RealMySQL 책을 읽으면서 공부했던 내용들을 적용해보고자 성능테스트를 해보았다.
먼저 대량의 데이터를 생성하여 속도가 지연되는 부분을 확인해보았다.
- 유저 : 100만명
- 지출 목표 : 400만개
- 지출 내역 : 1000만개
- 이모지 : 300만개🧨 문제 상황
API 속도를 측정해보니 눈에 띄게 느린 API가 하나 있었다.
/api/community/expenses?page=0&size=10
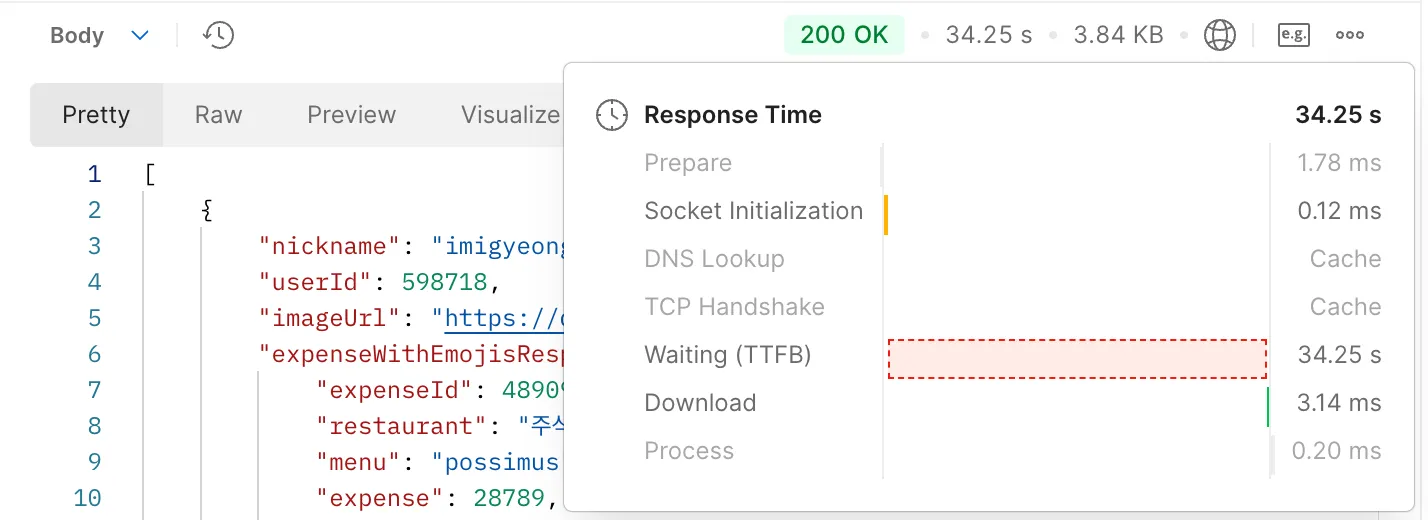
지출 내역을 기반으로 커뮤니티 글을 페이징하여 가져오는 API이다. 응답속도가 34s가 나온 것을 볼 수 있었다.
🤔 원인 파악
가장 메인이 되는 쿼리는 최신순의 지출내역(expense)을 페이징하여 가져오는 쿼리이다. 이때 expense_saving_goal, user 정보를 fetch join으로 함께 가져온다.
옵티마이저가 생성한 SQL 처리 경로인 실행 계획을 보면서 어떤 부분을 개선시켜야할지 알아봤다.
EXPLAIN ANALYZE
SELECT
e1_0.id, e1_0.created_at, e1_0.expense, e1_0.expense_date, e1_0.expense_saving_goal_id,
esg1_0.id, esg1_0.budget, esg1_0.created_at, esg1_0.end_date, esg1_0.modified_at, esg1_0.start_date,
u1_0.id, u1_0.created_at, u1_0.email, u1_0.image_url, u1_0.is_expense_open,
u1_0.login_type, u1_0.modified_at, u1_0.nickname, u1_0.role,
e1_0.memo, e1_0.menu_name, e1_0.modified_at, e1_0.rating, e1_0.restaurant_id, e1_0.restaurant_name
FROM expense e1_0
JOIN expense_saving_goal esg1_0 ON esg1_0.id = e1_0.expense_saving_goal_id
JOIN users u1_0 ON u1_0.id = esg1_0.user_id
ORDER BY e1_0.created_at DESC, e1_0.created_at DESC
LIMIT ?, ?;실행 결과는 다음과 같다.
-> Limit: 10 row(s) (cost=22.3e+6 rows=10) (actual time=28475..28477 rows=10 loops=1)
-> Nested loop inner join (cost=22.3e+6 rows=10.1e+6) (actual time=28475..28477 rows=10 loops=1)
-> Nested loop inner join (cost=11.7e+6 rows=10.1e+6) (actual time=28475..28476 rows=10 loops=1)
-> Sort: e1_0.created_at DESC (cost=1.09e+6 rows=10.1e+6) (actual time=28474..28474 rows=10 loops=1)
-> Table scan on e1_0 (cost=1.09e+6 rows=10.1e+6) (actual time=0.194..4688 rows=10.2e+6 loops=1)
-> Filter: (esg1_0.user_id is not null) (cost=0.956 rows=1) (actual time=0.194..0.194 rows=1 loops=10)
-> Single-row index lookup on esg1_0 using PRIMARY (id = e1_0.expense_saving_goal_id) (cost=0.956 rows=1) (actual time=0.194..0.194 rows=1 loops=10)
-> Single-row index lookup on u1_0 using PRIMARY (id = esg1_0.user_id) (cost=0.95 rows=1) (actual time=0.0993..0.0993 rows=1 loops=10)안쪽에 들여쓰기 된 부분이 먼저 실행되고 같은 레벨이면 상단에 위치한게 먼저 실행된다. 이중에서 실행시간이 급격하게 늘어난 부분을 찾으면 Sort: e1_0.created_at DESC이다.
(actual time=28474..28474 rows=10 loops=1)
반환되는 row는 10개이지만 실행 시점에 1000만개의 데이터를 전부 정렬하기 때문에 속도가 느릴 수 밖에 없다.
💡 인덱스를 사용해 개선
인덱스는 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 생성 시간(created_at)으로 인덱스를 생성하면 미리 정렬 되어 있는 데이터에서 값을 검색하기 때문에 속도가 빨라질 것으로 예상했다.
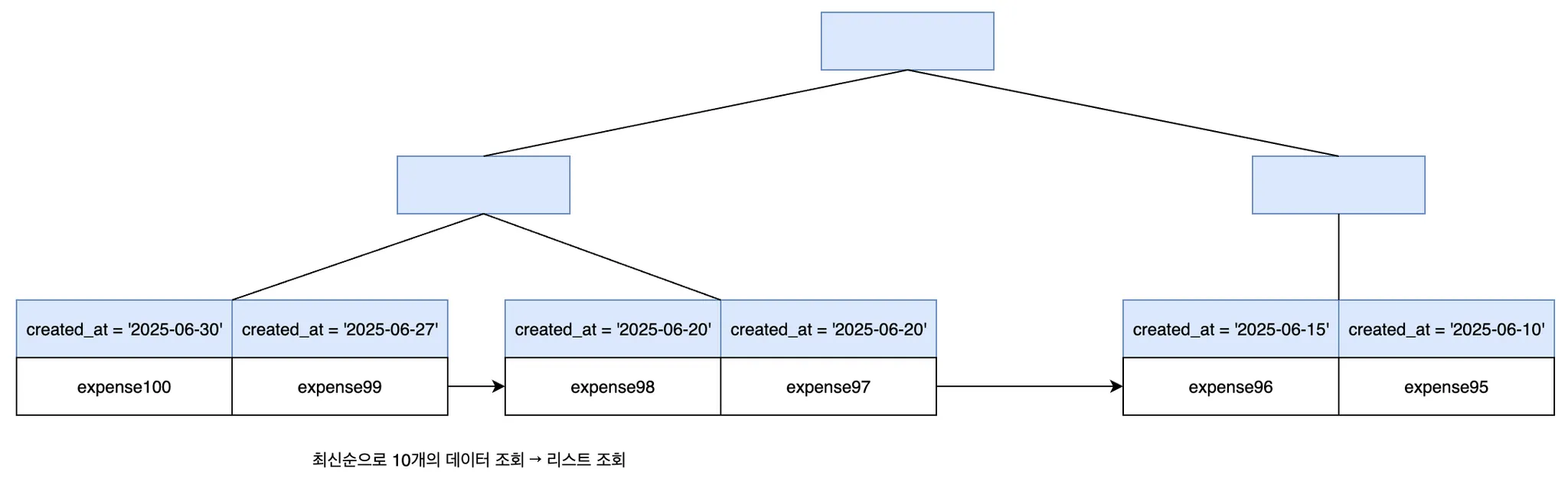
따라서 created_at을 내림차순으로 인덱스를 생성한다.
create index idx_expense_created_at_desc on expense(created_at desc);34s → 6s로 줄기는 했지만 여전히 속도가 너무 느렸다.
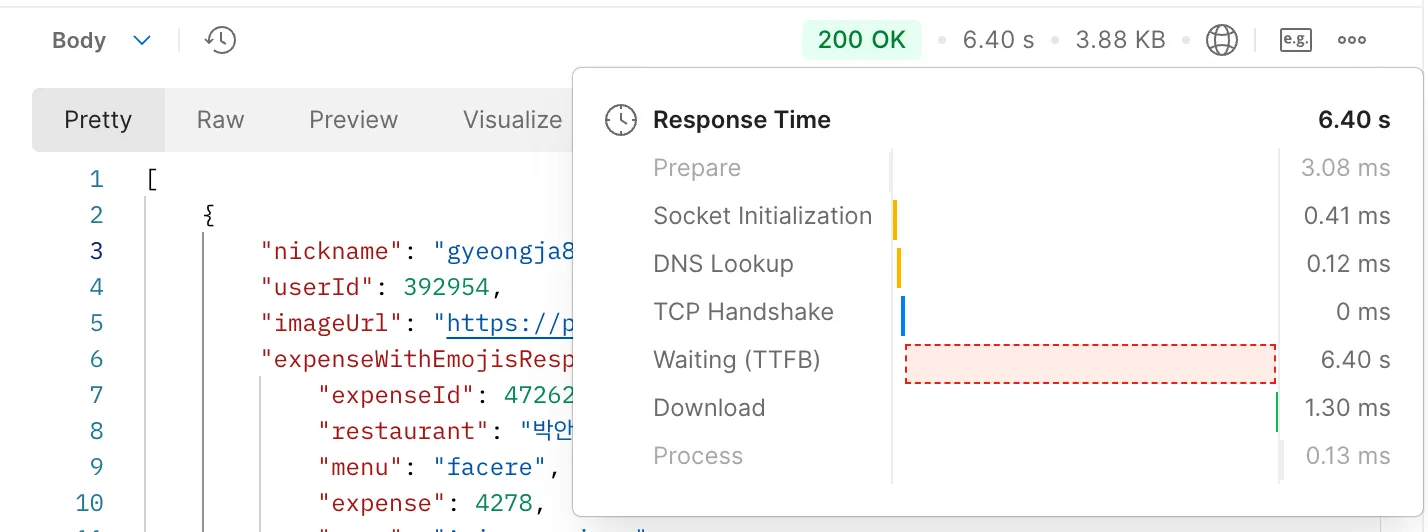
문제는 페이징 기능에서 데이터 조회와 함께 수행되는 count 쿼리였다.
select count(e1_0.id) from expense e1_0 join expense_saving_goal esg1_0 on esg1_0.id=e1_0.expense_saving_goal_id join users u1_0 on u1_0.id=esg1_0.user_idcount 쿼리는 게시글의 번호를 계산하기 위해 사용된다. 하지만 우리 프로젝트에서는 그 다음 페이지가 존재하는지만 알고 있으면 되었기 때문에 사실상 필요없는 기능이었다.
다음과 같이 반환타입을 Page에서 Slice로 바꾸면 count 쿼리가 발생하지 않았다.
@Query("""SELECT e FROM Expense e
JOIN FETCH e.expenseSavingGoal esg
JOIN FETCH esg.user""")
Slice<Expense> findAllWithSavingGoalAndUser(Pageable pageable);이렇게 적용한 후 다시 실행해보면
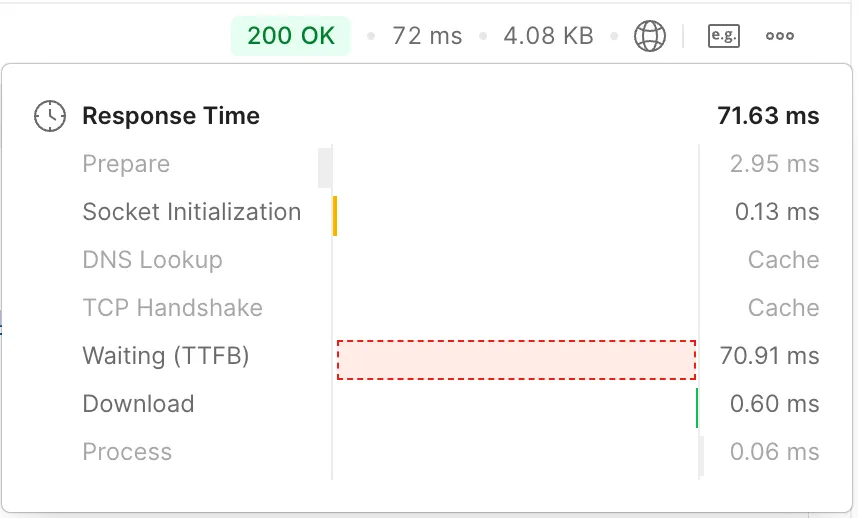
72ms으로 성능 개선을 확인할 수 있다.
하지만 page 숫자가 늘어나면?
page = 10000와 같이 커지면 다시 급속도로 느려지는 것을 확인할 수 있었다.
-> Limit/Offset: 10/100000 row(s) (cost=21.5e+6 rows=10) (actual time=26771..26771 rows=10 loops=1)
-> Nested loop inner join (cost=21.5e+6 rows=10.1e+6) (actual time=26091..26769 rows=100010 loops=1)
-> Nested loop inner join (cost=11.3e+6 rows=10.1e+6) (actual time=26091..26458 rows=100010 loops=1)
-> Sort: e1_0.created_at DESC (cost=1.09e+6 rows=10.1e+6) (actual time=26091..26102 rows=100010 loops=1)
-> Table scan on e1_0 (cost=1.09e+6 rows=10.1e+6) (actual time=1.41..3895 rows=10.2e+6 loops=1)
-> Filter: (esg1_0.user_id is not null) (cost=0.916 rows=1) (actual time=0.00342..0.00348 rows=1 loops=100010)
-> Single-row index lookup on esg1_0 using PRIMARY (id = e1_0.expense_saving_goal_id) (cost=0.916 rows=1) (actual time=0.00336..0.00337 rows=1 loops=100010)
-> Single-row index lookup on u1_0 using PRIMARY (id = esg1_0.user_id) (cost=0.907 rows=1) (actual time=0.00301..0.00303 rows=1 loops=100010)옵티마이저가 인덱스보다 테이블을 전부 sort하는게 더 효율적이라고 판단한다. 실행 속도의 차이는 없는데 인덱스를 사용하면 I/O 작업이 더 많이 발생하기 때문이라고 추측한다.
이 문제는 정책적으로 풀어내려고 했다. 1000페이지가 넘어가는 데이터를 조회하는 유저는 정상적인 유저가 아니라고 판단하여 예외를 던졌다.
마무리
생각지 못한 부분에서 지연이 발생할 수 있기 때문에 대량의 데이터를 만들어보고 직접 성능 테스트를 해보는 것이 중요했다. 또한 인덱스는 생각보다 더 강력한 튜닝 도구라는 것을 배울 수 있었다.

굉장히 인터레스팅하네요 👍