CPU 스케줄링, 프로세스, 동시성에 대한 글입니다.
W01 프로젝트 소감
OS의 역할
- CPU 스케줄링
- priority 구현
스레드 vs 프로세스
- 문맥전환과 시스템콜
동기화
- 동기화 문제: 공유자원과 임계영역(Critical Section)
- 세마포어, 뮤텍스/락
- 우선순위 역전 및 priority donation
프로젝트 소감
운영체제가 제공하는 핵심 중 하나인 프로세스에 대해 배웠다.
관건은 "누가 CPU 자원을 점유할 것인가"인데,
이는 Ready_list를 어떤 방식으로 정렬하느냐,
그리고 누가 lock을 가지고 semaphore에 접근하느냐에 따라 결정된다.가장 원초적인 형태의 Alarm clock은 timer_sleep으로 각 스레드에 깨어날 시간을 지정하여 잠재운 후, 시간이 되면 Ready_list 맨 뒤로 추가하여
결국엔 가장 먼저 도착한 스레드가 next_thread_to_run이 되는 FIFO 방식이다.그러나 실제로는 작업들이 서로 다른 우선순위를 갖고 있기에
우선순위가 높은 순으로 레디큐를 정렬하여, 맨 앞 원소가 RUNNING 스레드 바로 다음으로 올 수 있도록 한다.눈여겨볼 점은 '선점형' 방식(Priority_Preemption)인데,
새로 생성된 스레드가 현재 RUNNING 스레드보다 우선순위가 높다면 바로
thread_yield()를 함으로써 CPU 자원을 내주어야 한다.
과제 측정지표
- Alarm clock: idle tick 갯수
- 기존 busy/waiting의 경우 주어진 tick만큼 thread_yield()가 발생해 쉴새없이 문맥전환이 일어나지만
- sleep/wake_up 기반 alarm clock의 경우 timer_sleep()을 호출한 스레드를 sleep_list를 따로 관리하고 시간이 다 되었을 때만 깨움으로서 커널이 할 일이 줄어드는 셈이며, 이는 곧 'idle tick' 개수가 많아짐을 뜻한다.
- Priority: 테스트 케이스를 보면 set_priority()로 설정한 우선순위 대로 wake_up 하는지 체크한다.
void test_max_priority(void)
{
if (!list_empty (&ready_list) &&
thread_current()->priority
< list_entry(list_front(&ready_list), struct thread, elem)->priority)
thread_yield();
}
void
thread_set_priority (int new_priority) {
thread_current ()->init_priority = new_priority;
refresh_priority();
test_max_priority();
}- 우리가 구현에 집중한 부분은 다음과 같다.
- Alarm Clock: Sleep_list
- Priority Scheduling: Ready_list
- Priority Donation: Donation_list
- 세번째 파트에서 추가로 신경써줘야 했던 부분은 공유자원(CPU)을 점하기 위해 '락'을 획득한 후 sema_down/up을 해줘야 한다는 점,
- 락을 해제할 때는 sema_up으로 끝나는 게 아니라 donation_list를 업뎃하면서 자신의 우선순위도 재조정해줘야 한다는 것이다.
CPU 스케줄링
- Preemptive vs Non-preemptive (선점 vs 비선점)
- Preemptive: CPU가 어떤 프로세스가 실행하고 있는데 강제로 새로운 것을 실행할 수 있는 스케줄링 방법- Non-preemptive: 프로세스가 끝나거나 I/O를 만나기 전엔 종료할 수 없음
핀토스에서는 대부분 Preemptive 방식의 스케줄링을 구현했다.
Alarm clock에서는 타이머 인터럽트를 통해 interrupt handler를 실행하고, 이 시점에 운영체제는 CPU 제어권을 얻어 원하는 일을 할 수 있다.
이는 현재 잠들어있는 스레드 중 awake할 시간이 다 된 스레드를 깨워서 Ready_list로 보내는 작업 등이 있다.
즉, 현재 CPU를 점하고 있는 스레드가 무한루프에 빠지더라도 인터럽트가 매 틱마다 발생하므로 이를 중단하고 관여할 수 있는 것이다.
static void
timer_interrupt (struct intr_frame *args UNUSED) {
ticks++;
thread_tick (); // update the cpu usage for running process
thread_awake(ticks);
}void
thread_awake(int64_t ticks)
{
struct list_elem *e = list_begin(&sleep_list);
/* sleep_list를 처음부터 끝까지 돌면서 */
while (e != list_end(&sleep_list))
{
struct thread *t = list_entry(e, struct thread, elem); // thread 구조체 포인터 t
if (t->wakeup_tick <= ticks){ // 깨울 대상
e = list_remove(e); // sleep_list에서 e 제거 후 next를 리턴
thread_unblock(t); // 스레드 t UNBLOCK
}
else
e = list_next(e); // sleep_list 계속 탐색
}
}Priority Scheduling 구현
-
스케줄링 척도
- 성능: 반환시간(Shortest-Job-First), 응답시간
- 공정성: Round Robin(타임슬라이스로 쪼개 돌면서), 도착순(FIFO)
- 최근 패턴: MLFQ(하나를 오래 점유할수록 우선순위 낮춤)
- 기본적으로 성능 기준. 반환시간(completion time - arrival time)이 짧으면 일단 우선적으로 수행.
- 그러나 공정성을 고려하면 time slicing을 하여 돌아가면서 실행시키는 Round Robin 방식이 적합하기도. 응답시간이 빠르다는 장점.
-
next_thread_to_run( )이 핵심
- 레디큐의 맨 앞 원소(elem)를 가져오는 함수
- 레디큐를 정렬하는 방식이 여러개일 뿐. 이번 프로젝트에선 priority 순 정렬
-
구현 고려사항
- ready_list(레디큐)에 넣을 때 우선순위에 맞게 넣음.
- 레디큐에 넣는 경우는 다음 두 가지
- thread_yield()
- thread_unblock()
- 레디큐는 항상 정렬된 상태 유지
Thread vs Process
문맥전환(Context Switching)
- 운영체제는 어떻게 프로그램 실행을 중단하고 다른 프로세스로 전환할 수 있는가? CPU 가상화에 필요한 time sharing 기법을 어떻게 구현하는가?
- 제한된(Limited)' 연산: 프로세스가 디스크 읽기(I/O)와 같은 특권이 필요한 명령을 실행할 때, 사용자 모드가 아닌 커널 모드가 관여
- 모든 프로세스가 자신만의 CPU를 가지고 마음대로 접근할 수 있는 것 처럼 보이지만, 실제로는 CPU를 점유하거나 메모리를 읽고 쓸 때마다 시스템콜을 발생시켜 커널을 통해야 함
- 커널은 그 과정에서 기존 상태를 복원하기 위한 데이터 저장 용도로, 스레드 또는 프로세스의 커널스택 영역을 사용함
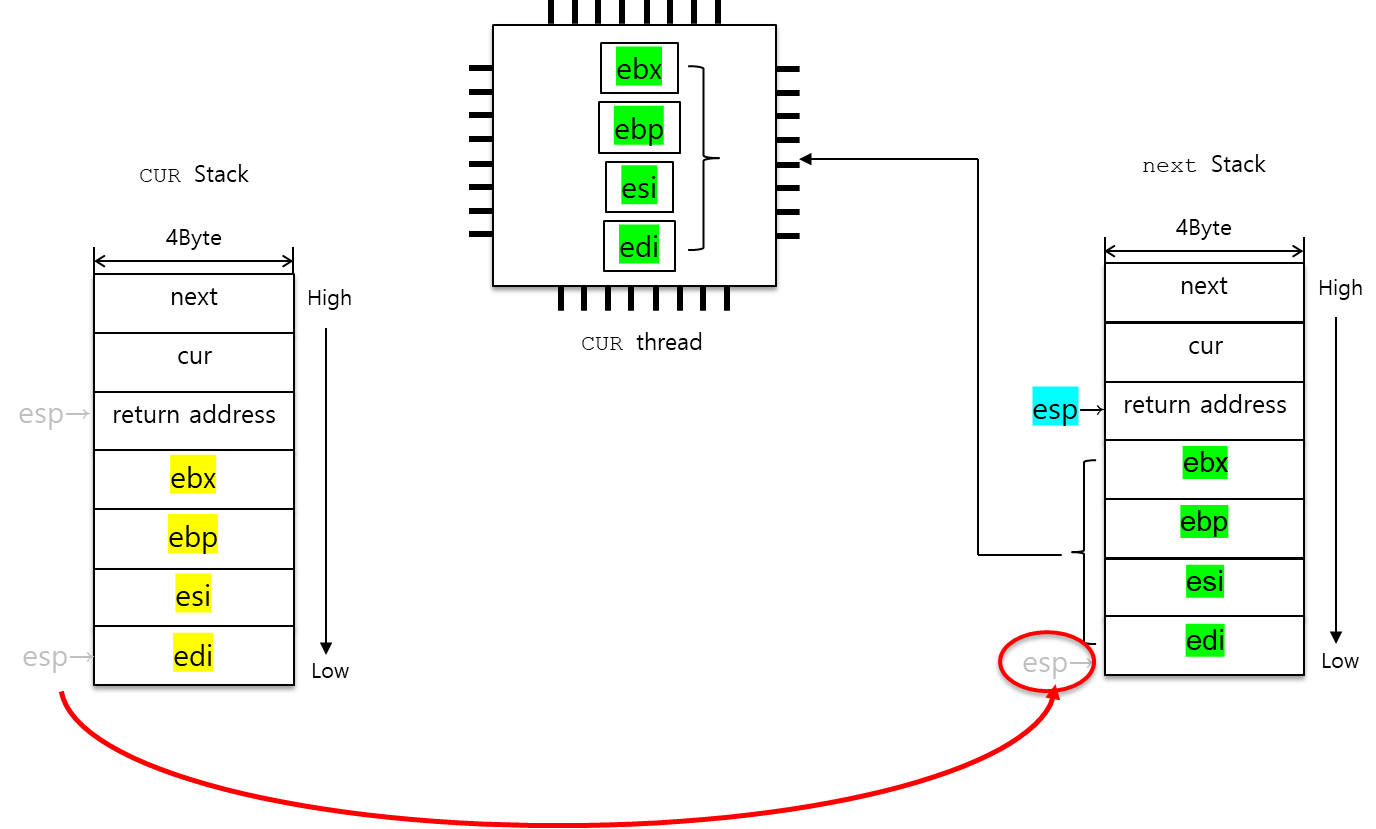
문맥전환과 시스템콜
- 한 프로세스에서 다른 프로세스로 넘어갈 때, 시스템콜을 통해 유저모드가 아닌 커널모드에서 실행된다는 점에 주목.
- schedule(): thread_yield() 내 실제로 문맥전환이 일어나는 함수. 현재 CPU 레지스터에 담긴 실행환경(execution context)을 current 스레드 커널스택에 저장하고, %esp를 offset을 통해 next 스레드로 넘겨 next 스레드의 실행환경을 커널스택에서 pop하여 CPU 레지스터에 넣음.
- 기존 실행환경을 current(지금은 prev) 스레드 커널스택에 저장함으로써 다시 그 스레드로 리턴했을 때 동일한 환경으로 복원 가능.
switch_threads:
pushl %ebx
pushl %ebp
pushl %esi
pushl %edi
.globl thread_stack_ofs
mov thread_stack_ofs, %edx
movl SWITCH_CUR(%esp), %eax
movl %esp, (%eax,%edx,1)
movl SWITCH_NEXT(%esp), %ecx
movl (%ecx,%edx,1), %esp
popl %edi
popl %esi
popl %ebp
popl %ebx
ret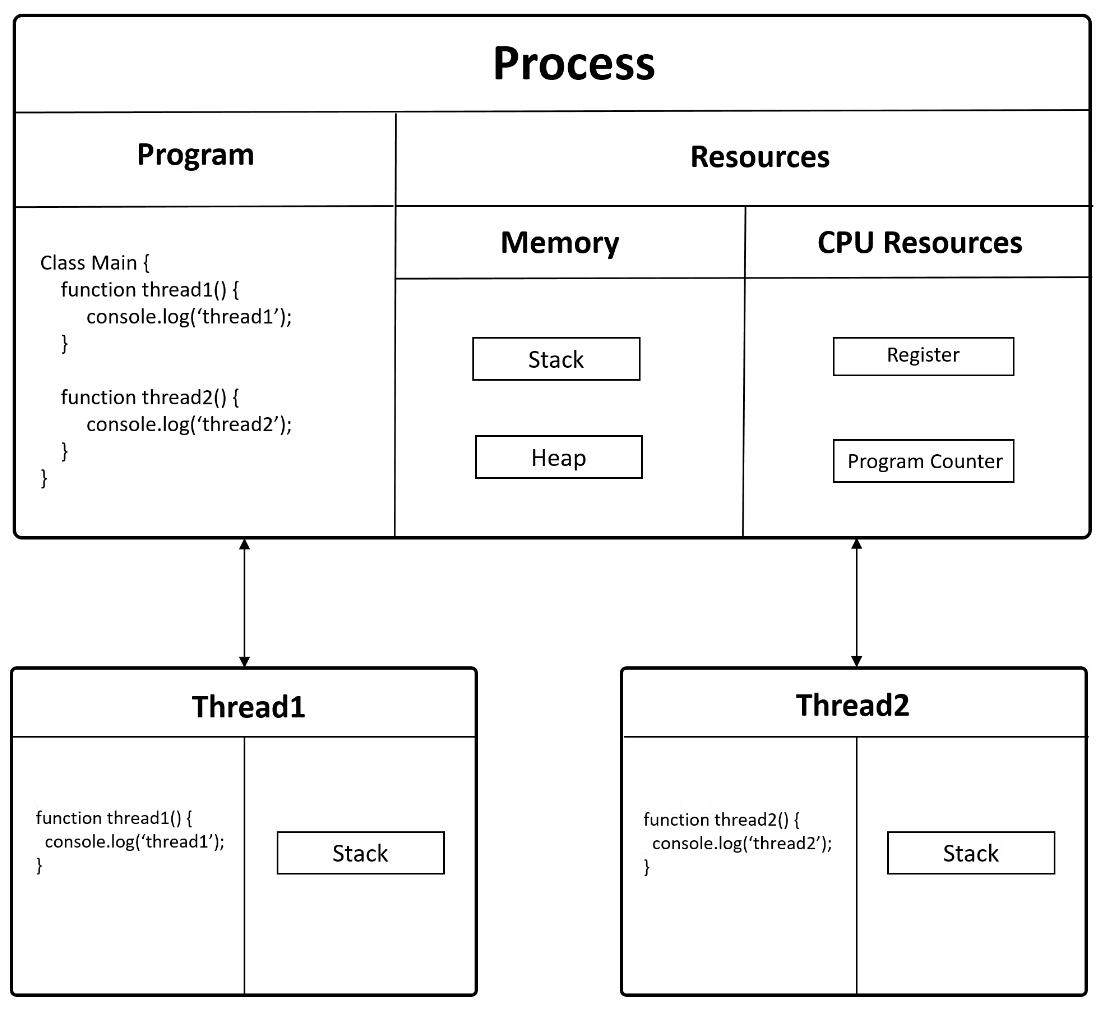
-
프로세스
- 메모리(RAM)에 올라와 실행되고 있는 프로그램의 인스턴스로, 각각의 독립된 메모리 영역(Code, Data, Stack, Heap 구조)을 할당받음
- 각 프로세스는 별도의 주소공간에서 실행되며, 한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스간의 통신(IPC, inter-process communication)을 사용해야 함
-
스레드
- 프로세스내 실행되는 여러 흐름의 단위
- 스레드는 프로세스내 각각 Stack만 따로 할당받고 Code, Data, Heap은 공유
- 스레드 사이 작업량이 작아 Context Switching이 빠름
-
정리하자면 Context switching 비용 측면에서 스레드가 우위. 프로세스는 Context 전환시 메모리 접근이 필요한데, 스레드는 각자의 스택과 CPU 레지스터단에서 빠르게 스위칭이 이뤄질 수 있음
-
동시성은 CPU가 한 번에 하나의 일만 처리할 수 있지만, child process/thread를 통해 병렬적으로 처리하기 위함
- 기본적으로는 순차적 실행을 하되, I/O 처리가 일어나야 할 때 스레드에 맡기고 끝나면 다시 메인 스레드에서 작업
동기화(Synchronization)
임계영역(Critical Section)
- 동기화가 왜 필요한가?
- 공유 데이터에 동시적으로 접근하면 data inconsistency 발생
- 공통변수(common variable)에 대한 동시 업데이트 (concurrent update)
- 하이레벨 언어로는 1줄이지만 로우한 언어에선 여러 줄. 도중에 스위칭 발생
- 공유 데이터에 동시적으로 접근하면 data inconsistency 발생
- 세마포어, 뮤텍스/락
- 한 번에 한 쓰레드만 업데이트하도록(Atomic)
- 같이 사용하는 것들을 write, update, change하는 경우 Critical section에 진입하는 순간 P, 나갈 때 V로 sema 값을 바꿔주어, 다른 스레드들이 그 조건이 충족될 때만 진입할 수 있게 함 (condition variable은 각각 wait(), signal()에 해당)

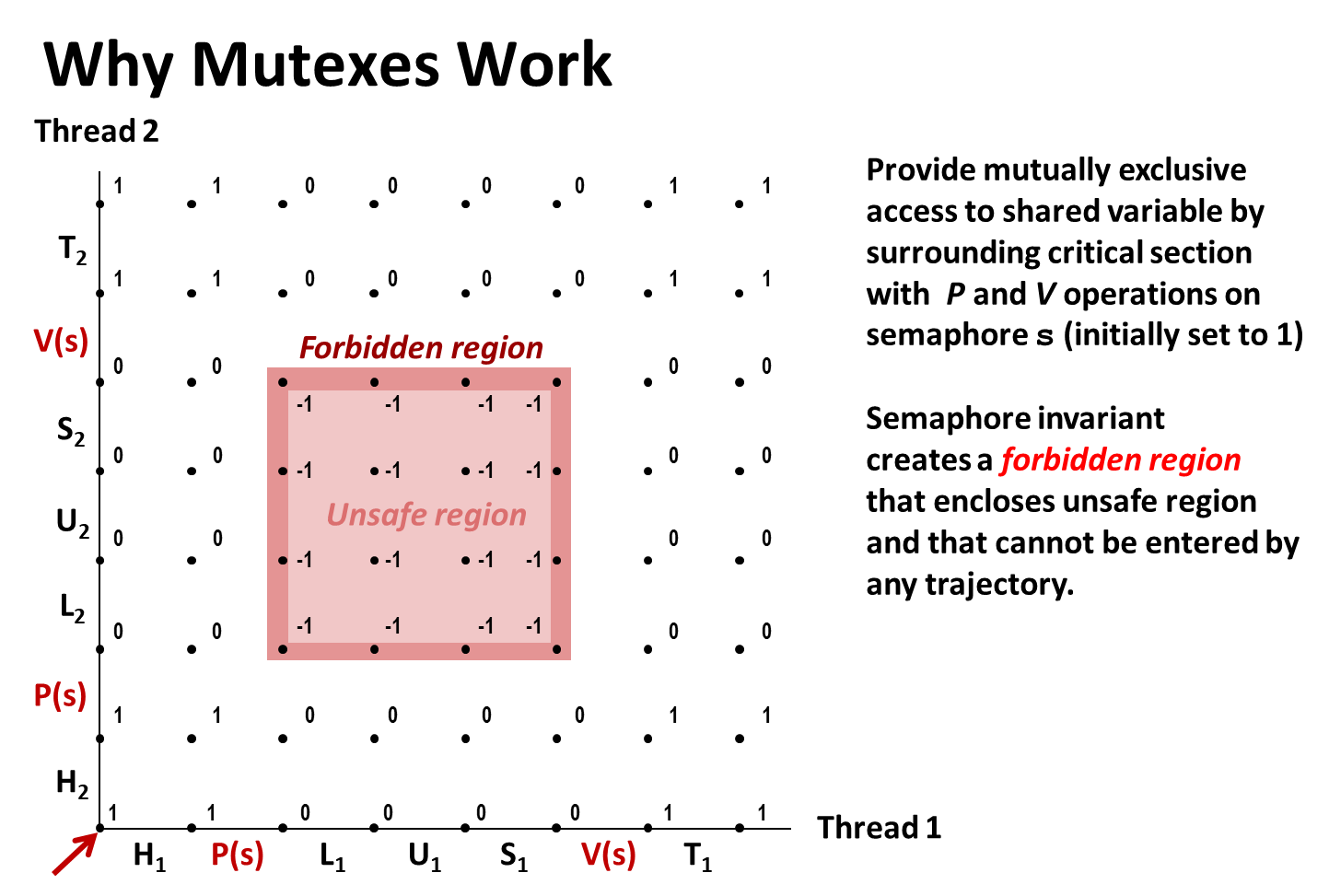
세마포어
- Semaphore
- P(acquire), V(release)
- P는 sema_value를 -1 낮추고 V는 +1
- 내부적으로는 프로세스(쓰레드)가 대기하는 큐(queue/list)가 포함되어있음
void
sema_down (struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
ASSERT (!intr_context ());
old_level = intr_disable ();
while (sema->value == 0) {
list_insert_ordered (&sema->waiters, &thread_current()->elem,
cmp_donate_priority, 0);
thread_block ();
}
sema->value--;
intr_set_level (old_level);
}세마포어 vs lock
- 세마포어는 단일 소유자가 없음. 한 스레드가 down 시키면 다른 스레드가 up 가능
- 락은 획득한 스레드만이 해제할 수 있음
- 세마포어는 "접근할 수 있냐 없냐"의 문제고, 락은 지금 누가 컨트롤하고 있느냐에 대한 것
- 결국 sema를 컨트롤해야 공유자원에 접근할 수 있으나, 동시에 여러 스레드가 접근하려 하면 race condition이 발생하므로 lock이라는 장치를 두어 lock holder만이 해당 semaphore에 접근할 수 있도록 한 것
struct semaphore {
unsigned value; /* Current value. */
struct list waiters; /* List of waiting threads. */
};
struct lock {
struct thread *holder; /* Thread holding lock (for debugging). */
struct semaphore semaphore; /* Binary semaphore controlling access. */
};
우선순위 역전 및 priority donation
우선순위 역전
- 높은 우선순위 작업이 낮은 우선순위 작업이 소유한 공유자원을 기다리는 상황
- 아래 그림은 Thread H의 우선순위가 더 높음에도 lock 때문에 blocked 되어있다가 lock이 풀리자마자 더 낮은 우선순위의 Thread M이 lock을 획득하여 우선순위가 역전된 상황을 보여줌
- 어떤 스레드가 공유자원에 대한 lock을 갖고 있는 시간이 Critical section에 해당. 다른 스레드도 공유자원에 접근하려면 그 lock을 획득해야 함.

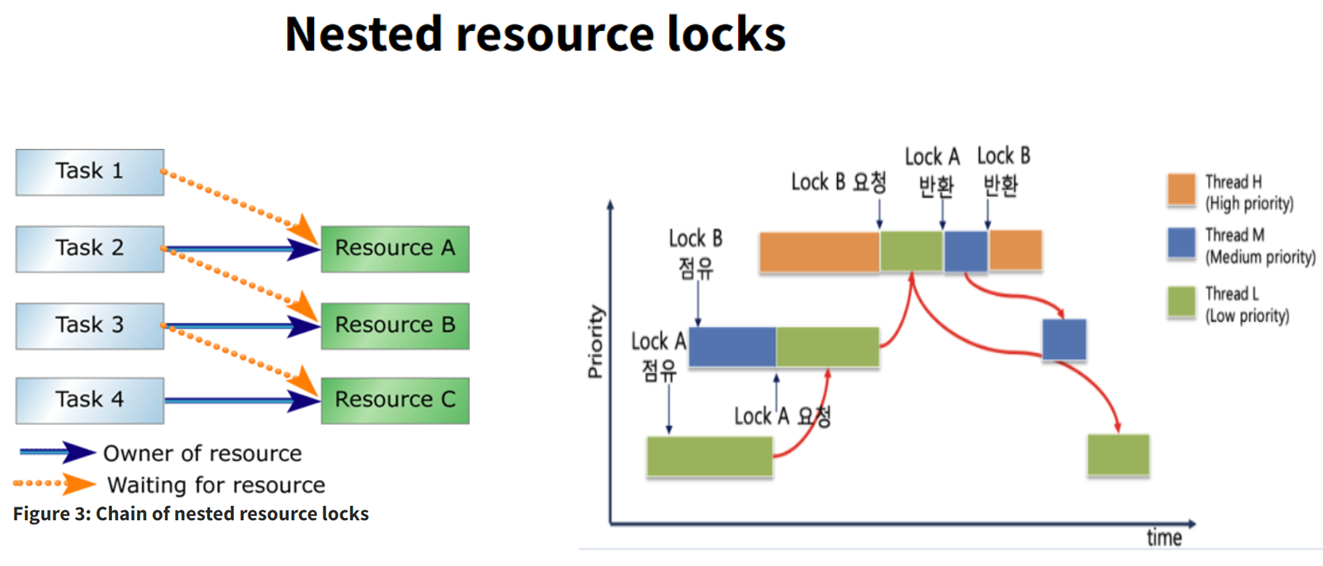
Nested Donation
- 문제는 nested donation. 아래 그림의 경우, 높은 우선순위의 Task1이 리소스 A를 요청할 경우, 그걸 소유한 Task2는 다른 리소스B를 요청하고 있고. 결과적으로는 맨 아랫단 Task4가 리소스C에 대한 lock을 해제해야만 거슬러올라가 Task1이 작업을 시작할 수 있음
- 이 경우 어쩔 수 없이 리소스A에 대한 락이 풀릴 때까지 기다려야 함.
- 다만 중간에 더 낮은 우선순위 Task가 와서 해제된 락을 채가지 못하도록 차순위 Priority로 계속 업데이트 해주어야 함.
구현 사항 두 가지
- Chain of inheritance:
- lock_acquire()에서 for loop로 donate_priority().
최대깊이 8번으로 제한
- lock_acquire()에서 for loop로 donate_priority().
- lock_release():
- donations 리스트에서 락을 넘겨준 스레드 제거 후 차순위 priority로 업데이트
-> 이는 multiple donation과 관련
- donations 리스트에서 락을 넘겨준 스레드 제거 후 차순위 priority로 업데이트
lock_acquire()
void
lock_acquire (struct lock *lock) {
...
if (lock->holder) {
cur->wait_on_lock = lock;
list_insert_ordered(&lock->holder->donations, &cur->donation_elem,
cmp_donate_priority, NULL); // priority 순대로 donation list로 대기
donate_priority();
}
// lock 획득 (lock holder가 lock_release를 호출)
sema_down (&lock->semaphore);
thread_current()->wait_on_lock = NULL;
lock->holder = cur; // lock holder 갱신
}
void
donate_priority(void)
{
int depth;
struct thread *cur = thread_current();
for (depth = 0; depth < 8; depth++){
// 다른 스레드에 의해 락이 걸려있지 않다면 종료
if (!cur->wait_on_lock) break;
// 락이 걸려있으면, 해당 스레드에 기부
struct thread *holder = cur->wait_on_lock->holder;
holder->priority = cur->priority;
cur = holder; // curr = curr.next
}
}
lock_release()
void
lock_release (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (lock_held_by_current_thread (lock));
lock->holder = NULL;
// donation list 변경 및 cur 우선순위 재설정
remove_with_lock(lock);
refresh_priority();
lock->holder = NULL;
sema_up (&lock->semaphore);
}
void
refresh_priority(void)
{
struct thread *cur = thread_current();
cur->priority = cur->init_priority;
if (!list_empty(&cur->donations)) {
list_sort(&cur->donations, cmp_donate_priority, 0);
struct thread *front = list_entry(list_front(&cur->donations), struct thread, donation_elem);
if (front->priority > cur->priority)
cur->priority = front->priority;
}
}
/* newly created thread 고려 */
void
thread_set_priority (int new_priority) {
thread_current ()->init_priority = new_priority;
refresh_priority();
test_max_priority();
}