데이터 병합: concat, merge, join
- concat(): 단순한 연결, 위아래로 합치기 (axis=0)
# concat
import pandas as pd
df1 = pd.DataFrame({'A' : ['A0', 'A1'], 'B': ['B0', 'B1']})
df2 = pd.DataFrame({'A': ['A2', 'A3'], 'B': ['B2', 'B3']})
result = pd.concat([df1, df2])
print(result)
# 출력
A B
0 A0 B0
1 A1 B1
0 A2 B2
1 A3 B3- merge(): 공통된 컬럼이나 인덱스를 기준으로 테이블 병합
# merge inner: 교집합
df_a = pd.DataFrame({'key': ['K0', 'K1', 'K2'], 'A': ['A0', 'A1', 'A2']})
df_b = pd.DataFrame({'key': ['K0', 'K2', 'K3'], 'B': ['B0', 'B2', 'B3']})
result = df_a.merge(df_b, how='inner')
print(result)
# 출력
key A B
0 K0 A0 B0
1 K2 A2 B2
# merge outer: 합집합
result = pd.merge(df_a, df_b, on='key', how='outer')
print(result)
# 출력
key A B
0 K0 A0 B0
1 K1 A1 NaN
2 K2 A2 B2
3 K3 NaN B3
# merge left: 왼쪽 기준 병합
result = pd.merge(df_a, df_b, on='key', how='left')
print(result)
# 출력
key A B
0 K0 A0 B0
1 K1 A1 NaN
2 K2 A2 B2
# merge right: 오른쪽 기준 병합
result = pd.merge(df_a, df_b, on='key', how='right')
print(result)
# 출력
key A B
0 K0 A0 B0
1 K2 A2 B2
2 K3 NaN B3- join(): 데이터프레임의 인덱스를 기준으로 병합
df3 = pd.DataFrame({'A' : ['A0', 'A1'], 'B': ['B0', 'B1']})
df4 = pd.DataFrame({'A': ['A2', 'A3'], 'B': ['B2', 'B3']})
df_3.join(df_4, lsuffix='_3', rsuffix='_4')
# 출력
A_3 B_3 A_4 B_4
0 A0 B0 A2 B2
1 A1 B1 A3 B3
df_3 = df_3.set_index('key')
df_4 = df_4.set_index('key')
df_3.join(df_4, how='inner')
#출력
A_3 B_3 A_4 B_4
key
K0 A0 B0 A2 B2- 데이터 합칠 때 생길 수 있는 문제
salary_df = pd.concat([salary_1, salary_2])
salary_df.loc[0]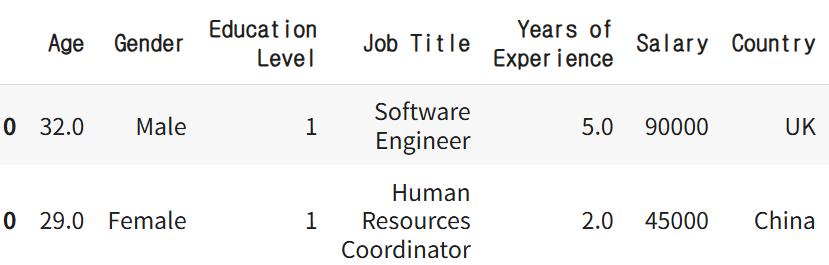
0번째 인덱스가 2개가 생겼음. 이처럼 모든 인덱스가 2개씩 존재하는 문제 발생
# 해결방법
# 인덱스 리셋
salary_df.reset_index(drop=True)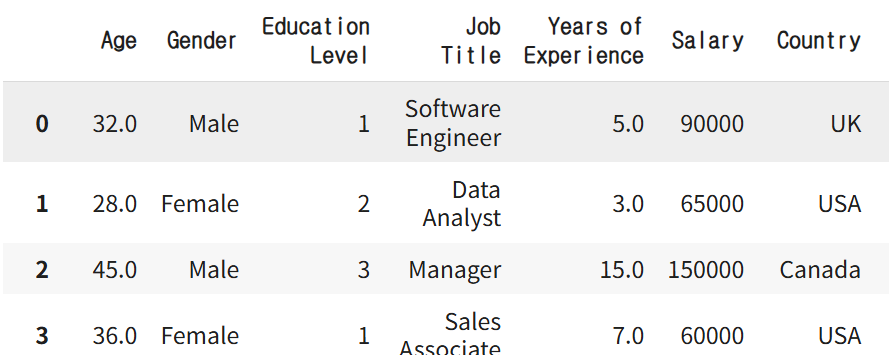
# 국가 이름 통일시키기
cpi['Country'] = cpi['Country'].replace({'United States':'USA','United Kingdom':'UK'})
# 기존의 데이터를 기준으로 새로운 cpi 데이터 merge
salary_df = salary_df.merge(cpi, on='Country', how='left')
# 컬럼 지우기
# inplace=True: 원본이 수정됨
salary_df.drop(['Reference','Previous','Units','Frequency'],axis=1, inplace=True)
오늘 배운 것을 기록하며, 나만의 지식으로 만들어가는 성장 일지 💪🍀