Garbage Collector
사용하지 않는 변수를 사용하지 않는 경우 변수는 계속 메모리 공간에 남아 있게 된다. 이런 것들이 하나 둘 씩 쌓이는 것을 memory garbage라고 한다.
c언어로 보았을때 일반적으로 메모리를 스택 메모리와 힙 메모리 두 가지로 구분한다.
-
스택 메모리
일반적인 변수선언은 스택 메모리에 할당이 된다. 차곡 차곡 쌓이는 형태이다. -
힙 메모리
힙은 프로그래머가 쓰고싶은 사이즈의 메모리를 할당 받을 수 있는데 이 것을 malloc이라고 한다. malloc은 반드시 할당을 받고 쓸모가 없어 졌을 때 free를 통해 지워 주어야 한다.
memory leak
c언어에서 스택 메모리는 선언된 지역을 벗어나면 지워진다. 이때 포인터 변수로 malloc을 받은 변수가 지워진다면 malloc으로 받은 주소를 아무도 모르게 된다. 이 것을 memory leak 이라고 한다.
memory leak을 프로그램만 잘 짜면 생기지 않지만 사람은 늘 실수를 하기 때문에 매우 흔히 있는 버그이다. 이 점을 보안하기 위해 java에서 만들어 진 것이 garbage collector(GC) 이다.
Reference count
GC가 동작하는 원리로 참조 횟수를 뜻한다.
func add() *int {
var a int
a = 3 //a=cnt 1
var p *int
p=&a //a 의 주소를 받음 p =cnt 1 , a=cnt 2
return p // 주소를 반환
} //
v := add() //p에게서 주소를 받았지만 실질 적으론 a의 주소 p = cnt 0 , a = cnt 1
-----------------------------------
함수를 벗어나면 p는 사용되어지지 않기 때문에 자동적으로 지워짐 a의 주소는 v에 의해 사용 되고 있음c 언어는 Reference count가 없다. 위의 상황은 c 언어 에서는 이미 사라진 변수 를 참조하고 있기 때문에 프로그램이 강제 종료 됨.
Reference count가 있어도 외딴섬 처럼 다른데서 사용되어 지지않고 서로서로 참조가 맞물려 있을 경우에도 GC는 청소를 해준다.
Managed 언어
GC는 만들어진 변수들을 모두 관리해야 되기 때문에 속도가 느리다.
옛날 자바에서는 프로그램을 돌릴때마다 GC가 일을 해야 되기 때문에 중간 중간 멈출 때가 많았다.
현재에 와서는 GC가 조금 조금씩 프로그래머가 눈치못채게 일을 하기 때문에 멈추는 일이 없어졌다.
c와 c++에서도 memory leak을 관리해주는 툴이 생겼지만 그 메모리를 관리하는건 전적으로 프로그래머에게 달려있다.
이렇게 GC에 의해 메모리가 관리 되어지는 언어를 Managed 언어 라고 하고 그렇지 못한 언어 들은 Unmanaged 언어 라고 한다.
-
Unmanaged 언어 : C, C++
-
Managed 언어 : JAVA, C#, Go,...
garbage collector의 한계
엄청 큰 배열을 만들어 그 안에 여러 변수들을 참조 시켰을 때 Reference count도 1인 상태이고 외딴섬 상태도 아니기 때문에 그 안에서 사용 되지 않는 메모리들은 지워지지 않는다.
동적 배열 Slice
동적 배열은 배열의 길이가 정해진 정적배열과는 반대로 배열의 길이가 변하는 배열이다.
1. 동적 배열의 원리
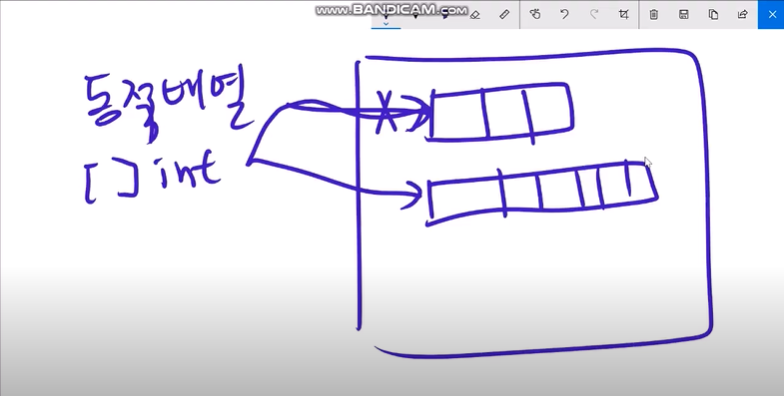
동적 배열은 정적 배열의 주소를 가지고 있고 배열이 늘어 났을 때 주소를 통해 값을 복사해 늘린 배열에 붙여 넣는다. 그 후 늘린 배열로 주소를 바꾼다.
*동적 배열은 정적 배열을 포인트하고 있다.
동적 배열 선언
var a []int // 빈 배열만 만듦
a := []int{1, 2, 3, 4} //배열과 초기값 설정
a := make([]int, 3) // 초기 길이 설정
a := make([]int, 3, 8) // 길이와 , capacity 지정 = 8개의 공간을 확보해 놓고 실제 사용하는건 3개 라는 의미ex1) capacity
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5} // 1~5까지 초기화
fmt.Printf("len(a) = %d\n", len(a)) // 배열의 길이
fmt.Printf("cap(a) = %d\n", cap(a)) // 배열의 확보된 길이
fmt.Println()
b := make([]int, 0, 8) // make를 통해 실제 사용 길이와 capacity 지정
fmt.Printf("len(a) = %d\n", len(b))
fmt.Printf("cap(a) = %d\n", cap(b))
}
-----------------------------
len(a) = 5
cap(a) = 5
len(a) = 0
cap(a) = 82. 동적 배열에 값을 추가하는 방법
ex1) append
package main
import "fmt"
func main() {
a := make([]int, 0, 8)
fmt.Printf("len(a) = %d\n", len(a))
fmt.Printf("cap(a) = %d\n", cap(a))
a = append(a, 2) // a(slice)에 , 2 항목을 추가 함
fmt.Printf("len(a) = %d\n", len(a))
fmt.Printf("cap(a) = %d\n", cap(a))
}
-------------------------------
len(a) = 0
cap(a) = 8
len(a) = 1 //길이가 늘어남
cap(a) = 8a = append(a, 2) 에서 a(slice처음)는 만든 배열과 같을 수도 있고 다를 수도 있다.
ex2) 다른 경우
package main
import "fmt"
func main() {
a := []int{1, 2} // a는 2개의 공간만 있음
b := append(a, 3) // a에 3을 추가
fmt.Printf("%p %p\n", a, b)
fmt.Println(a)
fmt.Println(b)
b[0] = 4
b[1] = 5
fmt.Println(a)
fmt.Println(b)
fmt.Println(cap(a)) // 확보된 공간 확인
fmt.Println(cap(b))
}
-----------------------------
0xc0000120a0 0xc0000101e0 //주소가 다름
[1 2]
[1 2 3]
[1 2] // a는 바뀌지 않음
[4 5 3]
2
4 // 1개가아닌 2개가 확보됨
ex3) 같은 경우
package main
import "fmt"
func main() {
a := make([]int, 2, 3) //2개를 사용하고 공간은 3개 확보
a[0] = 1
a[1] = 2 // {1 ,2} 를 추가
b := append(a, 3) // a에 3을 추가
fmt.Printf("%p %p\n", a, b)
fmt.Println(a)
fmt.Println(b)
b[0] = 4
b[1] = 5
fmt.Println(a)
fmt.Println(b)
}
----------------------
0xc0000ae078 0xc0000ae078
[1 2]
[1 2 3]
[4 5]
[4 5 3]많이 헷갈릴 수 있어서 버그가 발생하기 쉬움
a 와 b는 다르다고 생각하는게 좋다.
안전하게 하기 위해 먼저 copy를 하고 복사를 하는방법이 있다.
ex4) copy
package main
import "fmt"
func main() {
a := make([]int, 2, 4) //공간에 여유가 있는 배열을 만듦
a[0] = 1
a[1] = 2
b := make([]int, len(a)) //동적 배열을 하나 더 만듦
for i := 0; i < len(a); i++ {
b[i] = a[i] //복사
}
b = append(b, 3) //3을 추가
fmt.Printf("%p %p\n", a, b)
fmt.Println(a)
fmt.Println(b)
b[0] = 4
b[1] = 5 //b의 값을 바꿈
fmt.Println(a)
fmt.Println(b)
}
---------------------------
0xc000124020 0xc000124040
[1 2]
[1 2 3]
[1 2]
[4 5 3]
3. Slice란?
잘라낸다라는 의미?
a := []int{1,..,10}
b := a[start index:end index] // start index 부터 end index -1 번째 index까지ex1)
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
b := a[4:8] // 4번째 ~ 7번째 index 까지
fmt.Println(b)
}
--------------------------------
[5 6 7 8]
ex2) end index를 생략 할 경우
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
b := a[4:] // 4번째 부터 끝까지
fmt.Println(b)
}
--------------------------------
[5 6 7 8 9 10]ex3) start index를 생략 할 경우
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
b := a[:4] // 처음부터 3번째 인덱스 까지
fmt.Println(b)
}
--------------------------------
[1 2 3 4]4. slice의 원리
잘라낸다는 의미라고 생각하는거 보다는 가르킨다(pointer) 라고 생각하는게 이해하기 좋다.
실제로 slice가 메모리에 저장될때
- 메모리 주소(pointer)
- 길이(length)
- 확보된 공간(capacity)
들의 정보가 같이 저장된다.
그렇기 때문에 slice는 구조체와도 같다.
ex1)
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
b := a[4:8]
b[0] = 1
b[1] = 2 // b의 0번째 와 1번째의 값을 바꿈
fmt.Println(a) // a를 출력
}
---------------------------------
[1 2 3 4 1 2 7 8 9 10] // a의 4번째와 5번째의 값이 바뀜
slice를 했다고 해서 메모리를 복사해 오는게 아니기 때문에 값을 수정할때는 항상 인지를 하고 있어야 한다.
Instance
과거의 프로그래밍은 방식은 순서대로 작업을하는 절차(procedure)가 중요했다. 기능이 우선시 되었다.
현재에는 절차가아닌 OOP(Object Oriented Programming) 객체가 중요시 하게 되었다.
객체(object)는 주체(object)와 동사(method)를 가진다.
누가.뭘할꺼냐(무엇과 관계를 맺을꺼냐)
ER(Entity - Relationship) 객체와의 관계가 중요함
ex)
type Student struct {
name string
age int
grade int
}
func SetName(t *Student, newName string) { // SetName이라는 기능에 t *Student가 들어감
t.name = newName
}
func (t *Student) SetName(newName string) { t *Student가 주체가 되고 SetName이 포함된다.
t.name = newName
}컴퓨터 입장에서는 아무 상관 없지만 프로그래머의 입장에서는 패러다임이 완전히 바뀌었다고 할 수 있다.
주체가 생김으로서 주체가 생명을 가지기 시작했다고 볼 수 있다. 이 때 주체를 Instance라고 하고 추상적인 개념이다.
