

Intro
프로젝트 내에서 Spring Batch Application을 경험하면서 얻은 것들을 정리했습니다. part1은 batch를 이해하기 위한 기본과 회사에서 어떤 로직으로 batch를 구성했는 지를 간략히 설명하고, part2에서 어노테이션 등의 코드와 프로젝트 내부 flow를 좀 더 자세히 들여다 보려고 합니다.
본문은 존댓말 생략한 점 양해 부탁드립니다.
왜 Batch를?
Batch는 대용량 데이터를 일괄 처리하기 위해 사용된다. Spring Batch는 개발자가 로직에만 집중할 수 있게 잡(Job) 등의 상태 관리, 로깅, 오류 처리 관련해서 다방면으로 지원한다.
프로젝트에 배치가 사용된 이유는 LMS 대시보드 통계를 위해 여러 시스템으로부터 원시데이터를 가져와 가공을 거쳐 LMS DB에 넣어주기 위함이었다.
- 수많은 학생들의 평가/활동 데이터를 가져오는 대용량 처리
- 매일 자정 등에 특정 주기에 정보를 가져와 INSERT/UPDATE 해야 하는 일괄처리
Spring Batch 기본 지식
배치는 REST API 통신 식으로 컨트롤되지 않기 때문에 쓰레드 관리가 필요한 존재인데, Spring Batch에 이 쓰레드 관리를 위임하고 개발/운영자는 애플리케이션을 실행하기만 하면 된다.
처음엔 배치에 대해 아는 것이 없었기 때문에 어디서부터 접근해야 할지 굉장히 막막했었다.
일단 잡과 스텝에 대한 개념을 알아야 했다.
Job
스텝들을 구성하는 상위 요소다. 배치를 처음 실행하면 잡들을 등록하고, 개별 잡들은 잡 파라미터(Job Parameter)들을 받아오고 내부 스텝들이 작업을 한다. 모든 잡이 작업을 마치면 배치가 종료된다.
📌 회사 배치는 A 작업, B 작업, C 순서대로 작업해! 식으로 순서를 부여한 것이 아니라 스케줄러식으로 구성되어 있다.
따라서 배치가 종료된다는 것은 애플리케이션이 종료되는 것이 아니라 그저 할 일들이 다 끝났다는 의미에 더 가깝다.
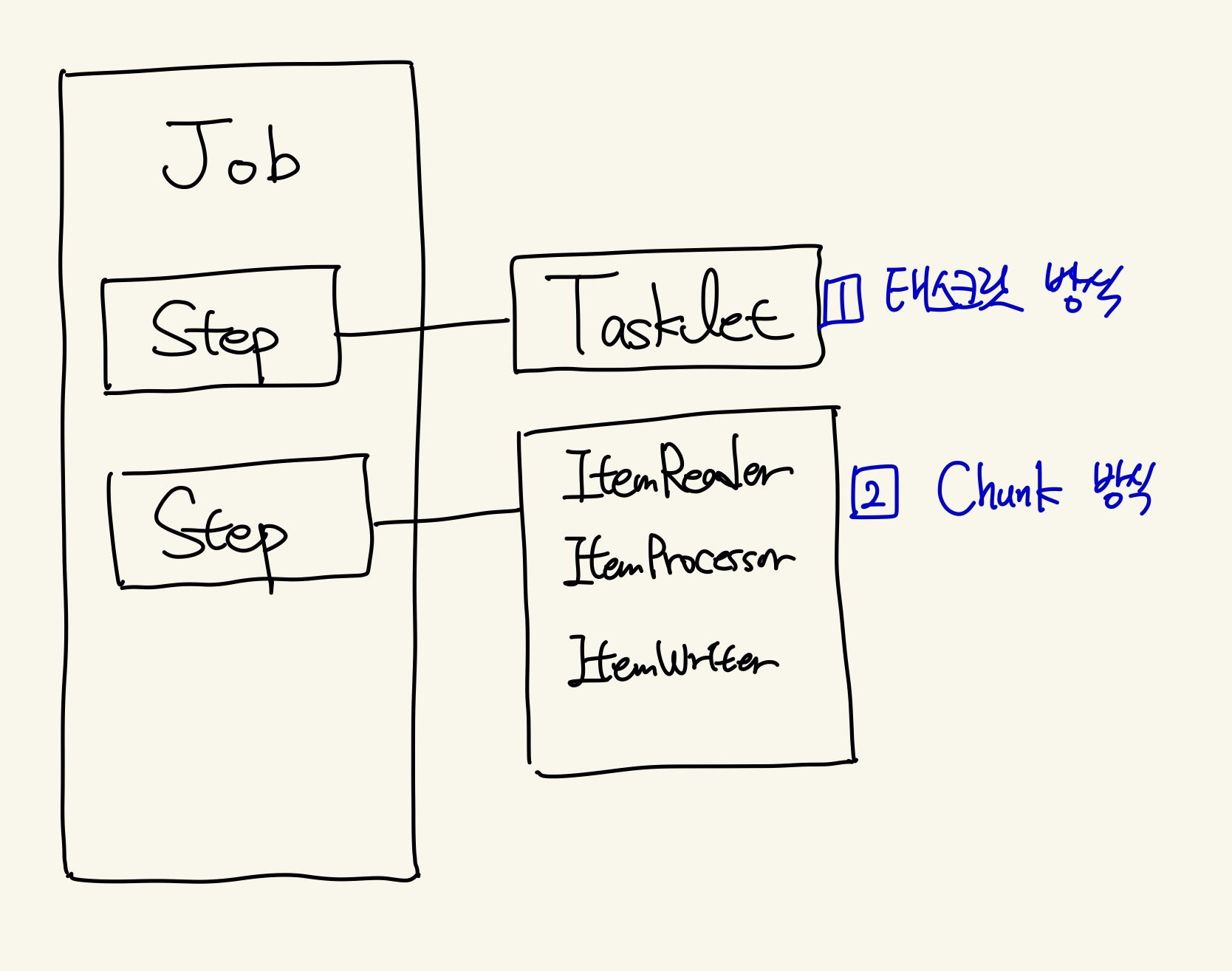
Step
스텝은 잡을 구성하는 독립 작업 단위인데, 태스크릿(tasklet) 방식과 청크(chunk) 방식이 있다. 태스크릿은 더 간단하고, 청크는 복잡한 규모 큰 데이터를 item 개념으로 처리할 수 있다. 우리 배치의 경우 tasklet 기반이다.
DB 테이블 설계
기본으로 Spring에서 인메모리 방식으로 배치 설정 관련 6개의 테이블을 제공한다.
또는 RDBMS와 연동하는 방법이 있는데 우리 회사는 MySql로 연동해서 배치 설정을 관리했다.
- 배치 설정 테이블 (6개 + a)
- 끊어서 배치 정보를 가져오기 위한 slice pointer 정보를 저장하는 테이블 1개
- 그 외 타 시스템에서 View로 만든 학습 데이터들을 넣기 위해 설계한 테이블
📌 데이터들을 뷰(View)를 생성해서 가져오는 구조를 처음 겪어 보았다. SI였는데 인프라 담당이 우리 회사가 아니었기 때문에 뷰에 변경이 생겼을 때 인프라적으로 뷰 변경 등의 신청이 무척 까다로워서 고생했던 기억이 난다.
Tasklet 관리
배치 애플리케이션이 실행되면 tasklet, service, dao가 올라가고, 태스크릿들은 각각 정해진 동작을 수행한다.
우리 배치는 tasklet, service, dao는 각각 1:1:1 관계를 가지고 있으며, tasklet에서 service를 생성하고 service에서 dao를 호출한다.
📌 처음에는 공통을 별도 설계할 생각이었으나, 업무가 워낙 복잡하면서 겹쳐지지 않는 부분이 많아서 1:1 구조가 되었다
태스크릿을 1개의 쓰레드로 간주한다. 태스크릿은 빈이 아니기 때문에 기존의 방식으로 주입이 불가능했다! (원래 빈들끼리만 주입이 서로 가능함) 빈들은 싱글톤 패턴으로 관리되고 스프링 컨테이너 안에서 관리되는데 태스크릿들은 스프링 컨테이너 밖의 존재들이라 @Autowired를 사용해도 에러는 나지 않지만 그렇다고 제대로 동작하지도 않는다.
따라서 태스크릿에서 서비스 빈을 주입하려면 아래의 SpringContext.getBean("") 고전 방식을 사용해야 했다.
JobRepository jobRepository = SpringContext.getBean("jobRepository");Batch Business Logic
회사 배치의 job들은 각각 cron 식을 가지고 있고 주기별로 성실히 작업을 수행한다.
📌 결국 배치 시간이 겹치면 안되는 점과 시간 순서를 잘 정해야 한다는 점을 보면 순서가 있는 것이 아니냐는 질문을 했는데 시니어들은 단호하게 "순서가 아니야! 그저 각자 잡들이 시간이 되면 일을 하는 것뿐이야!" 라고 강조하셨다.
배치의 flow는 수집-가공-이관 3개 과정으로 이루어져 있다.
처음에 뷰로 데이터를 수집해서 lms DB에 넣기 전에 쿼리로 데이터를 사전 협의에 맞춰서 가공(집계 등의 작업)해서 이관하면 끝.
Slice Pointer
배치는 대용량 데이터들을 다루는데 이것들을 1번에 슉 하고 가져오는 것은 시스템 부하상 불가능하다. 그래서 slice pointer를 정해둔다.
slice pointer는 수집 과정에서 원시 데이터를 가져올 때 데이터 개수를 자르는 기준으로서, 데이터를 insert할 것인지, update 할 것인지를 정한다.
insert? or update
slice pointer 정보를 저장하는 db 테이블을 하나 만들고, 배치에서 데이터를 가져올 때 이 테이블 내 날짜 정보를 가져와서 날짜가 겹치면 신규 데이터를 기준으로 기존 데이터들을 덮어쓰기하고, 겹치지 않을 경우 추가적으로 데이터 insert를 진행한다.
쿼리를 분석해보면 쿼리들마다 where 날짜 조건이 있었는데 on duplicate key를 쓰면 mysql에서 겹치는 key의 경우 액션에 대한 분기처리를 할 수 있다.
📌 key는 관리번호 등의 겹치지 않는 정보다. 날짜가 겹칠 때 데이터를 덮어쓰려면 key 정보가 필요하다.
또 insert ignore into를 사용해서 동일한 key를 가진 경우 insert, update를 하지 않도록 설정했다.
학습분석 쪽의 로직이 유난히 까다로웠는데, 학습분석과 엮인 테이블들이 많은데 배치마다 이들을 전부 delete 한 다음에 insert를 새로 진행해야 하기 때문이다.
📌 학습에서 특정 문항들만 재채점이 이루어진다면?
단순히 배치가 데이터만 가져오는 것이 아니라 가공해서 이관해준 것인데 원시(raw) 데이터 1개만 재채점으로 점수가 바뀐다면?
집계에 이상이 생기기 때문에 위험을 감수하더라도 all delete + insert 과정이 되었다.
Outro
Spring Batch에는 더 많은 기능들이 있지만, 이번 배치는 태스크릿 구조와 잡을 생성해서 스텝을 수행하는 것 위주로 구성된 배치 애플리케이션이었습니다.
이런 배치도 있었다~ 식의 간접 경험 이야기라고 생각하시면 어떨까 싶어서 글 제목을 간접 경험기라고 적었습니다.
정보상 틀린 부분이 있다면 알려주시면 감사합니다:)
