
Intro
위 글은 어떠한 광고, 홍보 목적도 가지고 있지 않습니다. 주관적인 후기입니다.
숨터디를 참여하면서 스터디에 대해서 기존에 가졌던 생각과 지금이 어떻게 다른지, 내가 고쳐야 할 것들에 대한 생각들을 정리해 보았다.
숨터디 참여
최근에 대규모 시스템 설계와 관련된 스터디를 신청했다. 이름은 숨터디.
자료구조 강의를 들었었던 교육 사이트인데, 이번에 공부하고 싶었던 책을 다루길래 냉큼 신청했다.
🤔 하던 생각, 하던 일만 반복하게 된다
집에만 있으면 집 공간 크기만큼만 생각하게 됩니다.
이 말이 요즘 더 자주 생각이 나곤 한다. 내가 왜 숨터디를 신청했을까?
최근에 너무 혼자서 좁은 시야로만 공부하고 있다는 생각이 유독 자주, 많이 들었기 때문이다. (그래서 글또도 신청했다.) 그리고 책의 내용에 대해서 다른 사람들과 이야기를 나눠보고 싶었다. 항상 숨터디에서는 책마다 관련 git에 쪽지시험처럼 문제들이 올라오는 것을 보고 이거라면 뭐라도 강제로 하게 될 것 같다! 라는 마음에 1주 늦었지만 양해를 구하고 합류할 수 있었다.
스터디 방식
스터디를 하면서 어느 주는 짧게 4챕터를 전부 훑기도 하고, 어느 주는 범위 내 챕터를 다 다루지는 못하더라도 한 챕터에 대해서 깊게 서로 질문하고 고민하는 시간을 가졌다. 나의 경우 후자가 더 기억에 오래 남고 스터디가 끝났을 때 더 기억에 많이 남았다. 음성과 채팅을 번갈아 가면서 했는데 내향적인 나도 부담없이 할 수 있었다.
나의 기존 스터디 방식은 항상 처음부터 끝까지 책에 대한 완벽한 요약본을 만들어야 한다는 강박과 함께했다.
숨터디는 요약본을 만들지 않는다. 요약본을 만드는 것은 좋은 일이지만 정작 본질이 흐려지는 게 아닌가? 생각이 강하게 들었다.
스터디에 대한 변화된 내 생각
- 꼭 책 1권을 완벽하게 뗄려고 하지 않는다.
- 전부를 챙기려 하지 말고 할만하다고 느끼는 것부터 우선순위를 정해서 배운 것들을 경험과 연관지을 수 있는가? 를 먼저 생각해 본다.
- 요약노트에 집착하지 않는다;; (과거의 나에게 너무 하고 싶은 말)
- 이 책이 다루는 주제에 대해서 면접관과 이야기를 한다면 어떨까?를 상상해본다. 그 사람과 대화를 자유롭게 할 수 있을 정도로 책과 관련된 지식을 찾아보고 연구해봤는가?
- 주제에 대해서 이야기를 많이 하자! 단순히 글만 읽지 말고 뭐라도 아웃풋을 만들자!
🌟 Summary
스터디하면서 같이 이야기했던 내용을 몇 가지 적어보았다.
Presigned Url
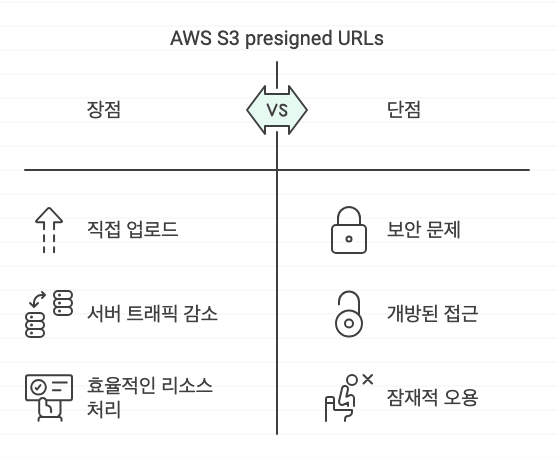
aws s3를 사용하여 리소스를 업로드할 때, 서버를 통해서 버킷에 올리지 않고 presignedUrl을 호출해서 바로 s3의 지정된 곳에 업로드하는 방식이라고 한다. presignedUrl을 사전에 발급받아서 프론트에서 직접 이미지를 업로드할 수 있겠다.
- presignedUrl을 만들기 위한 요청을 보낸다. (프론트)
- presignedUrl을 프론트에게 응답으로 보낸다. (백)
- 프론트가 받은 presignedUrl로 이미지를 다이렉트로 버킷에 업로드한다.
트래픽을 s3가 먹기 때문에 서버의 부담이 줄어드는 장점이 있지만, 누구나 올릴 수 있어서 보안상의 단점 또한 존재한다.
자동완성 시스템에서 고민할 것들
DB 개선
- 인덱스 설계 -> 사실 like는 인덱스 태우기 힘들지;;
- DB 인스턴스 수직 확장 (aws에서 가장 좋은 RDS를 지르자)
- 자동완성은 읽기 위주이므로 샤딩보다는 복제가 더 낫겠다!
상용 시스템 연동
- 엘라스틱 서치나 TypeSense(책에 나오는 Trie 자료구조를 사용하는 시스템)
캐싱 전략
항상 성능과 부하 개선을 어떻게 할까? 주제로는 캐싱이 꼭 나온다.
아키텍처는 유명한 레디스부터 다양하겠지만, 아텍보다 언제 캐싱할 것인지 전략이 제일 중요하겠지?
(멘토님의 컬리 캐싱 전략 협의 경험도 들어봤다~)
검색 전 필터링
- 이모지를 검색해도 검색 api 호출하는 게 맞나? -> 프론트단에서 필터링해야 하지 않나 쓰읍
시스템 그냥 다 쪼개면 오케이일까?
- 처음부터 너무 MSA처럼 생각하고 쪼개는 것보다 일단 서버 1대부터 시작해서 해보다가 점차 개선해 나가는 방식이어야 하지 않을까.
- 스택오버플로우도 대규모 사이트인데 생각보다 그렇게 안 쪼개져 있다.
*개인적으로 회사 si 프로젝트도 시스템 설계 pod 설계나 cpu 오버엔지니어링만 심하게 해서 돈이 없어서 다른 아키텍처 전부 도입 못한 거 보고 좀 공감이 많이 갔다... 진짜 필요할 때 쪼개자. 처음부터 막 화려하게 하다가 나중에 파멸을 맞이하지 말고....
블룸 필터 (bloom filter)
해당 닉네임은 사용중입니다.... 아마도!
성능을 취하고 정확성을 일부 포기한 효율적인 알고리즘이다.
단어가 들어오면 bit array에서 해당 단어와 매칭되는 곳을 찾아 값을 1로 변경한다. 다음 단어가 들어왔는데 해당 자릿값이 1이라면 해당 단어는 이미 닉네임으로 사용되고 있을 확률이 높다.
🔗 https://llimllib.github.io/bloomfilter-tutorial/
snowflake 알고리즘
String이 아닌 유일한 ID값을 생성하는 방법은? 대규모 분산 시스템에 적합한 알고리즘인가?
보통 유니크한 ID라고 하면 UUID를 많이 사용하는데 이는 문자열이다. 숫자값(정수)로 ID를 어떤 규칙으로 생성해야 겹치지 않을까? 트위터에서 만들어낸 snowflake 알고리즘을 사용한다.
- 트래픽을 고려해서 초당 생성 가능 개수가 넉넉해야 한다.
- 특정 기술과 시스템에 의존하지 않으면서 병렬 처리가 가능해야 한다.
- ID 생성시 서버 ID를 할당해서 인스턴스끼리 겹치지 않도록 한다.
결과적으로 timestamp offset + server id + sequence number 3요소를 결합한 비트 연산으로 생성된 ID가 반환된다.
Outro
변카일님의 글또 OT를 듣고 도식화 ai를 시도해 보았다. 생각보다 자동 미리캔버스 피피티 느낌도 난다.
