Intro
대부분 웹사이트의 API들은 클라이언트가 먼저 요청을 보내는 클라이언트-서버 모델입니다. 그러나 클라이언트의 요청 없이 서버가 능동적으로 정보를 전달해야 할 경우가 있습니다. 예를 들어, 고객에게 제품 구매 완료 시 이메일 또는 문자로 알림을 보내는 경우, 특정 이벤트 발생 시 데이터를 자동으로 업데이트하는 경우, 혹은 자동화된 개발 파이프라인에서 코드 변경 시 자동으로 배포를 실행하는 경우와 같이 서버가 주도적으로 통신해야 하는 시나리오들이 존재합니다
- tmm에서 주문서가 작성되었을 때 판매자의 휴대폰으로 카톡 메시지가 온다.
- netlify는 git push 후 코드 변경사항을 파악해 자동으로 배포를 실행한다.
위 시나리오들은 서버-클라이언트 단방향 통신 방식입니다. 이번 포스팅에서는 서버-클라이언트 단방향 통신을 Webhook과 gRPC로 구성한 쇼핑몰 MSA 아키텍처를 이해해보려 합니다.
Webhook과 gRPC는 서로 다른 목적을 가지지만, 쇼핑몰 MSA 구조에서는
서버 간 이벤트 전달이라는 공통된 요구를 해결하기 위해 함께 사용됩니다. Webhook은 외부 이벤트 트리거 역할을, gRPC는 내부 서비스 호출 책임을 담당하죠.
Webhook
웹훅은 어떤 이벤트가 발생했을 때, 해당 이벤트에 대한 정보(데이터)를 담아 서버가 다른 서버에게 알림처럼 메시지를 보내주는 방식입니다. 웹훅은 직접 구현할 수도 있고, 서드파티 솔루션(예: Zapier, IFTTT)을 통해 더 쉽게 통합하여 사용할 수도 있습니다.
- Provider 서버에서 특정 트리거 이벤트가 발생합니다. (예: 코드 푸시)
- Consumer 서버는 미리 callback URL을 만들어서 Provider 서버에 등록해 놓습니다. 이후 이벤트가 발생하면 Provider는 이 URL로 POST API 요청과 함께 이벤트 관련 데이터를 전달합니다.
- Consumer 서버는 POST로 전달된 데이터로 비즈니스 로직을 수행합니다.
SSE
웹훅과 SSE는 데이터의 흐름이 서버에서 클라이언트로 향하는 단방향 푸시 방식이라는 공통점을 가집니다. 하지만 웹훅은 특정 이벤트 발생 시 서버(Provider)가 클라이언트(Consumer)에게 일회용 비동기 HTTP 요청(주로 POST)을 보내 데이터를 전달하는 방식인 반면, SSE는 클라이언트(주로 웹 브라우저)가 서버와의 지속적인 HTTP 연결을 먼저 수립하고, 이 연결을 통해 서버가 실시간으로 이벤트를 스트리밍한다는 점에서 다릅니다.
Short/Long Polling
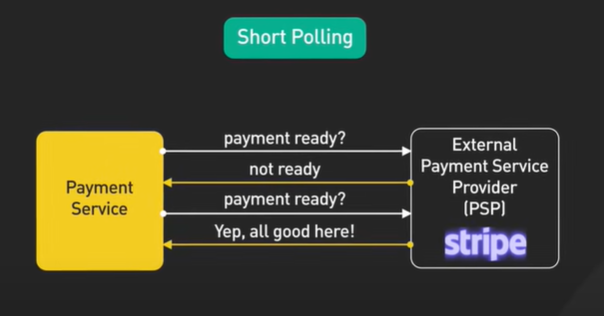
출처: https://www.youtube.com/watch?v=x_jjhcDrISk
webhook이 있기 전 우리는 polling을 사용했습니다. 쇼핑몰에서 주문 후 결제 요청을 보냈다고 가정해 보겠습니다. Short/Long polling을 사용하면 결제 서버 측에서 결제할 준비가 되었는 지에 대해 yes 응답이 올 때까지 계속 요청을 보내 확인해야 했습니다. 이런 방식은 사용자의 지속적인 관심, 알림 확인, 상호작용 등을 끊임없이 요구하는 (영상의 needy) 애플리케이션에서 리소스를 크게 잡아먹습니다. Short와 Long 모두 지속 시간의 차이를 제외하면 같은 단점을 가집니다.
Short polling은 기본적인 요청-응답 모델의 반복이고, 위에서 말한 SSE는 스트리밍 기반의 단방향 지속 연결 모델이라는 차이점이 있습니다.
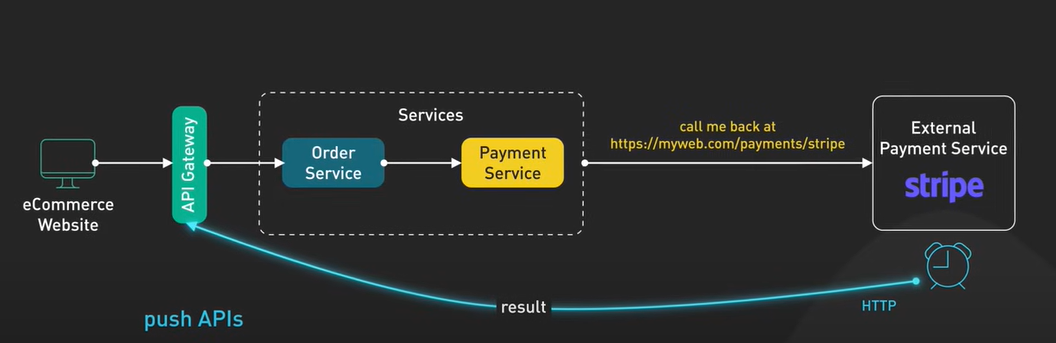
webhook을 도입하면 Consumer 서버가 callback url을 Provider 서버에 등록하고 Consumer 서버는 조건을 만족할 때 결과값을 Consumer 서버 (그림에서는 API 게이트웨이)로 전송해줍니다. Webhook은 외부에서 거꾸로 결과값을 준다는 의미에서 reverse API, push API 라고 불립니다.
Webhook pattern
webHook이 더 원활하게 동작하기 위해서 몇 가지 패턴이 존재합니다.
fallback 매커니즘 준비
서버가 다운될 경우를 대비해서 periodic polling(주기적인 polling으로 데이터 업데이트를 체크)을 상시 준비해야 합니다.
토큰 및 검증으로 보안 강화
Consumer 서버는 요청을 무조건 받아들여선 안됩니다. callback url이 탈취되어 다른 누군가가 무지성으로 Consumer 서버에 요청을 보낼 위험이 있기 때문입니다. 토큰이나 시그니처 인증 등의 방식을 사용해서 Consumer 서버를 보호합니다.
멱등성 유지
Provider 서버에서 요청을 전송할 때 유일 id를 포함해서 중복 요청을 방지해야 합니다. 검색해 보니 예시의 stripe 서버는 웹훅이 발생할 때마다 고유 event_id 값을 가진다고 하네요.
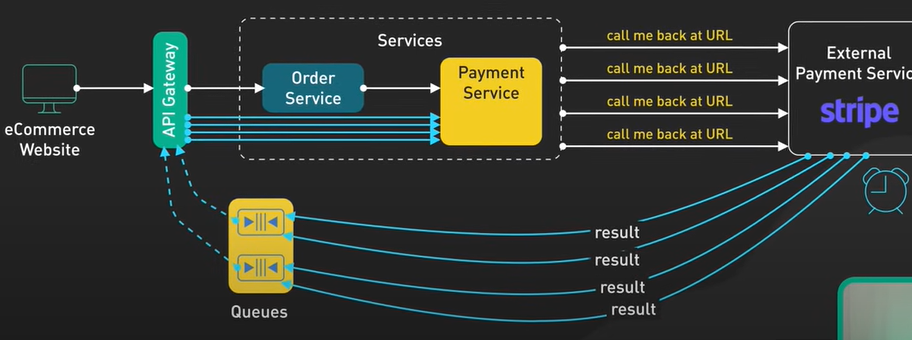
과중을 주의
트래픽이 많은 쇼핑몰에서는 webhook으로부터 Consumer로 비동기 API 요청들이 늘어납니다. 이 때 요청들을 queue로 관리하면 Consumer 서버 부하를 줄이고 들어온 순서대로 요청을 처리할 수 있습니다.
gRPC
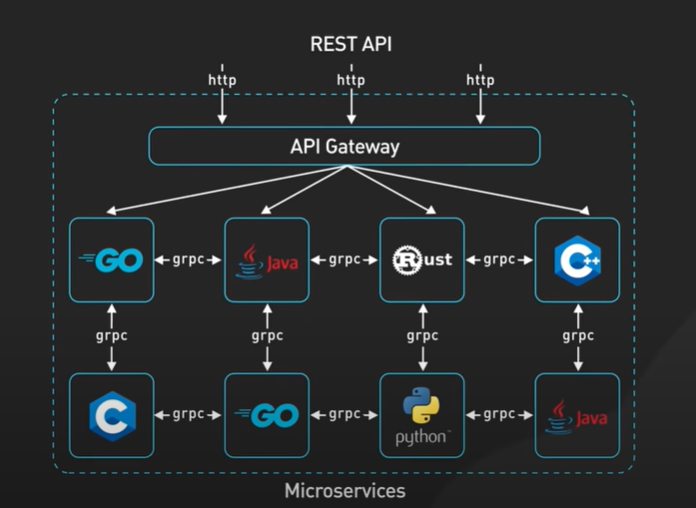
gRPC는 2016년 구글이 구현한 RPC 모델입니다. gRPC는 데이터센터와 MSA 서비스들 사이에서 애플리케이션 간의 내부 통신 모델로 각광받고 있습니다. 넷플릭스, 슬랙과 같은 대기업들 또한 앱 간의 내부 통신이 gRPC 구조로 이루어져 있습니다. gRPC를 사용하면 그림과 같이 앱 간의 개발 언어가 달라도 protobuf 형식을 사용해 원활하게 통신할 수 있습니다.
Protocol Buffers

RESTful 방식의 통신은 기본 형식이 JSON입니다. JSON은 일반적이고 자주 사용되지만 문자열 오버헤드가 발생하고 바이너리 형식보다 용량이 크며, 하위 호환성 개념이 존재하지 않는다는 단점이 있습니다. 물론 클라이언트-서버 모델에서는 JSON이 더 나은 선택지입니다. 왜냐하면 현재 gRPC를 지원하는 브라우저는 많지 않아 클라이언트와의 통신에는 부적합하기 때문입니다. 그러나 서버-서버 통신 모델에서는 외관의 데이터 형식보다 통신 속도에 더 집중할 수 있습니다.
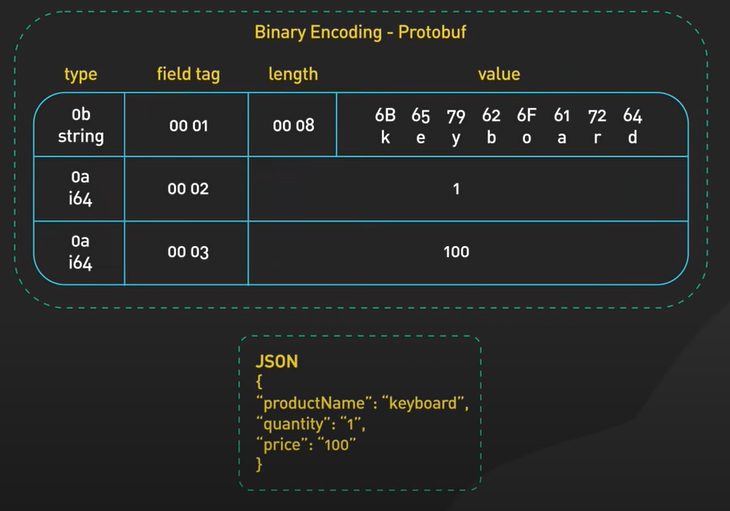
Protocal Buffers(protobuf)는 바이너리 포맷이기 때문에 텍스트 파싱 오버헤드가 적고 JSON 보다 훨씬 빠른 속도를 자랑합니다. 서비스 서버간의 통신, 실시간 데이터 스트리밍에서 처리량이 크게 향상된다는 장점이 있습니다. 또한 protobuf는 .proto 파일로 데이터의 타입, 필드 등을 정의하는데요. 이는 데이터의 일관성과 잘못된 타입의 데이터 전달을 컴파일 시점에서 방지할 수 있습니다. .proto 파일은 많은 개발 언어들을 지원하고 stub이 파일을 기반으로 코드를 자동 생성해줍니다.
꼭 gRPC에서만 protobuf 형식을 사용해야만 하는 것은 아닙니다. RESTful API 방식에 대용량 데이터 처리를 위해 데이터 형식만 protobuf를 사용하는 경우도 있습니다.
Protocal Buffers 흐름
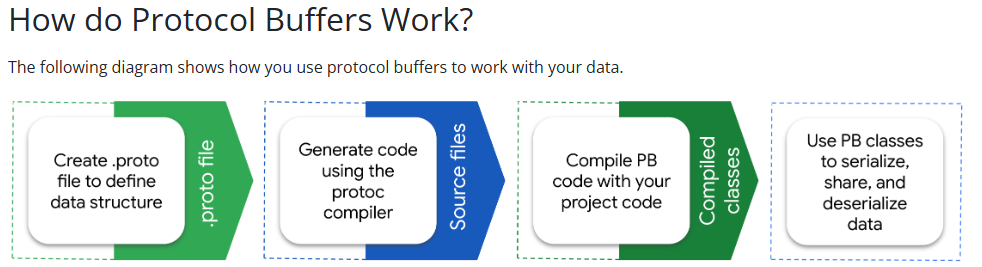
작성된 proto파일은 protoc 컴파일러에 의해 Builder 코드로 변환됩니다.
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.build();
output = new FileOutputStream(args[0]);
john.writeTo(output);.proto 파일에서는 데이터 구조만 명세했을 뿐인데, lombok이 getter를 자동 생성해주는 것처럼, Protocol Buffers도 자동으로 관련 메서드들을 생성해줍니다. C++로 구현한 예는 아래와 같습니다.
Person john;
fstream input(argv[1], ios::in | ios::binary);
john.ParseFromIstream(&input);
int id = john.id();
std::string name = john.name();
std::string email = john.email();이 코드에서는 ParseFromIstream(std::istream*)과 iv별 getter가 자동으로 생성되었습니다.
HTTP/2.0 Stream
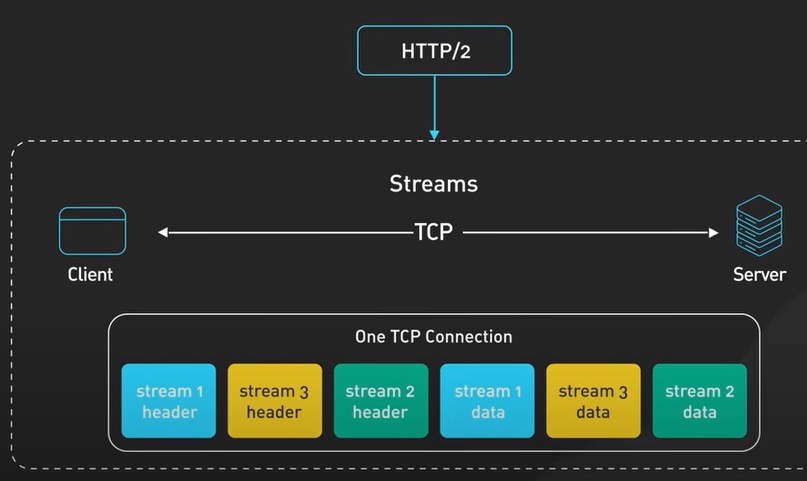
gRPC의 두드러지는 강점 중 하나는 HTTP 2.0 기반으로 동작한다는 점입니다. 멀티플랙싱, 이진 프로토콜, 서버 푸시 등의 HTTP 2.0의 효율적인 지원이 통신을 더 원활하고 빠르게 만듭니다. 덕분에 적은 개수의 TCP 커넥션으로 많은 양의 동시적인 rpc 호출을 처리할 수 있습니다.
Spring Boot로 구현
다음은 Spring Boot에서 grpc, protobuf 의존성을 사용해서 클라언트 서버, 서버로 구현하는 간단한 예제입니다.
의존성 추가
implementation 'net.devh:grpc-server-spring-boot-starter:2.14.0.RELEASE' // rpc 요청을 받는 서버에 필요합니다.
implementation 'net.devh:grpc-client-spring-boot-starter:2.14.0.RELEASE' // rpc 요청을 보내는 서버에 필요합니다.
implementation 'com.google.protobuf:protobuf-java:3.25.1' // rpc를 사용하려면 필요합니다.
protobuf {
protoc {
artifact = "com.google.protobuf:protoc:3.25.1"
}
generatedFilesBaseDir = "$projectDir/src/generated"
plugins {
grpc {
artifact = 'io.grpc:protoc-gen-grpc-java:1.62.2'
}
}
generateProtoTasks {
all().each { task ->
task.plugins {
grpc {}
}
}
}
}.proto 작성
파일을 작성후 그래들로 빌드해줍니다.
syntax = "proto3";
option java_multiple_files = true;
option java_package = "com.example.grpc";
option java_outer_classname = "HelloProto";
service HelloService {
rpc SayHello (HelloRequest) returns (HelloResponse);
}
message HelloRequest {
string name = 1;
}
message HelloResponse {
string message = 1;
}
보내는 서버(Client), 받는 서버(Server) 구현
@GrpcService // 받는 서버가 구현합니다.
public class HelloServiceImpl extends HelloServiceGrpc.HelloServiceImplBase {
@Override
public void sayHello(HelloRequest request, StreamObserver<HelloResponse> responseObserver) {
String greeting = "Hello, " + request.getName() + "!";
HelloResponse response = HelloResponse.newBuilder()
.setMessage(greeting)
.build();
responseObserver.onNext(response);
responseObserver.onCompleted();
}
}
// 보내는 서버가 구현합니다.
@Component
public class GrpcClientRunner implements CommandLineRunner {
@GrpcClient("local-grpc-server")
private HelloServiceGrpc.HelloServiceBlockingStub helloStub;
@Override
public void run(String... args) throws Exception {
HelloRequest request = HelloRequest.newBuilder().setName("Jin").build();
HelloResponse response = helloStub.sayHello(request);
}
}
gRPC가 탄생하기까지의 배경을 이해하려면 프로세스 개념을 이해해야 합니다.
프로세스
태초에 운영체제가 있고 운영체제 내 프로세스들은 완전히 독립된 실행객체로 존재하고 있었습니다. 그렇다보니 별도의 설비가 없다면 이 프로세스들 간의 통신은 불가능했습니다.
리눅스 운영체제 구조
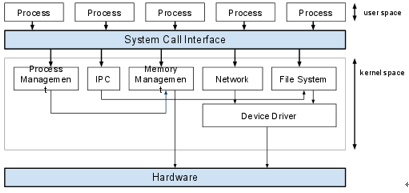
이미지 출처: https://jwprogramming.tistory.com/54
프로세스 개념 정리
프로세스는 실제로 메모리 공간을 할당받아 CPU를 사용하며 열심히 일하는 상황을 뜻합니다.
리눅스와 같은 운영체제는 여러 개의 프로세스를 가지고, 일반 애플리케이션은 인스턴스 1개당 1개의 프로세스를 사용한다고 생각해도 좋습니다. 하지만 고성능 환경에서는 하나의 애플리케이션 서비스 아래 여러 프로세스를 띄울 수 있습니다. 이를 일대다 멀티프로세스 환경이라고 합니다. 쿠버네티스의 포드에 여러 레플리카를 둔 경우가 여기 해당합니다.
IPC
그림에서 보았듯 따로 행동하는 프로세스들이지만 이들끼리 정보를 공유해야 하는 상황에 직면했습니다. 이때 프로세스들끼리 정보를 교환하는 방법론, IPC 가 등장합니다.
소켓
소켓은 IPC 구현 방법론 중 하나로 네트워크의 애플리케이션 계층에서 전송 계층의 TCP/UDP를 이용하기 위한 수단입니다. 실제로 로컬 컴퓨터의 프로세스와 원격지 컴퓨터의 프로세스가 IPC 통신을 하는 것입니다. 그러나 소켓은 다양한 API와 오류 처리 로직을 구현하기 어렵고, 스트림 소켓 등을 사용할 때 메시지 파싱을 커스텀해야 하는 번거로움이 있습니다.
RPC
RPC(Remote Procedure Call)는 원격 서버에 있는 함수나 프로시저를 마치 로컬 함수처럼 호출할 수 있게 합니다. IPC에서의 단일 서버 내의 서로 다른 프로세스 간의 통신 과정의 아이디어를 얻어 서로 다른 프로세스를 가진 서버들 간의 통신을 구현했습니다.
Stub
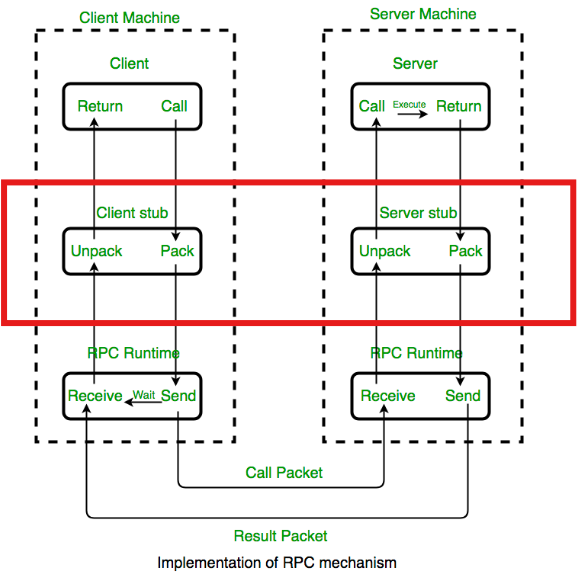
스텁은 proto 파일이 컴파일될 때 코드에 포함되며 프로시저 호출이 실행되면 스텁이 요청을 수신하여 클라이언트 런타임 프로그램에 전달합니다.
RPC 모델은 전통 방식으로 구현하는 것이 복잡해서 대부분 구글의 gRPC를 사용합니다.
Summary
[Webhook 서버 (Spring Boot)]
│
├─ 인증/파싱
├─ 200 OK 응답
└─ 이벤트 전달
├── gRPC → 내부 서비스 A
└── Kafka → 주문/알림 등으로 fan-out네트워크 스터디를 진행하며 아키텍처에 깊이 녹아든 네트워크 개념들을 살펴보고자 이 글을 작성했습니다. gRPC는 브라우저를 직접 사용하지 않는 백엔드 간 서버 통신이나 자원 한정적인 환경에서 특히 유용합니다. 효율적인 바이너리 통신 덕분에 byte/호출/CPU 사용량 등으로 과금되는 클라우드 환경에서 서버 비용을 크게 절약할 수 있습니다.
마찬가지로 Webhook은 불필요한 지속 커넥션과 끊임없는 상태 확인 요청(폴링)을 줄임으로써 서버 리소스를 절약하는 데 기여합니다. 이처럼 gRPC와 Webhook에 담긴 네트워크 개념과 각 기술의 명확한 장점을 안다면 우리는 주어진 상황에 가장 적합한 시스템을 설계할 수 있습니다.
Reference
네이버클라우드 - gRPC 1,2편
- https://medium.com/naver-cloud-platform/nbp-기술-경험-시대의-흐름-grpc-깊게-파고들기-1-39e97cb3460
- https://medium.com/naver-cloud-platform/nbp-기술-경험-시대의-흐름-grpc-깊게-파고들기-2-b01d390a7190
gRPC 공식 문서
Buffer Protocol 공식 문서
bytebytego 추천 유튜브
- https://youtu.be/gnchfOojMk4 (gRPC)
- https://www.youtube.com/watch?v=x_jjhcDrISk (Webhook)
