https://arxiv.org/pdf/1901.02860.pdf
https://medium.com/@mromerocalvo/dissecting-transformer-xl-90963e274bd7
결론: Transformer 를 긴 sequence length 에 적용할 수 있게 개선했고, 잘 된다.
Transformer 모델은 Attention mechanism으로 강력한 성능을 가질 수 있지만,
sequence length가 한정적인 문제가 있음
sequence length를 넘어가는 document를 다루는 방법에 관한 논문임
두 가지 아이디어가 있음
-
hidden state를 재활용
-
이전 segment의 hidden state를 가져와 현재 segment의 hidden state를 생성하는 과정에서 사용함
-
RNN 의 방식과 유사하지만 RNN은 수평 방향으로만 hidden state를 누적한다면, Transformer는 layer 방향으로도 누적하는 차이가 있음. 따라서, 더 긴 sequence를 고려해 임베딩 생성이 가능함
-
Training 과정에서 두 개의 segment를 이런식으로 과거 embedding을 고려해 현재 embedding을 생성하도록 함
-
이때 backpropagation은 과거 시점의 파라미터에 대해서는 수행하지 않음
(RNN 처럼 backpropagation through time 하지 않겠다는 뜻) -
과거 시점의 embedding은 재활용 (cache) - 빠른 속도
-
-
Relative positional encoding
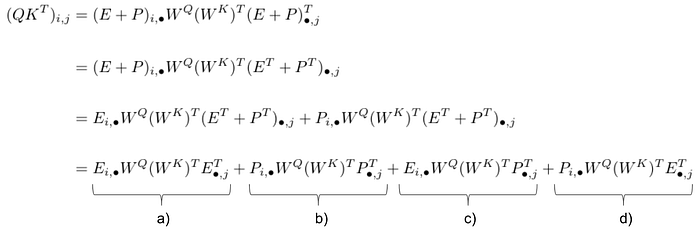
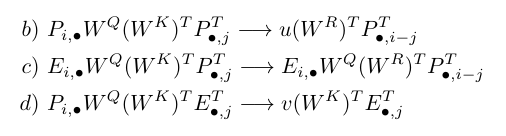
Pi,* 는 i 번째 position 의 positional embedding
Ei,* 는 i 번째 position 의 word embedding
u, v 는 absolute postional embedding이 중요하지 않으므로 임의의 학습가능한 vector로 치환한 것
absoulute positioal embedding 대신 i 번째와 j 번째의 상대적 차이를 고려한 relative positional embedding을 사용 (P*,i-j)
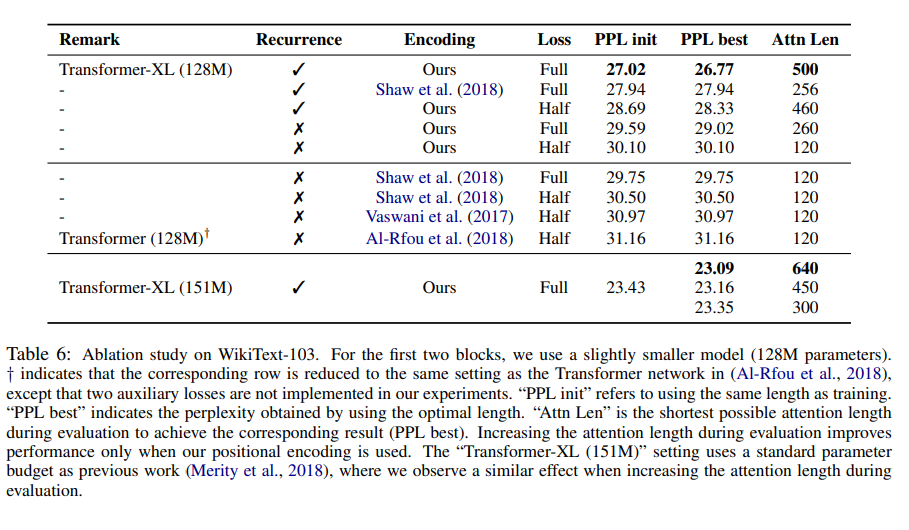
3.Results
- word 개수가 많은 document도 잘 학습함 (low perplexity) - WikiText-103
(= language modeling을 수행함) - 길이가 긴 text에 대해서도 잘 모델링 한다
WikiText-103 is the largest available word-level
language modeling benchmark with long-term dependency