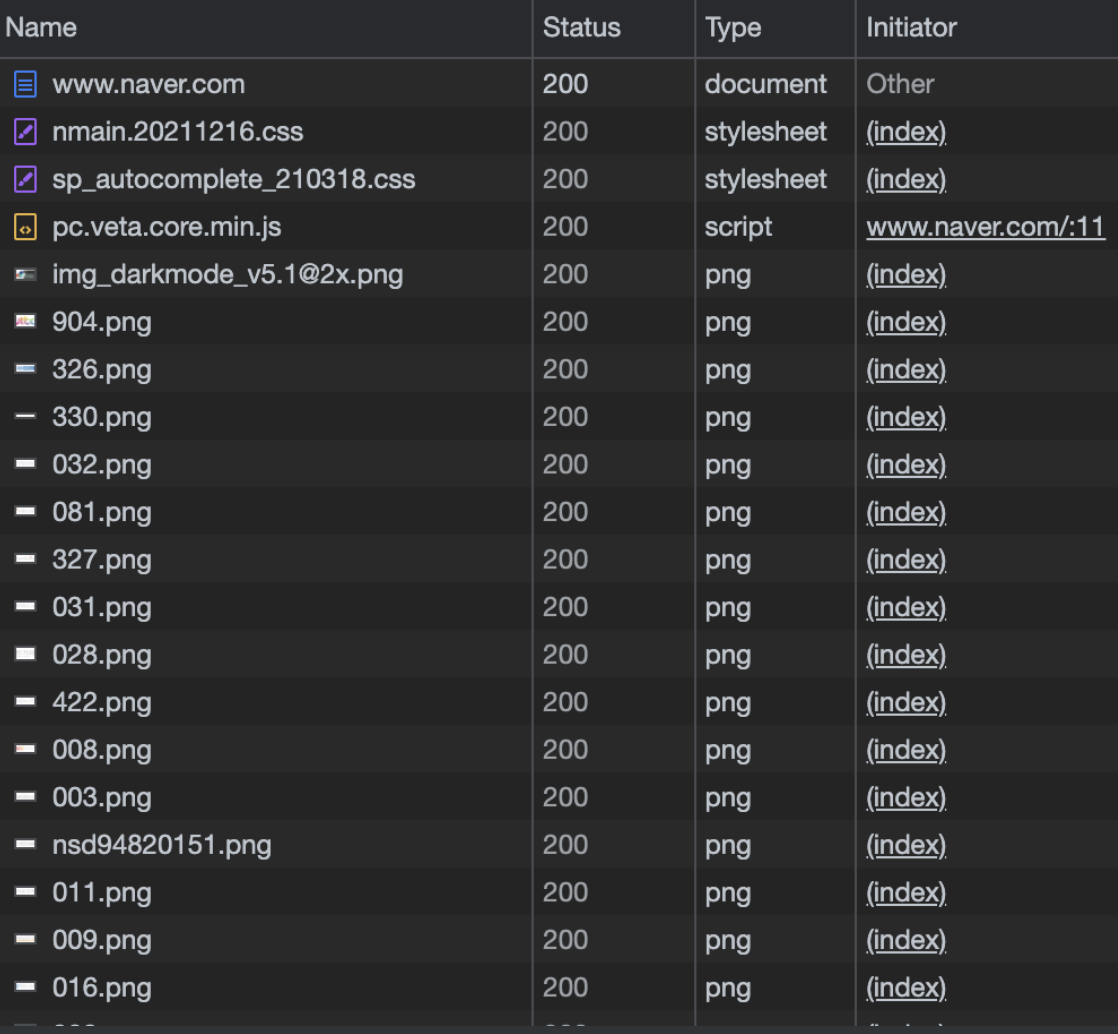
그런데 여기서 궁금한 점은 https://www.naver.com/ 이렇게 검색 했는데, 이 안에서 어떤 html 파일이 로드 돼서 표시 되는 건지 궁금할 수 있는데요, 사실은 https://www.naver.com/ → www.naver.com/index.html 로 암묵적으로 변환돼서 요청됩니다.
다시 말해서, 프로젝트 루트에 있는 index.html을 던져주는 것이죠!
HTML parsing and DOM 생성(브라우저 렌더링 엔진)
이렇게 해서 웹 브라우저가 index.html를 전달 받으면, 바이트(2진수)형태로 되어 있는 되어 있는 html을 전달 받는데요, 응답 header를 통해 전달된 meta 태그의 charset attribute에 의해 지정된 인코딩 방식을 기준으로 문자열로 변환합니다.
아래의 경우는 utf-8 방식으로 인코딩 되겠죠!
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
</head>
...
</html>
이렇게 인코딩된 순수 문자열을 웹 브라우저가 알아볼 수 있는 자료구조 형태인 DOM(Document Object Model)으로 파싱합니다.
이 과정을 간략히 살펴보자면, 아래와 같습니다.
-
문자열을 문법적 의미를 갖는 최소 단위인 토큰(token)으로 분해
-
각 토큰을 객체로 변환하여 노드(node)를 생성(이는 DOM을 구성하는 기본 요소가 됩니다.)
문서 노드, 요소 노드, 어트리뷰트 노드, 텍스트 노드가 생성
-
이 노드로 html의 계층 구조를 반영한 트리 형태의 자료구조인 DOM을 생성
CSS parsing and CSSOM 생성(브라우저 렌더링 엔진)
html 파싱을 진행하다보면, link, style 태그를 발견하게 됩니다. 이 때 렌더링 엔진은 html 파싱을 멈추고 CSSOM을 생성하기 위해서 위에서 살펴본 html 파싱 과정과 같은 절차를 밟게 됩니다.
바이트 css
⬇️ (인코딩)
순수 문자열 css
⬇️ (토큰화 & 객체화)
노드
⬇️ (계층구조화)
CSSOM이렇게 완성된 CSSOM을 잠깐 놔두고 브라우저 렌더링 엔진은 다시 html 파싱을 하러 갑니다.
Javascript Parsing and 실행(Javascript 엔진)
html 파싱 중 <script> 태그를 발견하게 되면 브라우저의 렌더링 엔진은 DOM 생성 동작을 즉시 멈추고 자바스크립트 엔진에게 제어권을 넘겨줍니다. 멈추는 이유는 javascript 코드에 의해서 DOM트리를 변경 시킬 수 있기 때문입니다.
먼저 코드를 최소한의 문법적 단위인 토큰(token)으로 변환하고 이를 문법적인 의미를 담고 있는 트리인 추상적인 구문 트리(Abstract Syntax Tree)로 바꿉니다. 이를 기반으로 JS Engine은 기계코드로 변환합니다.
> AST는 어떤 모습일까요?
예를 들어서 아래와 같은 자바스크립트 소스코드의 경우를 보겠습니다.
const Words = "hello world :)"자바스크립트의 소스코드를 문법적인 의미를 갖는 트리구조의 AST(Abstract Syntax Tree)로 바꿀 수 있는 https://astexplorer.net/ 에서는 테스트 해본 결과는 아래와 같습니다.

type으로 변수, 함수, 블록 등을 구분하여 문법적인 정보를 표시하는 것을 볼 수 있습니다.
다음은 자바스크립트의 파싱 과정을 한눈에 볼 수 있는 그림입니다.
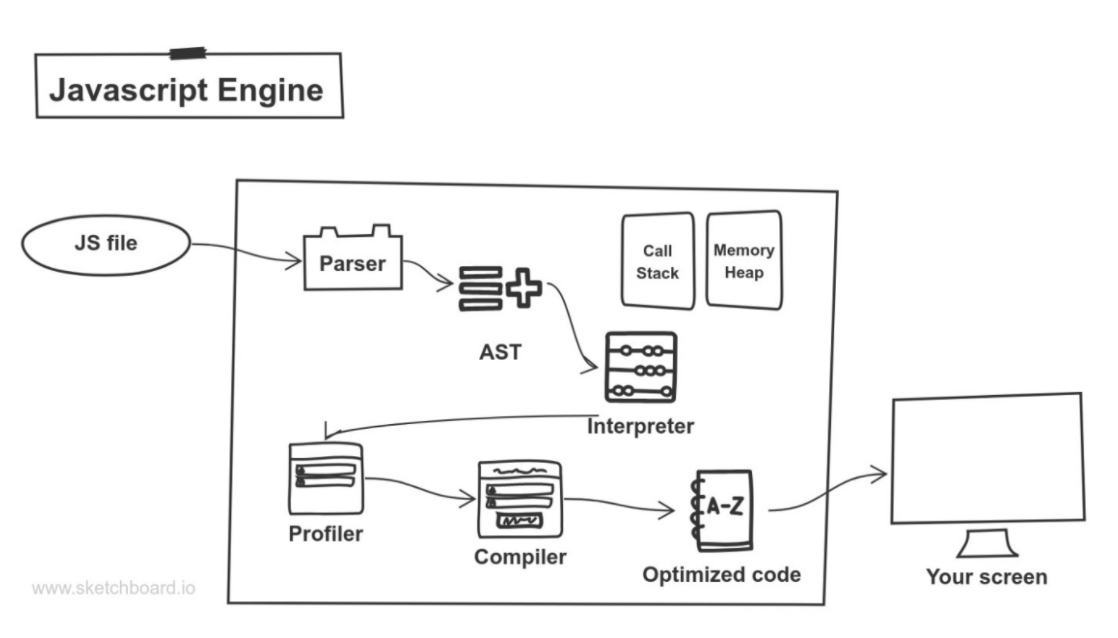
Render Tree 생성(브라우저 렌더링 엔진)
렌더트리(Render Tree)는 렌더링을 위한 트리 자료구조입니다. 즉, 화면에 렌더링 될 노드로만 구성 되어있습니다. 컨텐츠를 설명하기 위한 문서 객체 트리(DOM)와 이 문서에 적용 되어야 하는 스타일 규칙이 담긴 트리(CSSOM)를 병합하여 만들어집니다.
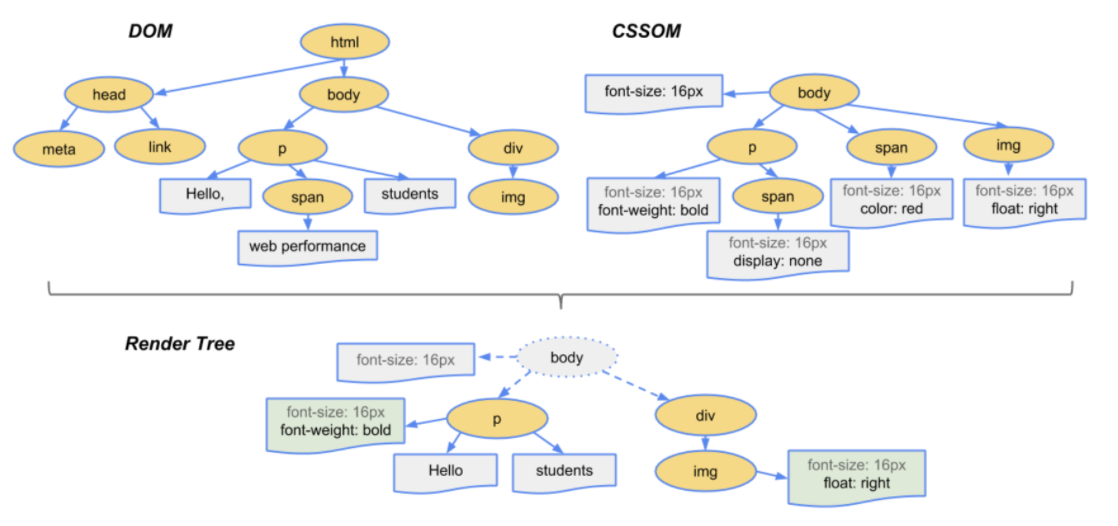
렌더 트리의 대략적인 생성 과정은 다음과 같습니다.
- DOM 트리의 루트에서 순회를 시작합니다.
- 이 때, script 태그, meta 태그 등 렌더링된 출력에 반영되지 않는 태그는 생략합니다.
- 각 노드에 일치하는 CSSOM 규칙을 찾아 계산하여 적용합니다.
- 루트인 body 부터 시작하는데, 부모의 값을 상속받아서 적용시키게 됩니다.
이렇게 최종적으로 완성된 설계도인 렌더 트리(Render Tree) 바탕으로
- 기기의 뷰포트 내에서 각 노드의 정확한 위치와 크기를 계산하고 (레이아웃, 리플로우)
- 픽셀을 화면에 그려야합니다. (페인팅, 레지스터화)
레이아웃, 리플로우(브라우저 렌더링 엔진)
레이아웃 처리 과정에서는 뷰포트 내에서 각 요소의 정확한 위치와 크기를 정확하게 캡처하는 '상자 모델'이 출력됩니다. 모든 상대적인 측정값은 화면에서 절대적인 픽셀로 변환됩니다.
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>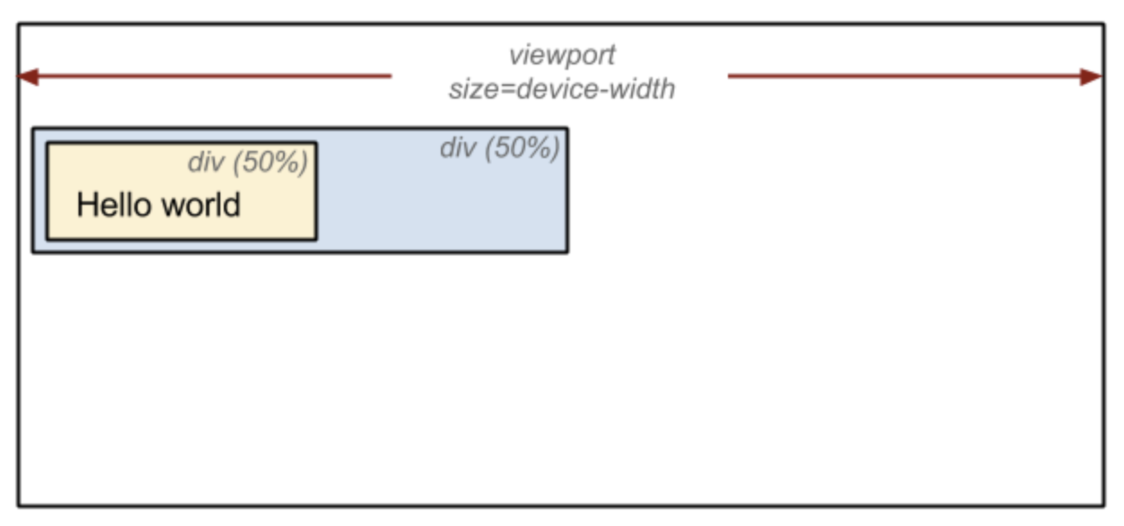
페인팅, 레지스터화(브라우저 렌더링 엔진)
렌더링 트리와 각 노드를 화면의 실제 픽셀로 변환하는 것을 페인팅, 레지스터화 한다고 합니다.
이 과정을 통해서 실제적으로 화면에 그려지며, 보여지게 됩니다.
마치며
여기까지 브라우저에서 페이지를 로딩하여 화면에 UI가 표시되는 과정을 간략하게 살펴보았습니다.
이 과정을 정확하게 알아야 렌더링에 최적화된 코드를 잘 작성(리펙토링) 할 수 있을거라고 생각합니다.
대략적으로 다뤘지만 아래 글을 읽어보시면 더 자세하게 공부하실 수 있습니다. 🙂
Reference
