Key components of deep learning
- data 모델이 학습하기 위한 데이터
- model 데이터를 통해 학습하고자 하는 모델
- loss function 모델의 오차를 정의하는 함수
- algorithm loss를 최소화하는 최적화방법
Linear Neural Networks
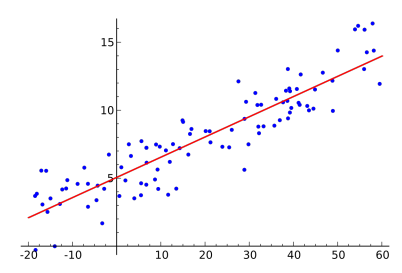
- Data :
- Model :
- Loss :
variables를 optimization 하기 위해
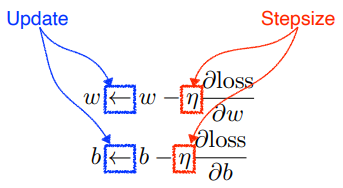
적절한 stepsize를 찾는게 가장 중요한 문제
Multi-Layer Perception(MLP)
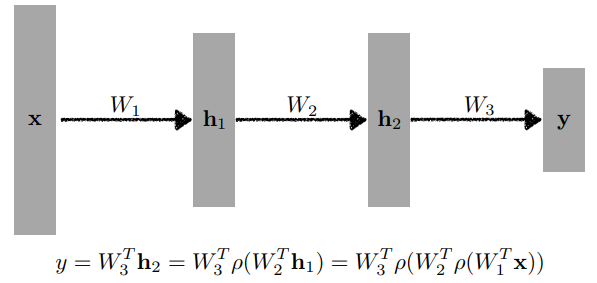
최적화(Optimization)
용어정리
Generalization: 일반화, test error와 training error의 차이, 일반화가 좋다는 것은 성능이 학습 데이터와 비슷하게 나올 것이다.
Under-fitting-Balanced-Over-fitting
Over-fitting: training data에서 잘 동작하지만 test data에서는 잘 동작하지 않음
Cross-validation: 학습 데이터와 validation data를 나누는 것
Bias-variance: 정확도, 일관성
Bias and Variance trade-off:
bias를 줄이면 variance가 높아질 가능성이 크고 그 반대도 성립, 학습 데이터에 noise가 있을 때 bias와 variance를 둘 다 줄이긴 힘들다
Bootstrapping: 학습 데이터에서 여러 개를 뽑아 여러 개의 모델로 training data로 만드는 것
Bagging: Bootstrapping aggregation
boostrapping으로 여러 개의 학습 데이터를 활용
Boosting: 잘 예측되지 않는 학습 데이터에만 잘 동작하는 새로운 모델을 만들고 이러한 모델들을 합침
- Stochastic gradient descent
single sample로부터 gradient를 계산, 업데이트하는 방식 - Mini-batch gradient descent : 대부분의 딥러닝에 활용되는 방식
data의 subset로부터 gradient를 계산, 업데이트하는 방식 - Batch gradient descent
전체 data로 부터 gradient를 계산, 업데이트하는 방식
Batch-size
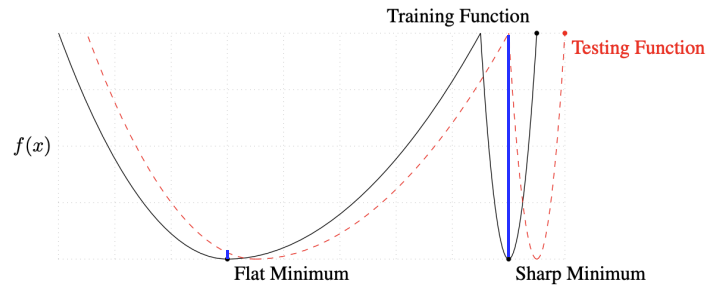
Batch size를 많이 쓰면 sharp minimum에 도달, 적게 쓰면 flat minimum에 도달.
sharp보다 flat minimum에서 training function과 testing function의 차이가 작다.
→ sharp minimum보다 flat minimum에 도달하는게 낫다. batch size를 줄이면 일반적으로 generalization이 좋아진다
Gradient Descent
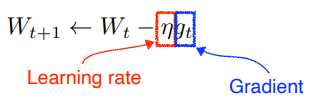
적절한 learning rate를 정하는 것이 중요
Momentum
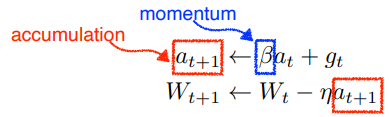
momentum : 각 mini batch에서 이전 mini batch의 정보를 활용해서 업데이트, 한쪽으로 흘러간 gradient direction을 어느 정도 유지 → 큰 변화에도 학습이 잘됨
Nesterov accelerated gradient
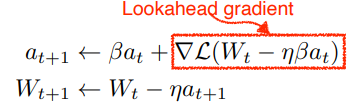
lookahead gradient : momentum에 다음 gradient를 계산한 값을 더해 accumulation, 좀 더 빠르게 convergence 가능
Adagrad
변한정도에 따라 많이 변한 parameters를 더 적게, 적게 변한 parameters를 많이 변화 시키게 함
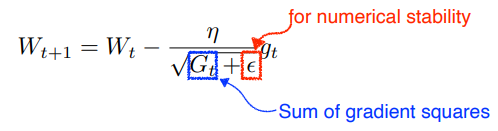
sum of gradient squares : gradient의 변한 정도
→ 분모의 gradient가 점점 커지는데 뒤로 갈수록 W가 업데이트 안됨, 학습이 멈춤
→ Adadelta
Adadelta
window size를 지정하여 범위 안의 gradient squares의 변화
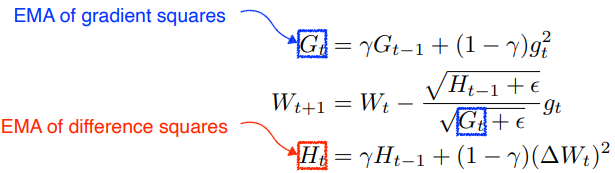
- learning rate가 없음
RMSprop
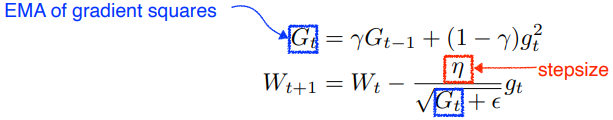
Adam
EMA of gradient squares와 momentum을 같이 활용
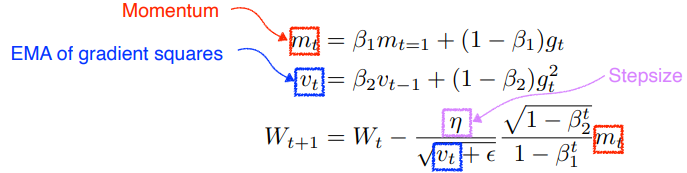
regularization
generalization을 잘 되게 규제(학습에 반대되도록).
학습을 방해함으로 학습 데이터 뿐만 아니라 test data에도 잘 동작하도록 만들어줌.
- Early Stopping : validation data로 training에 활용하지 않은 data 모델의 성능을 측정하여 loss를 계산하고 loss가 커지는 시점에 멈춤
- Parameter norm penalty : parameter가 너무 커지지 않게. 작을 수록 부드러워지고 generalization performance가 높을 것이다라는 가정
- Data augmentation : data가 많을 수록 학습이 잘될 것, 현재 data를 가지고 label이 변환되지 않는 조건 하에 변화시켜 data를 늘리는 것
- Noise robustness : 입력 data weight에 noise를 집어넣음
- Label smoothing : data를 random으로 두 개 뽑아 섞음
- Dropout : random하게 neuron 몇 개를 0으로 바꿈
- Batch normalization, layer norm, instance norm, group norm
출처 - 부스트캠프 AI tech 교육자료
[부스트캠프 AI Tech] Week 3 - Day 1
