
텍스트 byte 제한
텍스트 내 한글자씩 escape() 함수를 이용해 인코딩하여 한글인지 영문, 숫자, 특수문자인지 판별한다.
function getTextTotalByte(str) {
let totalByte = 0;
const isKorean = char => escape(char).length > 4;
[...str].forEach((oneChar, i) => {
if (isKorean(oneChar)) {
totalByte += 2;
} else {
totalByte += 1;
}
});
return totalByte;
}이 때, 영문, 숫자 그리고 특수문자의 경우 보통 3개이하로 나오기 때문에 4보다 클 경우 한글이라고 판단하고 byte를 2씩 증가시켜주어 글자의 총 byte 값을 알 수 있었다.
escape() 인코딩 시,
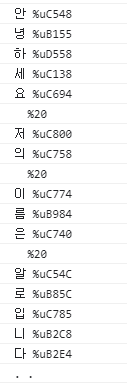
그리고 위의 함수에서 원래 text를 maxByte만큼 잘라줘야 하기 때문에 maxLen값을 추가적으로 반환해줘야 한다.
const test = 'hello my name is Arlo.';
const test2 = '안녕하세요 저의 이름은 알로입니다.';
export function getTextTotalByte(str, maxByte) {
let totalByte = 0;
let maxLen = 0;
const isKorean = char => escape(char).length > 4;
[...str].forEach((oneChar, i) => {
if (isKorean(oneChar)) {
totalByte += 2;
} else {
totalByte += 1;
}
if (totalByte <= maxByte) maxLen += 1;
});
return { totalByte, maxLen };
}
export function textByteOverCut(text, maxByte = 20, lastText = '...') {
let changeText = text;
const { totalByte, maxLen } = getTextTotalByte(text, maxByte);
if (totalByte > maxByte) {
changeText = text.substr(0, maxLen) + lastText;
}
return changeText;
}위의 코드를 이용해 바이트로 제한하여 글자 수를 조절할 수 있다.
console.log(textLengthOverCut(test, 25));
// hello my name is Arlo.
console.log(textLengthOverCut(test2, 25));
// 안녕하세요 저의 이름은 알...