EDA(5)_서울시 CCTV 분석 프로젝트 : pandas_DataFrame(탐색,정렬,컬럼선택/slice)
0
(ZB) DS 16기_part04_EDA/웹크롤링/파이썬프로그래밍
목록 보기
5/19

pandas 기초
- 표준 정규분포에서 샘플링한 난수 생성하기
np.random.randn(6,4)
[해석] 6행 4열의 형태로 난수를 생성해줘
df = pd.DataFrame(data, index, columns)
[해석] 지정한 data와 index와 colmns에 따라 데이터 프레임을 만들어줘
** data, index, columns 값이 각각 무엇인지 사전에 정의해 둘 필요 있음
- df.head( ) : 데이터 프레임 정보탐색 (1) 상위 5개 데이터 탐색 메서드
- df.tail( ) : 데이터 프레임 정보탐색 (2) 하위 5개 데이터 탐색 메서드
- df.index
- df.columns
- df.values
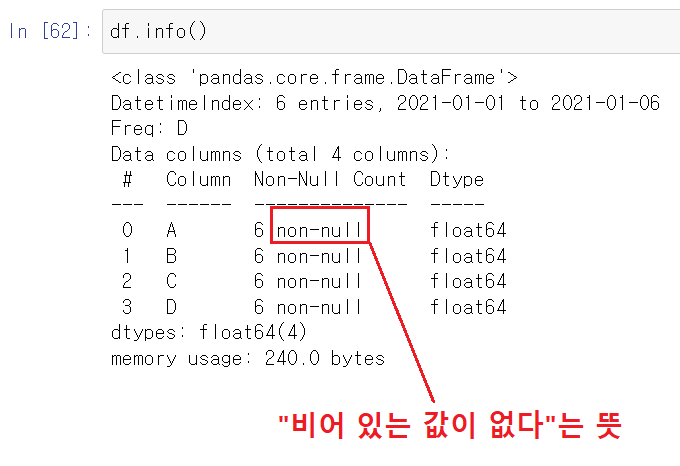
- df.info( ) : 데이터 프레임의 기본 정보를 확인하는 메서드
- df.describe : 데이터 프레임의 기술통계 정보를 확인하는 메서드
(참고) head와 tail 뒤에 ( ) 가 붙는 이유?

df.sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬
[예시] df.sort_values(by="B") : B컬럼을 기준으로 데이터를 정렬해줘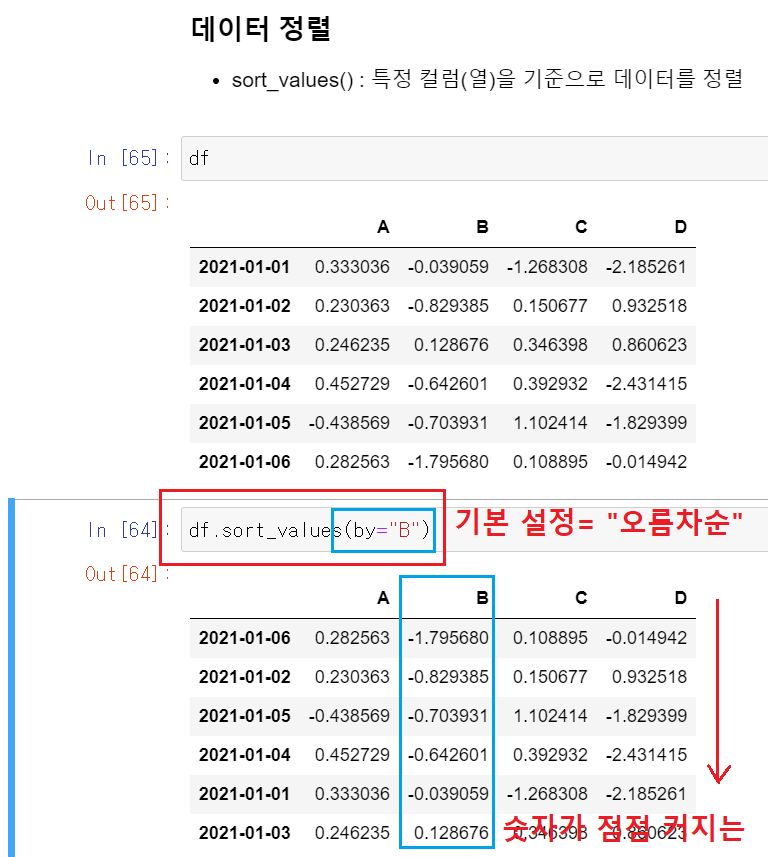
정렬 : 오름차순 / 내림차순 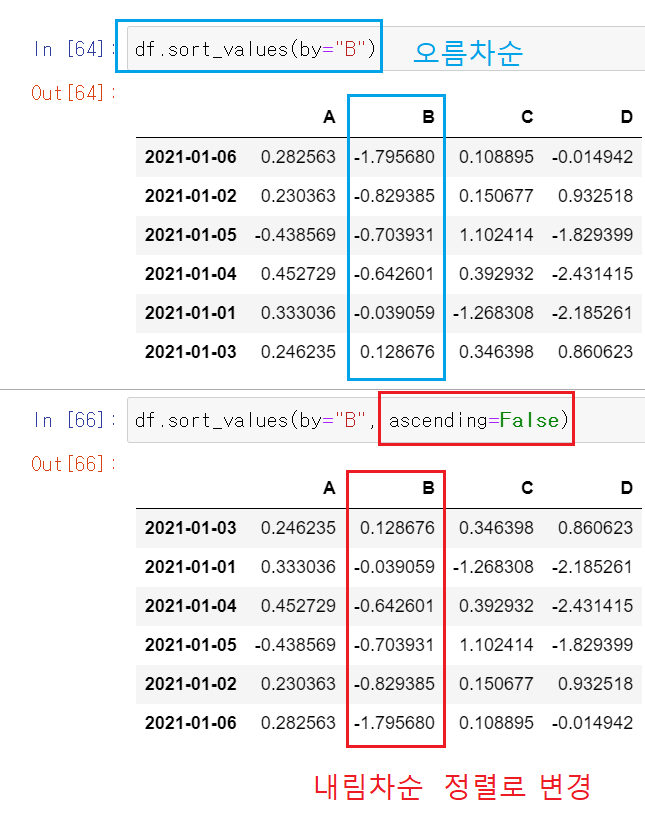
정렬 상태 저장하기(원본 데이터에 반영하기)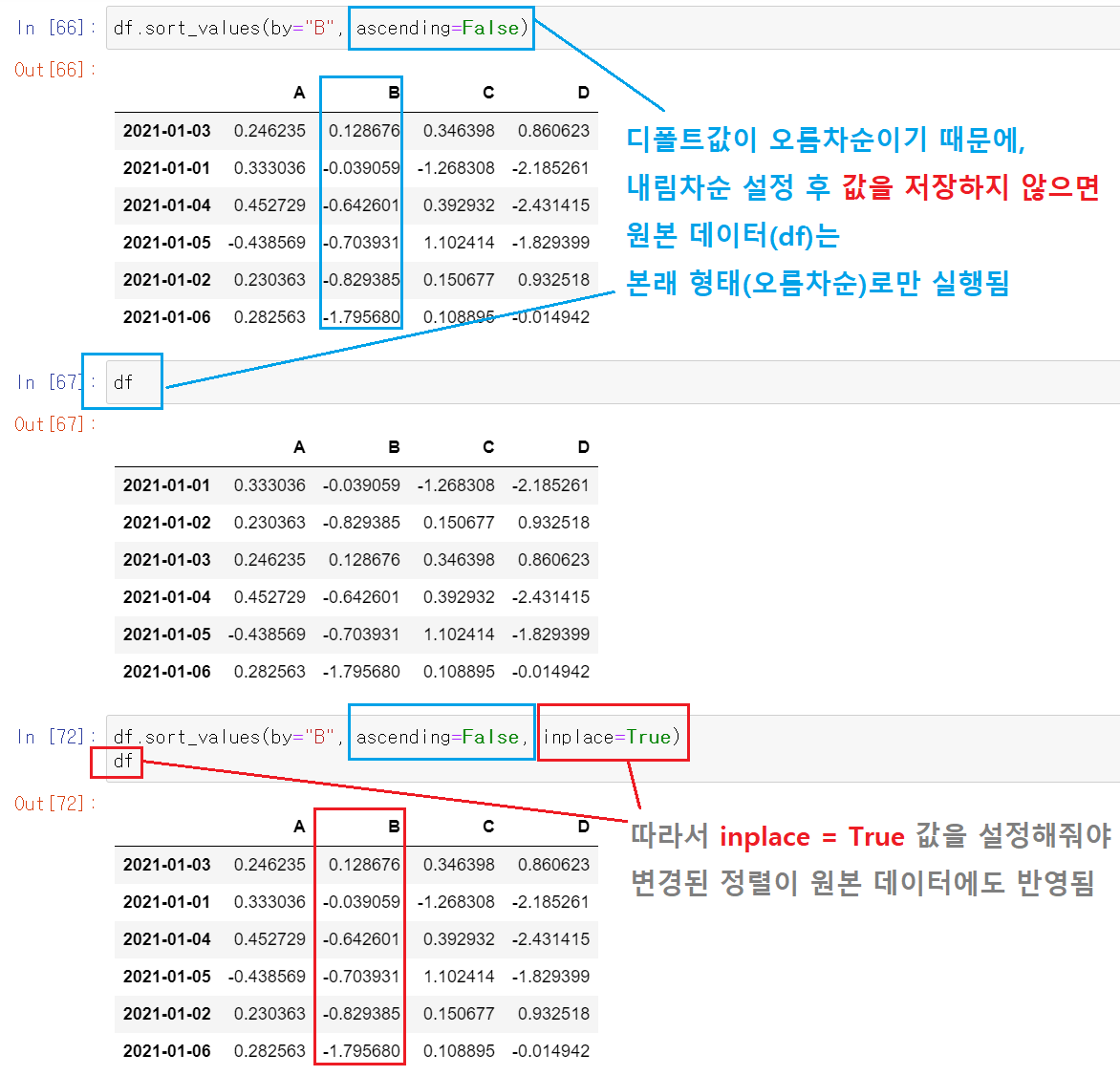
- df["컬럼이름"] : 전체 데이터에서 지정한 1개 컬럼만 선택하기
- df[["컬럼이름A", "컬럼이름B"]] : 전체 데이터에서 2개 이상의 컬럼을 선택할 때는 리스트([ ])로 반드시 묶어주기
- df[시작 컬럼위치 : 끝 컬럼위치] 또는 df[시작 컬럼이름 : 끝 컬럼이름] : offset index
offset index 는 [n:m] 형태, "n부터 m-1까지"를 의미함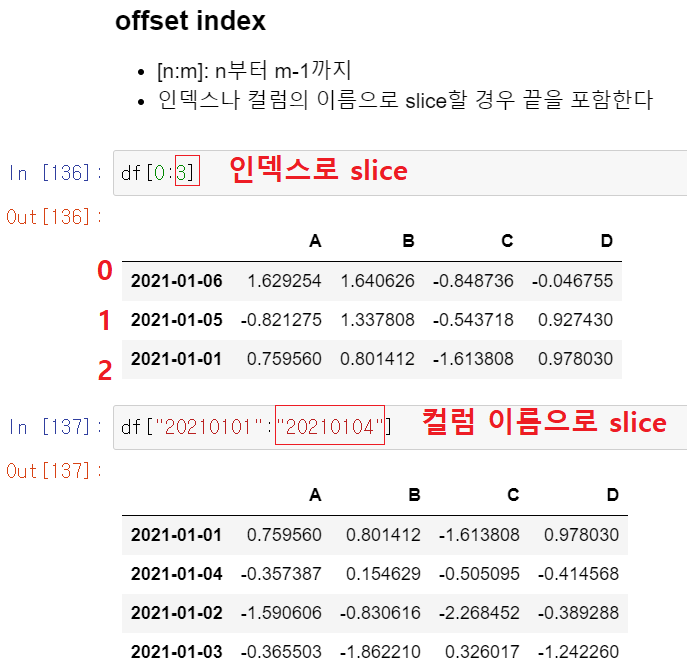
df.loc[인덱스명:[컬럼명]]
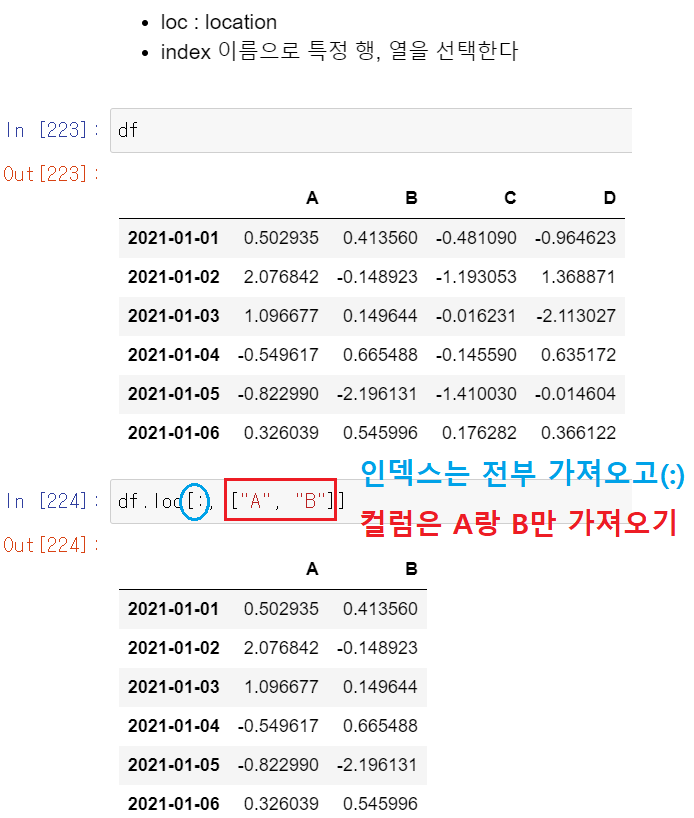
( 비교 해보기 ---> 인덱스명 직접 입력하기 ) 
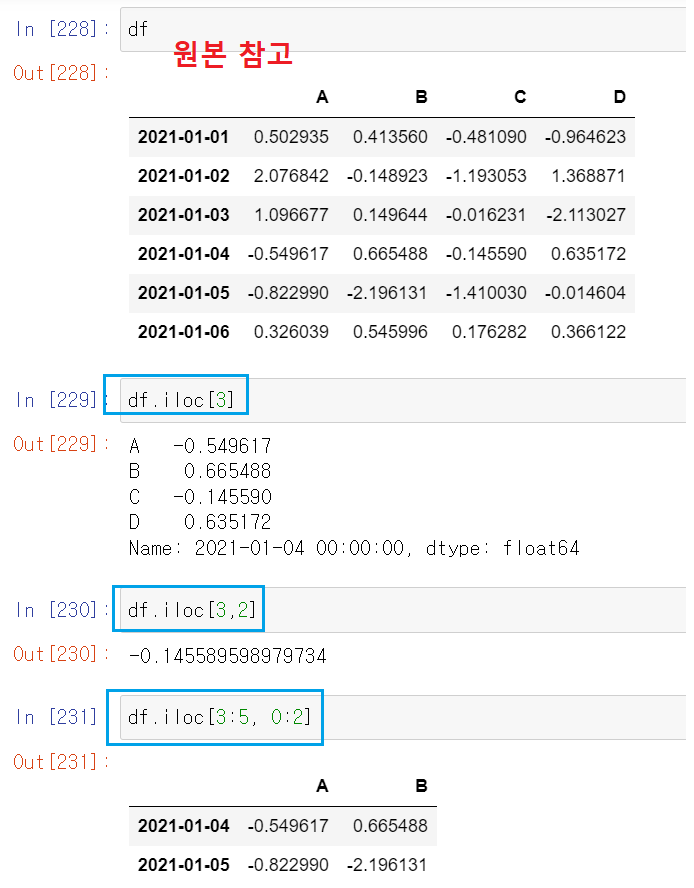
df.iloc
- inter location : 컴퓨터가 인식하는 인덱스 값에 따라 선택(모든 숫자는 0부터 시작)

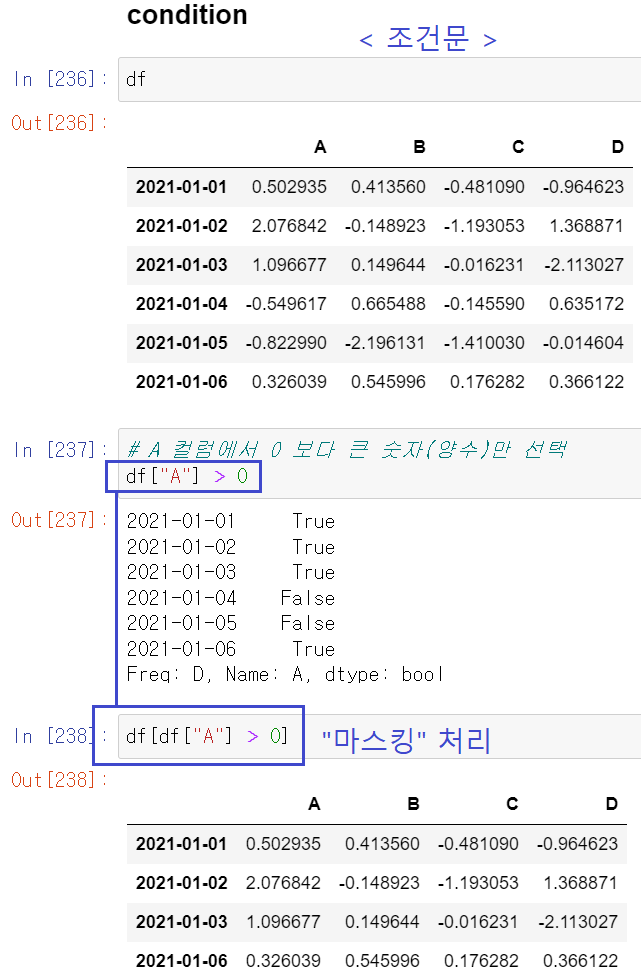
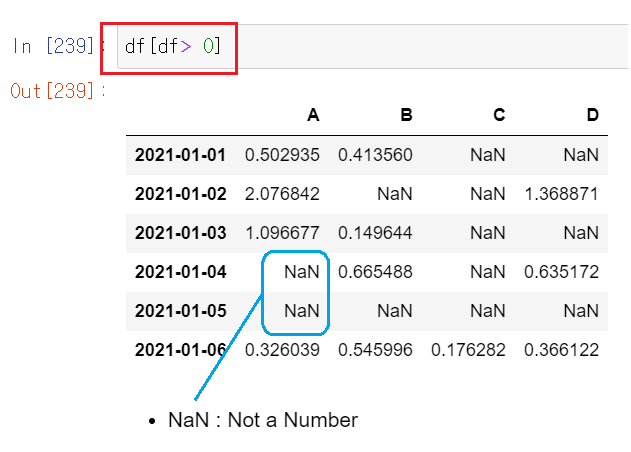
- 데이터 프레임에서 조건 설정하기
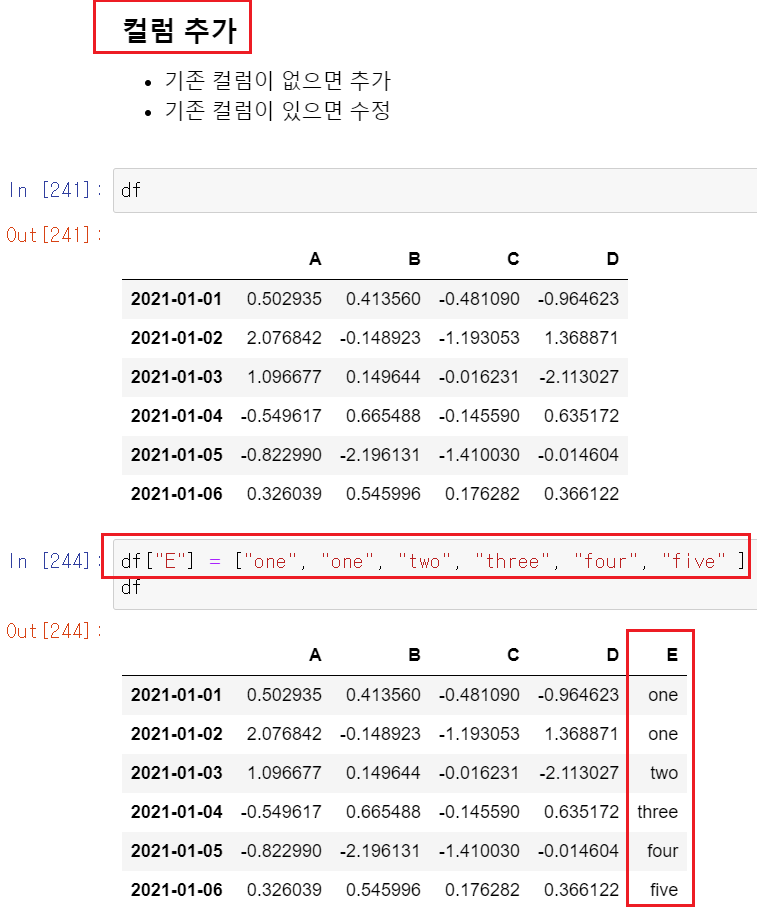
- 컬럼 추가하기
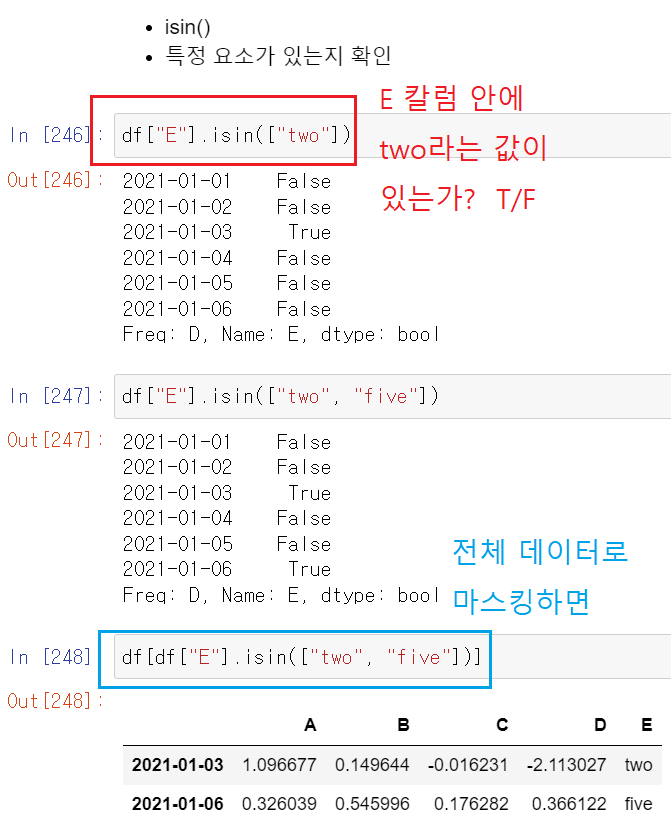
isin
- 특정 값이 포함되어 있는지 확인하는 메서드
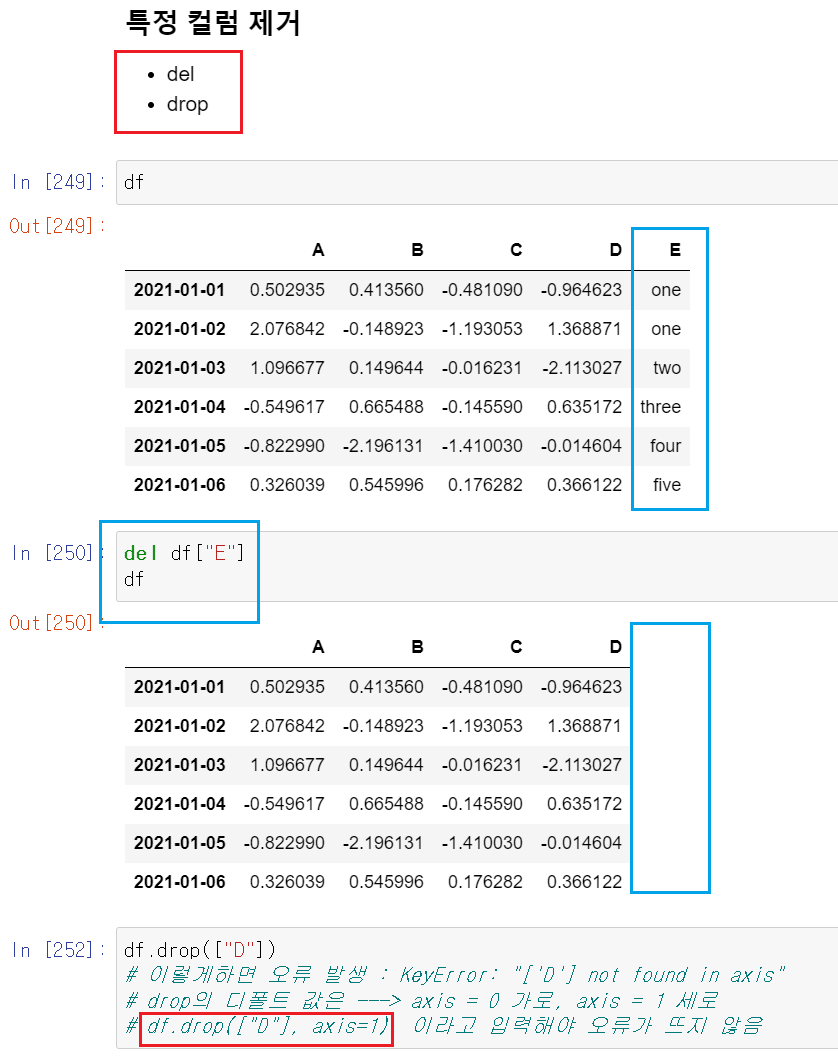
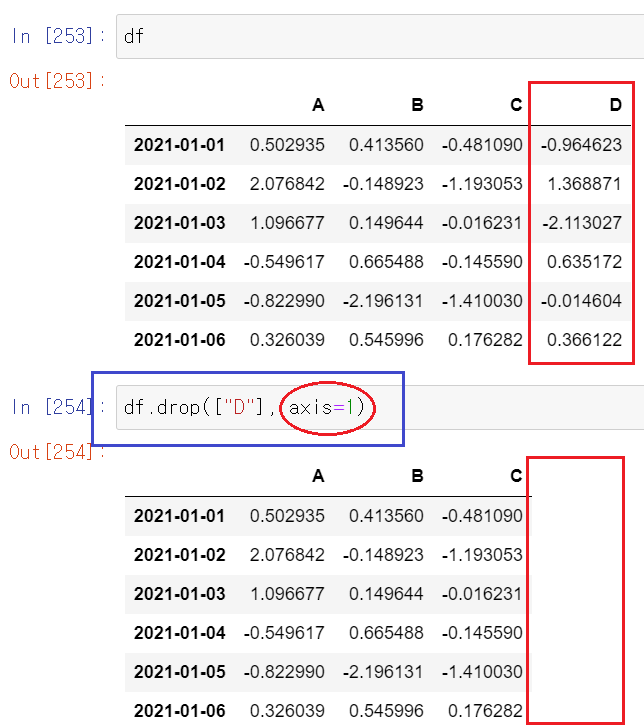
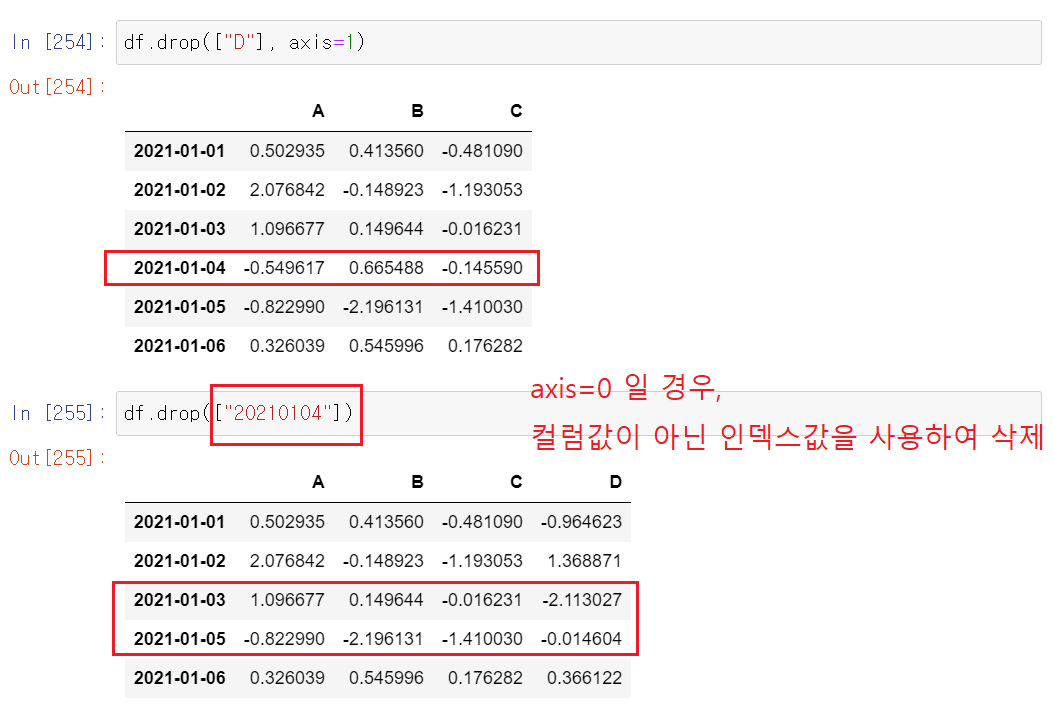
del 또는 drop
- 특정 컬럼 제거하기
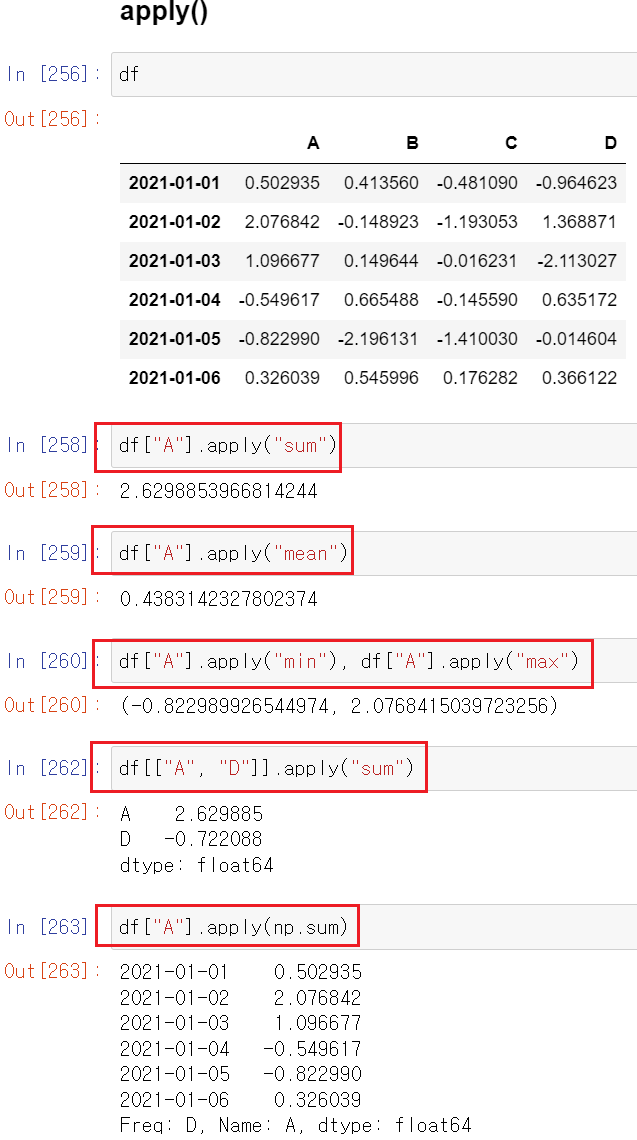
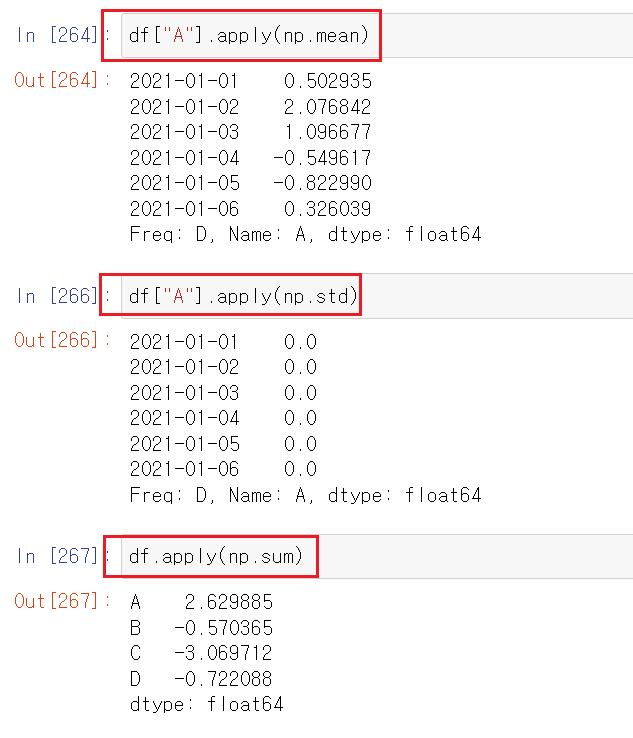
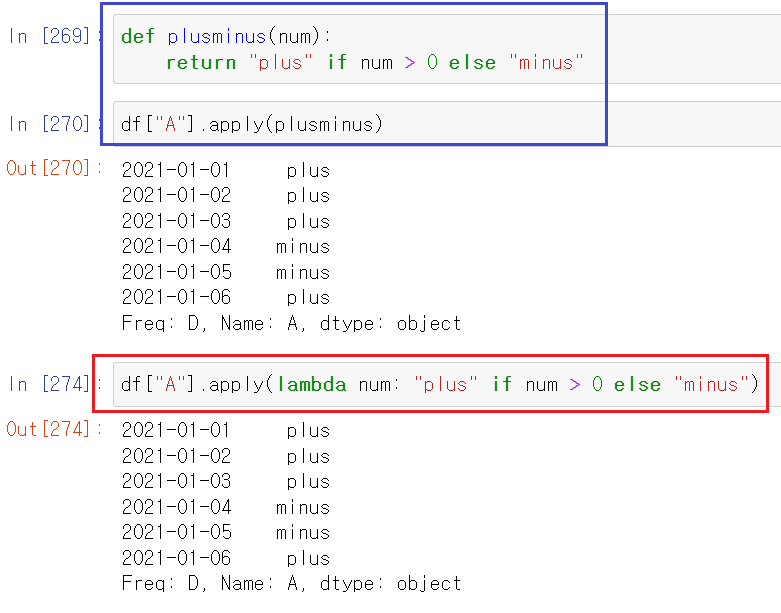
apply()
- numpy를 기반으로 내장된 함수를 적용하여 반환