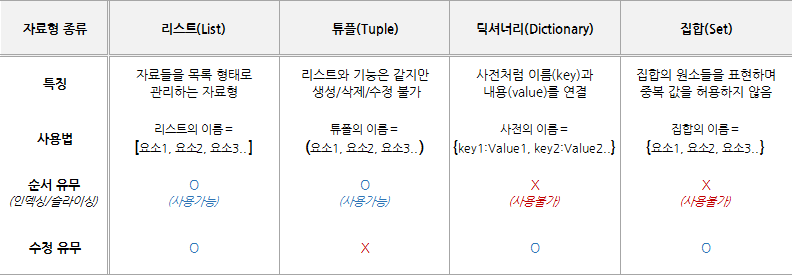
PYTHON은 여러가지 형태를 갖는다.
숫자형, 문자열 자료형, 리스트 자료형, 튜플 자료형, 딕셔너리 자료형, 집합 자료형, 불 자료형
리스트와 튜플을 살펴보자
리스트 자료형
리스트 자료형은 여러 자료들을 목록 형태로 관리하는 자료 구조를 뜻한다.
순서가 있고 수정할 수도 있다.
ex) 리스트명=[요소1, 요소2, 요소3, [요소5, 요소6[요소 1423]]]
과 같이 표시된다. 요소에는 어떤 값이든 들어갈 수 있다.
그리고 얘네도 인덱싱과 슬라이싱이 가능하다.
인덱싱
odd = [1,3,5,7,9]
print(odd) #odd란 변수의 리스트 요소 모두 출력
print(odd[1]) #odd란 변수의 리스트 요소 중 순서가 1인 '3' 을 출력
->[1,3,5,7,9]
->3
슬라이싱
c=['life','is','too','short.']
print(c)
print(c[1]) #인덱싱 사용하여 1순서 출력
print(c[0:4]) #슬라이싱 사용하여 0순서부터 3순서 까지 출력
->['life', 'is', 'too', 'short.']
->is
->['life', 'is', 'too', 'short.']리스트로 연산도 가능하다. 더하기, 반복하기, 길이구하기(.len) 등이 가능하고 수정과 삭제(del a[])도 가능하다.
리스트 관련 함수들을 알고가면 응용이 가능하다.
.append, .sort, .reverse, .index, .insert, .remove, .pop, .count, .extend
리스트 문제를 풀어보자
https://wikidocs.net/7023
Q. ['닥터 스트ㅔ인지', '스플릿', '럭키'] 에 '배트맨'을 추가해라
A.
a=['닥터 스트레인지', '스플릿', '럭키']
a.append('배트맨')
print(a)->['닥터 스트레인지', '스플릿', '럭키', '배트맨']
Q.movie_rank 리스트에는 아래와 같이 네 개의 영화 제목이 바인딩되어 있다.
"슈퍼맨"을 "닥터 스트레인지"와 "스플릿" 사이에 추가하라.
movie_rank = ['닥터 스트레인지', '스플릿', '럭키', '배트맨']
A.
movie_rank = ['닥터 스트레인지', '스플릿', '럭키', '배트맨']
movie_rank.insert(1,'스플릿')
print(movie_rank) ->['닥터 스트레인지', '스플릿', '스플릿', '럭키', '배트맨']
Q. movie_rank 리스트에서 '스플릿' 과 '배트맨'을 를 삭제하라.
movie_rank = ['닥터 스트레인지', '슈퍼맨', '스플릿', '배트맨']
A.
movie_rank = ['닥터 스트레인지', '슈퍼맨', '스플릿', '배트맨']
del movie_rank[2]
del movie_rank[2]
print(movie_rank) ->['닥터 스트레인지', '슈퍼맨']
Q. 다음 리스트에 저장된 데이터의 개수를 화면에 구하하라.
cook = ["피자", "김밥", "만두", "양념치킨", "족발", "피자", "김치만두", "쫄면", "소시지", "라면", "팥빙수", "김치전"]
A.
cook = ["피자", "김밥", "만두", "양념치킨", "족발", "피자", "김치만두", "쫄면", "소시지", "라면", "팥빙수", "김치전"]
print(len(cook)) -> 12
Q. interest 리스트에는 아래의 데이터가 바인딩되어 있다.
interest = ['삼성전자', 'LG전자', 'Naver']
interest 리스트를 사용하여 아래와 같이 화면에 출력하라.
출력 예시:
삼성전자 Naver
A.interest = ['삼성전자', 'LG전자', 'Naver']
print(interest[0], interest[2]) ->삼성전자 Naver튜플 자료형
리스트와 유사하지만 생성, 수정, 삭제가 불가능하다.
자료형 표시 방법 : 리스트 [ ] / 튜플 ( )
튜플은 값을 생성/삭제/수정 할 수 없음
튜플명 = (요소1, 요소2, 요소3, ...)
이런식으로 표시된다.
리스트와 모습은 거의 비슷하지만 튜플에서는 리스트와 다른 2가지 차이점을 찾아볼 수 있다. t2 = (1,)처럼 단지 1개의 요소만을 가질 때는 요소 뒤에 콤마(,)를 반드시 붙여야 한다는 것과 t4 = 1, 2, 3처럼 괄호( )를 생략해도 된다는 점이다.
프로그램이 실행되는 동안 요솟값이 항상 변하지 않기를 바란다거나 값이 바뀔까 걱정하고 싶지 않다면 주저하지 말고 튜플을 사용해야 한다. 이와는 반대로 수시로 그 값을 변화시켜야할 경우라면 리스트를 사용해야 한다. 실제 프로그램에서는 값이 변경되는 형태의 변수가 훨씬 많기 때문에 평균적으로 튜플보다는 리스트를 더 많이 사용한다.
리스트와 동일하게 인덱싱, 슬라이싱, 더하기, 곱하기, 길이 구하기(.len()) 이 가능하다.
딕셔너리 자료형
쉽게 말하면 일상에서 단어를 찾을 때 사전처럼 단어와 그 뜻을 연결해주는 자료형태이다.
순서가 없고, 수정할 수 있다.
사전의 이름 = {key1:Value1, key2:Value2, ...}
와 같이 나타낸다.
[key]={value1, value2, value3, ....}
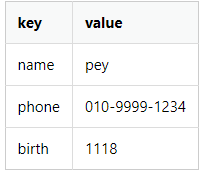
를 딕셔너리 자료형을 나타내보자.
dic = {'name':'pey', 'phone':'010-9999-1234', 'birth': '1118'}
value값에 리스트도 넣을 수 있다.
추가와 삭제도 가능하다.
a = {1: 'a'}
a[2] = 'b'
print(a) ->{1: 'a', 2: 'b'}
a={1: 'a', 2: 'b', 'name': 'pey', 3: [1, 2, 3]}
del a[1]
print(a) ->{2: 'b', 'name': 'pey', 3: [1, 2, 3]}그럼 딕셔너리 자료형은 어디다 쓰냐고?
예를 들어 4명의 사람이 있다고 가정하고, 각자의 특기를 표현할 수 있는 좋은 방법에 대해서 생각해 보자. 리스트나 문자열로는 표현하기가 상당히 까다로울 것이다. 하지만 파이썬의 딕셔너리를 사용한다면 이 상황을 표현하기가 정말 쉽다.
ex)
{"김연아":"피겨스케이팅", "류현진":"야구", "손흥민":"축구", "귀도":"파이썬"}
이름과 특기를 한 쌍으로 하는 딕셔너리이다. 이런 딕셔너리를 더 활용하기 위해서는 몇가지 더 알아야 하는 것들이 있다.
key를 사용해 value 얻기
grade={'pey': 10, 'julliet': 99}
print(grade['pey']) ->10
a = {1:'a', 2:'b'}
print(a[1]) -> a
주의할 사항이 있다.
key는 고유한 값이므로 key 값을 설정해 놓으면 하나를 제외한 나머지 것들이 모두 무시된다는 점을 주의해야 한다. 동일한 key가 2개 또는 2개 이상 존재할 경우 나머지는 무시된다.
ex
a = {1:'a', 1:'b'}
print(a) ->{1: 'b'}
그럼 딕셔너리 자료형과 관련된 함수형은 뭐가 있을까?
.keys, .values, .items, .clear, .get, .in관련 문제들을 가볍게 풀어보자
Q. 다음 아이스크림 이름과 희망 가격을 딕셔너리로 구성하라.
이름 희망 가격
메로나 1000
폴라포 1200
빵빠레 1800
A.
ice = {"메로나": 1000, "폴라포": 1200, "빵빠레": 1800}
print(ice) ->{'메로나': 1000, '폴라포': 1200, '빵빠레': 1800}
Q. 다음 딕셔너리에서 메로나의 가격을 1300으로 수정하라.
ice = {'메로나': 1000,
'폴로포': 1200,
'빵빠레': 1800,
'죠스바': 1200,
'월드콘': 1500}
A. ice["메로나"] = 1300
print(ice) ->{'메로나': 1300, '폴로포': 1200, '빵빠레': 1800, '죠스바': 1200, '월드콘': 1500}
>
Q. 다음의 딕셔너리로부터 key 값으로만 구성된 리스트를 생성하라.
icecream = {'탱크보이': 1200, '폴라포': 1200, '빵빠레': 1800, '월드콘': 1500, '메로나': 1000}
A.
icecream = {'탱크보이': 1200, '폴라포': 1200, '빵빠레': 1800, '월드콘': 1500, '메로나': 1000}
ice = list(icecream.keys())
print(ice) ->['탱크보이', '폴라포', '빵빠레', '월드콘', '메로나']집합 자료형
수학의 집합 개념과 비슷하다.
집합 자료형은 set() 을 사용해 만들 수 있다.
a= set('apple')
print(a) -> {'l', 'e', 'p', 'a'}이와같이 문자열을 입력하여 만든 자료형이다.
그치만 순서가 뒤죽박죽이고, 글자가 좀 빠진것 같은 느낌이 든다.
이러한 이유는 집합의 set 특징 때문이다.
-중복을 허용하지 않는다.
-순서가 없다.
리스트나 튜플은 순서가 있기 때문에 인덱싱을 통해 자료형의 값을 얻을 수 있지만 set 자료형은 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없다. 앞에 살펴 본 딕셔너리 또한 순서가 없는 자료형이라 인덱싱을 지원하지 않는다.
set 자료형에 저장된 값을 인덱싱으로 접근하려면 리스트나 튜플로 변환 후 해야한다.
a=set('apple')
b=list(a)
print(b[0]) -> a그럼 집합 자료형은 어디다 씁니까?
교집합, 차집합, 합집합을 구할 때 쓴다.
.intersection()=&, .difference()=-, .union()=|한번 해보자
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])
print(s1&s2) -> {4, 5, 6}
or
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])
print(s1.intersection(s2))이런 식으로 가능하다.
.add(), .update(), .remove()가 가능하다.
ex)
s1 = set([1, 2, 3])
s1.add(4)
print(s1) -> {1, 2, 3, 4}
s1 = set([1, 2, 3])
s1.update([4, 5, 6])
print(s1) -> {1, 2, 3, 4, 5, 6}
s1 = set([1, 2, 3])
s1.remove(2)
print(s1) -> {1, 3}불(bool) 자료형
참(True)과 거짓(False)를 나타내는 자료형이다. 이 두가지 값만 가질 수 있다.
*True, False는 파이썬의 예약어이기 때문에 항상 첫 문자를 대문자로 사용해야만 한다.
일단 한번 보자
a=True
b=False따옴표로 감싸지 않았기 때문에 오류가 발생할 것 같지만 그렇지 않다.
a=True
b=False
print(a, type(a)) -> True <class 'bool'>잘만 된다. 타입 지정이 된 것을 보면 'bool'로 지정이 된 것을 볼 수 있다.
조건문에서도 적용이 된다.
1 == 1
print(1 == 1) -> True
2 > 1
print(2 > 1) -> True
2 < 1
print( 2 < 1) -> False자료형에도 참과 거짓이 존재한다
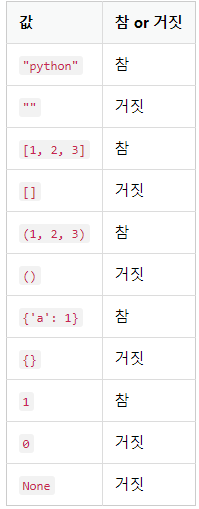
문자열, 리스트, 튜플, 딕셔너리 등의 값이 비어있으면 거짓이 된다. 반대로 비어있지 않으면 참이 된다. 숫자에서는 그 값이 0이 될 때 거짓이 된다. 위의 None 은 거짓인데 이것은 나중에 알아보자.
예시를 한번 보자
a = [1, 2, 3, 4]
while a:
print(a.pop()) ->
4
3
2
1while 문을 모르는 사람들에게 쉽게 설명하자면 조건문이 참인 동안에 조건문 안에 있는 문장을 반복해서 수행하라는 의미다.
while 조건문
^^^수행할 문장
즉 a가 참이면 a.pop()을 계속 출력해라 라는 의미다. .pop은 리스트 안의 마지막 요소를 끄집어내는 것이기 때문에 리스트 안의 요소가 다 끝날 때 까지 계속 지속될 것이다. 결국 마지막에 더 꺼낼 것이 없으면 그 때 거짓이 되는 것이다. 그러면 while문 안에서 거짓이 되기 때문에 while문을 빠져나가게 되는 것이다.
그럼 연산을 해보자
bool 함수를 사용하면 자료형의 참과 거짓을 보다 정확하게 식별할 수 있다.
bool('python')
print(bool('python')) -> True
bool('')
print(bool('')) -> False