근래에 배달의민족에서 타 배달앱서비스 업체가 본인들의 data를 허가없이 crawling 하여 재산권침해를 주장하는 news가 있었다. target service를 crawling 할 수 있도록 소유자가 허가했는지 확인하는 방법을 있으니 참고하자.
main site 뒤에 "/robots.txt"를 추가하여 request시 권한 관련 정보를 제공하는 site가 있다. 이를 통해 최대한 법적 충돌 발생여부를 피하자.
What you will learn?
- WEB Crawling 에 대한 이해
- python 환경에서 Crawling을 하기 위해 필요한 tool 소개 및 설치
- chrome developer tool과 beautifulSoup4로 Data 추출 해보기
- selenium으로 자동 crawling 해보기
1. WEB Crawling 에 대한 이해
WEB Crawling은 web site의 html로부터 필요한 정보를 추출하는 기술로 알려져 있다. 정확히는 아래 두 가지 용어로 세분화 된다.
- WEB Scraping
신문에서 기사부분을 Scraping 하듯 WEB site html로부터 정보를 추출하는 것.- WEB Crawling
WEB Scraping과 비슷하다 좀더 자동화 된 개념.
(일정 시간 단위로 Scrap을 반복 또는 사용자 액션 시뮬레이션 결과물을 Scrap 하는 것)
2. python 환경에서 Crawling을 하기 위해 필요한 tool 소개 및 설치
crawling을 위해 사용해야 할 package는 아래와 같다.
pip install beautifulsoup4
pip install selenium
pip install requests
pip install webdriver-managerfrom bs4 import BeautifulSoup bs = BeautifulSoup(html 또는 open('xxx.html'))
beautifulSoup4 (beautifulSoup)
crawling 기능이 있는 library. html을 객체화, tag를 통해 name등의 정보는 물론 dictionary화 되어있는 attribute에 접근하여 정보를 얻을수도, 수정할수도 있도록 지원하는 library 이다. 사용하기에 simple하고 빠르다는 것이 장점이다.selenium
crawling 기능이 있는 library. Selector를 통해 만들어진 객체를 통해 click등의 사용자 event등을 실행할 수 있다. 가령 Tag a로 link되어지는 html이 많은 사이트의 경우 beautifulSoup4로 scrap시 각 html에 대한 url을 일일이 지정해줘야 하는데 selenium은 사용자가 해당 링크를 click 한 것처럼 software적으로 액션을 줄 수 있다. 자동화 할 수 있다는 장점이 있으나 처리를 위한 성능이 필요하여 처리가 느리고 메모리 점유율이 높다는 단점이 있다.
WEB 자동화 테스트로 사용할 수 있다.requests
crawling은 html을 통해 해야 하므로 WEB site의 html을 얻어와야 한다. requests는 python 상에서 대상 url을 지정하여 요청을 하면 html을 받을 수 있도록 지원하는 library.webdriver-manager
부수적인 library
3. chrome developer tool과 beautifulSoup4로 Data 추출 해보기
http://books.toscrape.com 는 crawling 테스트용으로 적합한 site이다. 이 site를 기준으로 진행해 보겠다. 우선 아래와 같은 준비가 필요하다.
- 가상환경 생성(나는 'scrap' 으로 명명)
- 가상환경 상에 pypi의 beautifulSoup4 및 requests 설치.
- python 파일을 하나 생성 후 아래화면처럼 coding.
from bs4 import BeautifulSoup import requests import re import csv # 1. 크롤링 하고자하는 웹 페이지 링크 org_crawling_url = "http://books.toscrape.com" crawling_url = "http://books.toscrape.com/catalogue/category/books/travel_2/index.html" response = requests.get(crawling_url) # 2. BeuatifulSoup 클래스를 이용해 html 코드를 파싱 bs = BeautifulSoup(response.text, 'html.parser' ) # 3. 타이틀 하나를 지칭하여 고르기 one_title = bs.select_one("#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img") # 4. 타이틀 여러개를 모두 지칭하여 고르기 titles = bs.select("#default > div > div > div > div > section > div:nth-child(2) > ol > li > article > div.image_container > a > img") # 5. 각 타이틀 이름과, 이미지 url을 모두 프린트 for title in titles: pass print('title: ', title['alt']) print('original src: ', title['src']) print('image_url: ', title['src'].split('/')[4:]) print('true_image_url: ', org_crawling_url + '/' + '/'.join(title['src'].split('/')[4:]))request 객체로 'crawling_url' 경로를 get하여 response를 받아온 후 response.text속성으로 html을 얻어 BeautifulSoup(이하 bs) 객체를 생성하고 있다.
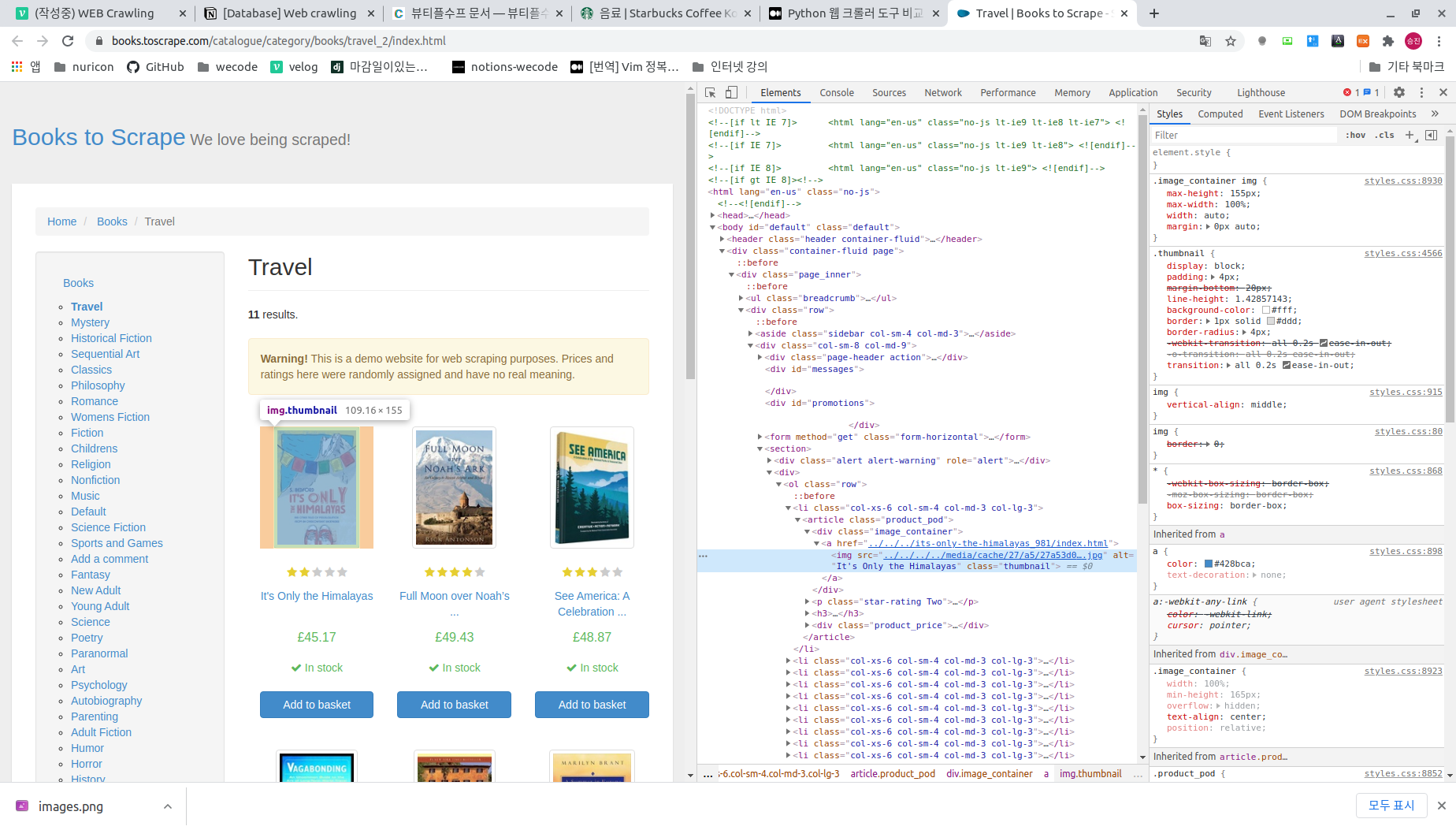
이 객체의 select 또는 select_one method를 통해 html의 element 정보를 접근할 수 있는데 이 때 입력하는 정보를 얻기 위해서 우리는 chrome developer tool을 이용해야 한다.
위 화면은 crawling 하려는 대상 url에서 개발자 툴을 실행한 화면이다. 화면의 "It's only the Himalaya"라는 책에 대한 tag를 추적, elements tab상에 해당 tag가 선택되어 있다.
이 위에서 [mouse rbutton -> copy -> copy selector] 를 실행하면 해당 element의 정보를 복사하게 되는데 이 값을 BeautifulSoup 객체의 select() 호출시 입력해주면 된다.'주석 #3'과 '주석 #4' 두 line을 보면 selector 정보 중 'li' 부분에 차이가 있는 것을 볼수 있는데 '#3'은 child를 지정하여 하나만 가져오는 과정으로 개발자 툴에서 copy시 나오는 경로이며 '#4'는 child 전부의 정보를 얻기위해 li의 child 지정부분을 일부러 삭제한 것이다.
이렇게 해서 나온 tag객체(또는 객체들)은 '주석 #5' 처럼 Dictionary 처럼 속성이름을 key로 접근하여 value를 얻을 수 있다. 아래는 이 python파일을 실행한 결과 화면이다.

4. selenium으로 자동 crawling 해보기
python 파일을 하나 만들어 아래와 같이 coding
import csv import time from bs4 import BeautifulSoup from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager #csv_filename = "sokcho_restaurants_and_tags.csv" #csv_open = open(csv_filename, "w+", encoding='utf-8') #csv_writer = csv.writer(csv_open) #csv_writer.writerow( ('title','tags' ) ) driver = webdriver.Chrome(ChromeDriverManager().install()) org_crawling_url = "http://books.toscrape.com/" driver.get("http://books.toscrape.com/") #element = driver.find_element_by_id("inp_search") #element.click() #element.send_keys(query_keyword) # #driver.find_element_by_link_text("검색").click() # full_html = driver.page_source soup = BeautifulSoup( full_html, 'html.parser' ) time.sleep(3) categories = soup.select('#default > div > div > div > aside > div.side_categories > ul > li:nth-child(1) > ul > li > a') for i in range(1, len(categories) + 1): element = driver.find_element_by_css_selector(f'#default > div > div > div > aside > div.side_categories > ul > li > ul > li:nth-child({i}) > a') time.sleep(2) element.click() full_html = driver.page_source soup = BeautifulSoup(full_html, 'html.parser') titles = driver.find_elements_by_css_selector("#default > div > div > div > div > section > div:nth-child(2) > ol > li > article > div.image_container > a > img") titles = soup.select("#default > div > div > div > div > section > div:nth-child(2) > ol > li > article > div.image_container > a > img") # 5. 각 타이틀 이름과, 이미지 url을 모두 프린트 for title in titles: print('title: ', title['alt']) print('original src: ', title['src']) print('image_url: ', title['src'].split('/')[4:]) print('true_image_url: ', org_crawling_url + '/' + '/'.join(title['src'].split('/')[4:])) # 6. 가격 정보 선택 prices = driver.find_elements_by_css_selector("#default > div > div > div > div > section > div:nth-child(2) > ol > li > article > div.product_price > p.price_color") for price in prices: pass print(titles) tags = soup.select('#contents > div > div.box_leftType1 > ul > li > div.area_txt > p.tag') time.sleep(3) title_list = [title.text for title in titles] tag_list = [tag_set.text.split('#')[1:] for tag_set in tags] for i, title in enumerate(title_list): for j, tag in enumerate(tag_list[i]): print(tag) if j == 0: csv_writer.writerow((title, tag)) else: csv_writer.writerow(('', tag))selenium의 webdriver를 통해 chrome driver를 생성 후 해당 driver로 select에 접근하여 얻은 객체를 통해 click()을 2초 간격으로 순차적으로 실행하는 것을 확인할 수 있다. 그리고 그 결과 페이지에 대해 beautifulSoup 객체를 만들어 정보를 뽑아내고 있다. 최종으로는 원하는 정보를 추출하여 CSV 형식의 파일로 저장한다.
이를 python으로 실행해보면 chrome browser로 http://books.toscrape.com 가 표출되며 화면의 좌측에 나오는 Category를 순차적으로 click, 해당 category로 페이지가 refresh 되는 것을 확인 할 수 있다. category별로 페이지가 갱신되면 그 html 에서 정보를 추출한다.
