오늘 강의에서는 N+1 문제를 다루었다.
N+1 문제가 무엇인지, 왜 발생하는지, 어떻게 해결하는지를 정리해보려고 한다.
🌱 N+1 문제란?
N+1 문제는 JPA를 쓰다보면 한 번쯤은 겪게 되는 대표적인 성능 문제이다.
즉, 1번의 조회 쿼리 이후에 연관된 엔티티를 조회하기 위해 추가 쿼리가 발생하는 문제를 말한다.
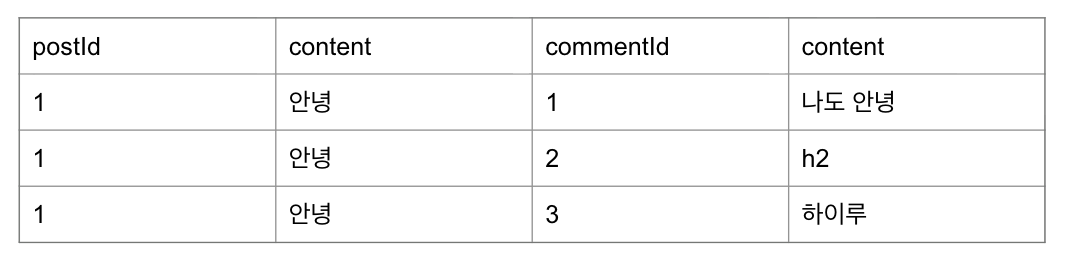
예를 들어, 전체 게시글을 조회할 때 각 게시글의 댓글 정보까지 연관 엔티티로 가져온다고 해보자.
List<Post> posts = postRepository.findAll();
for (Post post : posts) {
System.out.println(post.getComments().size());
}위 코드는 다음과 같이 동작한다.
1️⃣ 1번 쿼리: SELECT * FROM post(전체 게시글 가져오기)
2️⃣ N번 쿼리: SELECT * FROM comment WHERE post_id = ?가 게시글 수만큼 반복(댓글 가져오기)
먼저 모든 게시글을 조회하는 쿼리가 1번 발생한다.
그 다음에 하나의 게시물 마다 속한 모든 댓글을 불러오는 쿼리가 게시글 개수만큼 발생한다.
만약 게시글이 100개, 1000개, ...개, N개가 된다면 게시물 개수만큼 1+N개의 쿼리가 발생하게 된다.
그래서 개인적으로는 N+1 문제보다는 1+N 문제라고 하는게 더 와닿는 것 같다.
이해를 위해 예시를 하나만 더 들어보자.
게시글을 10개를 조회한다고 할 때, 각 게시글의 작성자 정보를 연관 엔티티로 가져온다고 해보자.
게시글 목록(10개의 게시글)을 가져오는 쿼리가 1번 + 작성자 정보(게시글 당 1번씩)를 불러오는 쿼리가 10번, 총 11번의 쿼리가 실행되는 것이 대표적인 N+1 문제이다.
🚨 N+1 문제는 왜 생기는걸까?
JPA에서 연관된 엔티티는 기본적으로 지연 로딩(LAZY) 방식으로 동작한다.
즉, 실제로 해당 데이터를 사용하는 시점에 추가 쿼리가 실행되는 것이다.
🌱 해결 방법
🥕 fetch join
Fetch Join이란 연관된 엔티티를 한 번의 쿼리로 함께 조회하기 위한 JPQL 키워드이다.
@Query("SELECT p FROM Post p JOIN FETCH p.comments")
List<Post> findAllWithComments();JOIN FETCH를 사용하면 지연 로딩 설정이 되어 있더라도 단 한 번의 쿼리로 연관된 엔티티를 즉시 로딩(EAGER)할 수 있다.
연관된 엔티티들을 SQL의 JOIN으로 함께 가져오기 때문에 추가 쿼리가 발생하지 않는다.
다만 1:N 관계에서는 중복 row가 생기므로 DISTINCT를 사용하거나 애플리케이션에서 중복을 제거해줘야 한다.
@Query("SELECT DISTINCT p FROM Post p JOIN FETCH p.comments")
List<Post> findAllWithComments();🚨 Fetch Join 주의 사항
- 2개 이상의 연관 관계를 동시에 가져올 경우 조인 결과가 폭발할 수 있어 JPA는 1개 이상의 컬렉션 Fetch Join을 허용하지 않는다.
- 중복된 결과로 인해
Pageable이 정상 동작하지 않을 수 있어 페이징 처리 시 fetch join은 부적절하다.
🥕 @EntityGraph
@EntityGraph는 Spring Data JPA에서 지원하는 기능으로, 연관 관계를 JPQL 없이 즉시 로딩(EAGER)하도록 지정할 수 있다.
@EntityGraph(attributePaths = "comments")
List<Post> findAll();JPA 구현체가 내부적으로 fetch join과 유사하게 처리하며, JPQL 작성 없이 선언적으로 해결이 가능하다는 장점이 있다.
또 @EntityGraph는 페이징(Pageable)과 함께 사용 가능하다.
그러나 동적 제어가 어렵고 복잡한 쿼리에는 한계가 있다.
다중 연관 필드 로딩 시에는 다음과 같이 하면 된다.
@EntityGraph(attributePaths = {"comments", "authors"})
List<Post> findByTitleContaining(String keyword);🥕 BatchSize
BatchSize는 Hibernate 설정을 통해 컬렉션 또는 연관된 엔티티들을 배치로 로딩할 수 있게 해주는 기능이다.
즉, LAZY 로딩이더라도 미리 설정된 개수만큼 한 번에 불러오게 해준다.
JPA에서는 LAZY 로딩 전략이 기본이기 때문에 연관된 엔티티들을 개별 쿼리로 가져오며, 이로 인해 N+1이 발생한다고 했다.
BatchSize는 이런 상황에서 Hibernate가 여러 엔티티를 한 번에 조회할 수 있도록 돕는 설정이다.
즉, LAZY 로딩 전략을 유지하면서도 IN 절을 활용한 일괄 조회가 가능해진다.
설정 방법에는 두 가지가 있다.
1️⃣ 글로벌 설정(application.yml)
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 1002️⃣ 개별 설정(엔티티 또는 컬렉션 필드)
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
@BatchSize(size = 100)
private List<Post> posts = new ArrayList<>();글로벌 설정 사용 시 프로젝트 전체에 적용된다.
⛔ BatchSize 설정 전: N+1 발생
SELECT * FROM user;
SELECT * FROM post WHERE user_id = ?; // 유저 수만큼 반복됨 N+1✅ BatchSize 설정 후: IN 쿼리로 최적화
SELECT * FROM user;
SELECT * FROM post WHERE user_id IN (1, 2, 3, ..., 100);🚨 Batch Size 주의 사항
- Batch Size 크기가 너무 작으면 효과가 미미하고, 너무 크면 IN 쿼리가 길어져 성능이 저하될 수 있다.
- Fetch Join과 함께 사용하면 안 된다.
- 이 설정은
LAZY인 경우에만 유효하다.
🥕 DTO Projection
DB에서 원하는 컬럼만 선택하여 DTO로 직접 매핑하는 방식이다.
✅ 예시 1
@Query("SELECT new com.example.dto.UserDto(u.username, u.age) FROM User u")
List<UserDto> findAllUserDto();✅ 예시 2
@Query("""
SELECT new org.example.nbcam_addvanced_1.domain.post.model.dto.PostSummaryDto(
p.content,
SIZE(p.comments)
)
FROM Post p
WHERE p.user.username = :username
""")
List<PostSummaryDto> findAllWithCommentsByUsername(String username);DTO Projection을 사용하면 필요한 데이터만 조회가 가능하고 불필요한 연관 로딩이 방지된다.
그러나 엔티티가 아니기 때문에 변경 감지가 불가능하고, 복잡한 로직 포함이 어렵다.
DTO Projection을 활용하면 불필요한 Entity -> DTO 변환 작업 없이 바로 DTO 파일로 필요한 정보를 받을 수 있다.
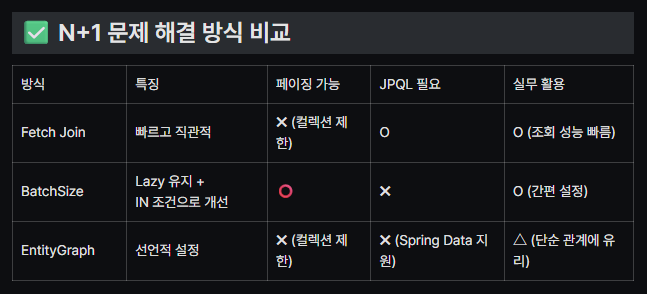
🌱 N+1 문제 해결 방법 비교


시작부터 졸면서 들어가네요 내용은 유익하니 개추드립니다 ^ㅂ^b