무중단 배포 개요
중단 배포를 진행하면 배포 시간동안 사용자는 서비스를 이용하지 못한다. 방끗과 같은 신규 서비스일수록 한 번 불편함을 겪은 사용자는 다시 서비스를 이용하지 않을 것이다. 서비스 이탈을 방지하고 서비스의 고가용성을 위해 팀 프로젝트에서 무중단 배포를 도입했다. 대표적인 무중단 배포 방식을 알아보고 구현 방식을 정리하고자 한다.
1. 롤링 배포
- 트래픽을 점진적으로 구버전에서 새로운 버전으로 옮기는 방식이다.
- 서버를 많이 확보하지 않아도 무중단 배포가 가능하다는 장점이 있다. 하지만 구버전과 신버전의 애플리케이션이 동시에 서비스되기 때문에 호환성 문제가 발생할 수 있다.
2. Blue / Green 방식
- 트래픽을 한 번에 구버전에서 새로운 버전으로 옮기는 방법이다. Blue/Green 배포 전략에서 현재 운영중인 서비스의 환경을 Blue라고 부르고 새롭게 배포할 환경을 Green이라고 부른다.
- 한 번에 트래픽을 제어하기 때문에 호환성 문제가 발생하지 않는다. 그리고 신버전에서 문제가 발생하면 빠르게 롤백할 수 있다는 장점이 있다. 하지만 실제 운영에 필요한 서버 리소스 대비 2배의 리소스를 확보해야 하므로 비용 부담이 크다.
3. 카나리 방식
- 점진적으로 구버전에 대한 트래픽을 새로운 버전으로 옮기는 것은 롤링 배포 방식과 비슷하다. 다만 카나리 배포의 핵심은 새로운 버전에 대한 오류를 조기에 감지하는 것이다.
- 소수 인원에 대해서만 트래픽을 새로운 버전에 옮겨둔 상태에서 서비스를 운영한다. 새로운 버전에 이상이 없다고 판단했을 경우에 모든 트래픽을 신규 버전으로 옮긴다. 이때 트래픽을 새로운 버전으로 옮기는 기준은 정해진 규칙 혹은 랜덤이다.
- 새로운 버전으로 인한 위험을 최소화할 수 있다. 롤링 배포와 마찬가지로 신/구 버전의 애플리케이션이 동시에 존재하므로 호환성 문제가 발생할 수 있다.
✅ 롤링 배포 선택
처음에는 트래픽을 일제히 전환하는 Blue/Green 배포 방식을 고민했다. Blue/Green 배포 방식에서는 2배의 서버 리소스를 확보하는 것이 중요하다. PROD 서버 2대에서 4대로 늘릴 수 있을지 확인하기 위해 예산을 확인해보았는데 예산 금액을 웃돌고 있어 서버를 늘릴 수 없었다.
서버에서 포트를 활용해 2대의 애플리케이션을 추가적으로 띄우는 방식도 고민했다. 해당 방식이 가능한지 확인하기 위해 서버에서 사용중인 리소스를 확인해보았다.

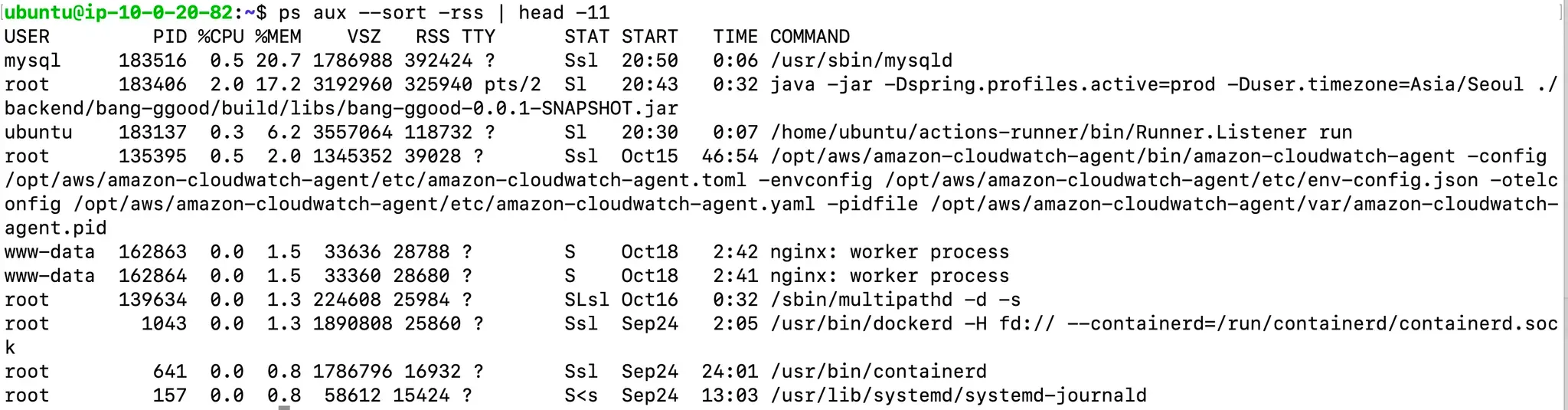
t4g.small 스펙을 사용중이고 메모리는 총 1.8GB 중 1.1GB를 사용중이다. 하나의 애플리케이션이 17% 정도의 메모리를 사용하고 있으므로 한 대를 더 띄워도 문제가 없을 것으로 예상했다. 하지만 t4g.micro 스펙을 사용했을 때 서버가 예기치 않게 자주 종료되었던 경험을 했고 이에 비춰봤을 때 애플리케이션 2대를 띄우는 것이 불안하다고 생각했다. 무중단 배포시 트래픽 증가로 서버 부담이 커질 수 있음을 고려해 최종적으로 롤링 배포 방식을 선택했다.
롤링 배포 구현
전반적인 무중단 배포 플로우는 방끗 팀프로젝트 레포에서 확인 가능하다.
롤링 배포의 핵심은 점진적으로, 하나씩 서버를 배포하는 것이다. CD 스크립트를 활용해 배포 작업을 순차적으로 진행했다. needs 키워드를 활용해 하나 배포를 완료하고 또다른 서버에서 배포를 진행했다.
- CD 스크립트
deploy1: needs: build runs-on: bang-ggood-prod1 #첫 번째 배포 ... deploy2: needs: deploy1 runs-on: bang-ggood-prod2 #두 번째 배포 - 이외 고민해본 방식
-
로드 밸런서 그룹에서 등록 해제 방식을 시도해봤으나 IAM 권한 문제로 불가능했다.
aws elbv2 deregister-targets --target-group-arn <target-group-arn> --targets Id=<instance-id>
-
그런데 한 가지 문제가 있었다. ALB 헬스 체크로 인해 서비스 중단 문제가 발생했다. 헬스 체크 이후 배포를 진행할 때 ALB는 서버를 여전히 헬스 상태로 인식하여 요청을 보내지만 배포 과정에서 서버가 일시적으로 중단되면서 서버 에러가 발생할 가능성이 있다.
배포 진행동안 해당 서버로 요청 보내는 것을 막기 위해 의도적으로 파일을 삽입해 unhealthy 상태로 변경하고 배포 완료 후 파일을 삭제해 healthy 상태로 변경하는 방식(a.k.a 죽은 척하기)으로 해결했다.
배포 단계를 진행하기 전 unhealthy 파일 삽입하고 ALB가 unhealthy 상태를 인식하도록 30초 중단한다.
- CD 스크립트
# unhealthy 파일 삽입 - name: Create unhealth_flag file run: echo "unhealth" | sudo tee /etc/nginx/sites-available/unhealth_flag.txt > /dev/null # ALB가 unhealthy 상태를 인식하도록 30초 중단 - name: Sleep for 30 seconds to be unhealthy run: sleep 30
nginx 설정 파일은 다음과 같이 수정할 수 있다. unhealth_flag.txt 파일이 있는지 확인하고 있다면 unhealthy한 상태값을 보내야하기 때문에 503을 반환한다. 해당 파일이 존재하지 않으면 배포 중인 상태가 아니므로 실제 헬스 체크를 진행하도록 요청을 전달한다.
- nginx 설정파일
location /health-check { # /unhealth_flag.txt 파일이 존재하면 503 반환 if (-f /etc/nginx/sites-available/unhealth_flag.txt) { add_header Content-Type text/plain; return 503 'Healthcheck failed'; } # 파일이 없으면 @backend_healthcheck로 요청 전달 try_files /etc/nginx/sites-available/unhealth_flag.txt @backend_healthcheck; add_header Content-Type text/plain; } location @backend_healthcheck { # 변경된 요청 경로를 백엔드 서버로 전달 proxy_pass http://localhost:8080; proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; }
이후에는 애플리케이션을 다운시키고 배포를 진행한 후 재시작한다. 이때 다시 ALB가 healthy 상태를 인식하도록 30초 중단하는 것이 중요하다.
- CD 스크립트
# 서버 다운 - name: Turn off the server 8080 if runs run: sudo fuser -k -n tcp 8080 || true # 서버 재시작 - name: Start server run: sudo nohup java -jar -Dspring.profiles.active=prod -Duser.timezone=Asia/Seoul ./backend/bang-ggood/build/libs/*SNAPSHOT.jar > /home/ubuntu/actions-runner/server.log 2>&1 & # unhealthy 파일 삭제 - name: Delete unhealth_flag file run: sudo rm /etc/nginx/sites-available/unhealth_flag.txt # ALB가 healthy 상태를 인식하도록 30초 중단 - name: Sleep for 30 seconds to be healthy run: sleep 30
ALB가 healthy, unhealthy 상태를 인식하기까지 연속적으로 상태를 검사한다. 15초동안 2번 헬스 체크를 진행하는데 이때 한 번이라도 unhealthy하다면 unhealthy라고 인식한다. 따라서 다른 서버에 배포를 진행하기 전 해당 서버가 요청을 받을 수 있도록, healthy한 상태로 인식하도록 30초의 중단타임을 두었다.
정상 임계값 : 비정상 상태의 대상을 정상으로 간주하기까지 필요한 연속적 상태 검사 성공 횟수
비정상 임계값 : 대상을 비정상 상태로 간주하기까지 필요한 연속적인 상태 검사 실패 횟수

마지막으로 무중단 배포 도중 예외가 발생하면 현재는 다음과 같이 해결한다. curl을 사용해 http://localhost:8080/health-check에 GET 요청을 보내고 응답코드가 200이 아니면 스크립트를 종료한다.
- name: Health check
run: |
for i in {1..2}; do
RESPONSE=$(curl -s -w "%{http_code}" -o /dev/null http://localhost:8080/health-check)
echo "Response: $RESPONSE"
if [ "$RESPONSE" -eq 200 ]; then
echo "Health check passed"
exit 0
fi
echo "Waiting for server to be healthy..."
sleep 10
done
echo "Health check failed"
exit 1롤링 배포 적용
ENUM으로 저장하던 데이터(Category, Question)를 테이블로 이동하는 작업을 진행하며 스키마 변경사항이 발생했다. 스키마 변경사항이 있을 때 롤링 배포를 적용해보는 것이 좋은 경험이라고 생각해 팀원과 페어를 진행해 롤링 배포 방식을 고민했다. 총 3단계를 거쳐 배포를 진행했다.

- V1 : 카테고리 ENUM으로 데이터 저장하는 방식
- 데이터베이스에는 카테고리 ENUM을 저장하는 category 필드만 존재하며 이 시점에는 스키마 변경이 적용되지 않고 기존 방식대로 운영한다.
- V2 : 카테고리 ENUM + 카테고리 ID 방식 병행
- 카테고리 ID를 저장하는 새로운 필드 category_id를 생성하고 기존 ENUM 데이터를 ID로 변환하는 작업을 진행한다.
- 카테고리 ENUM과 카테고리 ID 값을 함께 저장하여 호환성을 유지할 수 있도록 코드를 수정해 배포한다.
- V3 : 카테고리 ID 값만 저장
- 코드에서 ENUM 관련 부분은 완전히 제거하고 카테고리 ID값만 사용하는 방식으로 변경해 배포한다.
- category 필드를 삭제한다.
무중단 배포 적용 결과
K6를 활용해 배포 시간동안 계속해서 요청을 보냈고 fail count를 확인해 무중단 배포 결과를 확인했다.
중단 배포
- 서비스 중단 시간 약 22초

무중단 배포
- 서비스 중단 시간 0초
무중단 배포를 알고 계신가요?
무중단 배포 아키텍처와 배포 전략
Blue/Green 무중단 배포
무중단배포 전략과 롤백
