최근 분산된 서버들의 로그를 통합 관리하는 중앙 모니터링 시스템을 구축했습니다. 시스템 규모가 커지면서 실시간으로 유입되는 대량의 로그 데이터는 DB에 상당한 부하를 줄 수 밖에 없습니다.
로그 데이터는 장애 추적과 보안을 위한 핵심 자산이기에 데이터 유실 최소화와 고부하 환경에서의 안정성은 필수입니다. 단순히 로그 수집 서버를 이중화하는 것만으로는 DB 자체의 병목 현상이나 단일 장애점(SPOF) 문제를 해결할 수 없기에 DB의 고가용성(HA) 확보와 부하 분산을 위한 DB 이중화를 적용하게 되었습니다.
🔎 DB 이중화의 필요성
데이터베이스(DB) 이중화는 말 그대로 DB 서버를 두 대 이상으로 운영해 데이터의 안전성을 높이고 부하를 나누는 기술입니다.
만약 DB가 single로 구성되어 있다면?
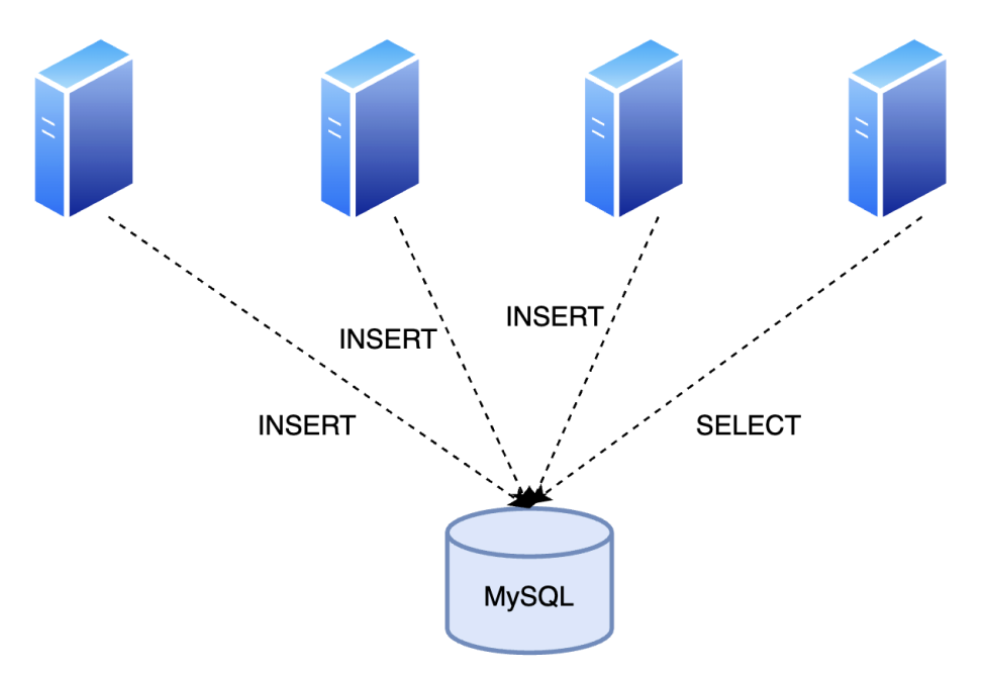
모든 시스템이 단일 DB 서버에만 의존할 경우, 해당 서버에서 하드웨어 결함이나 네트워크 장애가 발생하면 DB가 복구 완료될 때까지 모든 시스템의 데이터 저장 및 조회가 중단됩니다. 이는 서비스 전체가 마비되고, 서비스의 가용성(Availability) 저하와 직면하는 심각한 장애로이어집니다.
이러한 단일 장애점(SPOF, Single Point of Failure) 문제를 해결하기 위해 도입하는 것이 바로 DB 이중화입니다.
🔎 이중화를 통해 얻는 3가지 이점
1. 고가용성(High Availability) 확보
메인 DB 서버에 문제가 발생하더라도 복제된 예비 서버가 즉시 업무를 이어받아(Failover), 서비스 중단 시간을 최소화하고 24시간 중단 없는 서비스를 제공합니다.
2. 데이터 무결성 및 안전성
실시간으로 데이터를 복제하여 관리하므로, 예상치 못한 서버 파손이나 데이터 유실 상황에서도 최신 데이터를 안전하게 보존할 수 있습니다.
3. 시스템 부하 분산
대량의 로그가 유입되는 환경에서 쓰기(Write) 작업과 읽기(Read) 작업을 여러 서버로 분산 처리함으로써, 단일 서버에 가해지는 병목 현상을 해결하고 전체적인 시스템 성능을 향상시킵니다.
🔎 MySQL Replication: 비동기 복제 방식의 이해
이번 프로젝트에서는 MariaDB(MySQL 계열)를 활용해 이중화를 구현했습니다. MySQL은 '주_복제본(Master-Slave)' 구조의 비동기 복제 방식을 지원합니다.
-
Master (Source) : 데이터의 변경(CUD)이 발생하는 원본 서버
-
Slave (Replica) : Master의 데이터를 복제하여 읽기(Read) 요청을 처리하는 서버
이 구조를 통해 쓰기와 읽기의 병목 현상을 효과적으로 완화할 수 있습니다.
MySQL 복제 원리 (Replication Workflow)
데이터가 Master에서 Slave로 전달되는 과정은 다음과 같이 4단계로 요약할 수 있습니다.
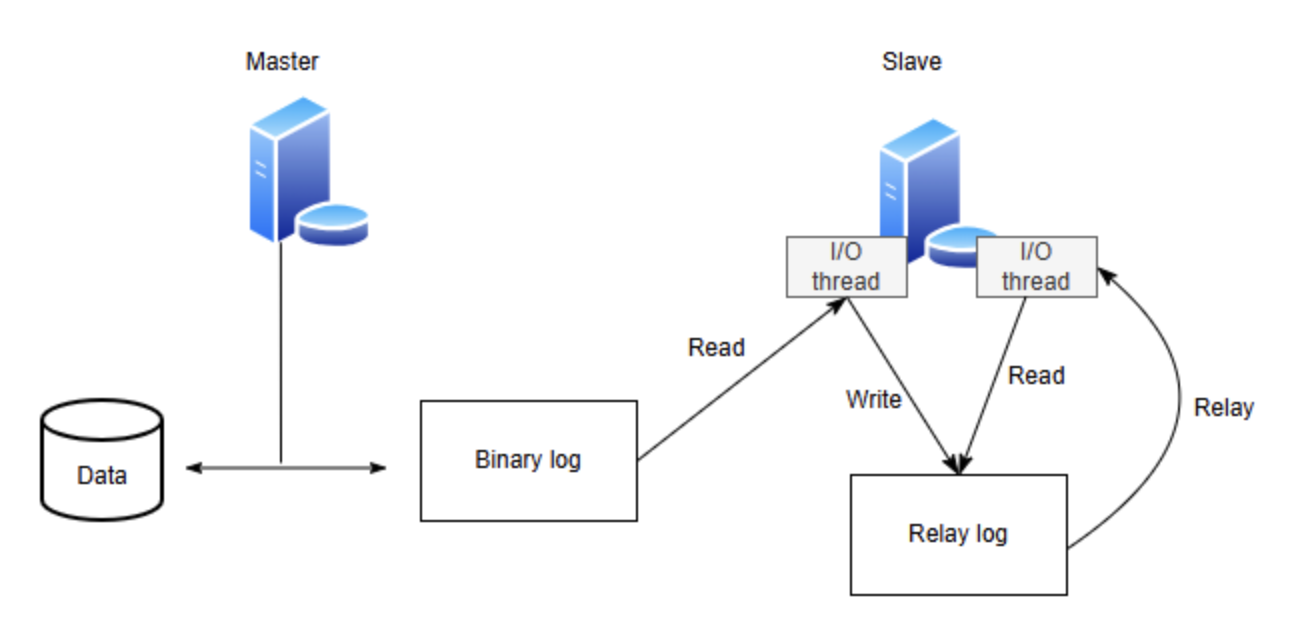
- Binary Log 기록 : Master 서버에서 데이터 변경이 발생하면 해당 내용을 바이너리 로그(Binary log)에 기록합니다.
- 로그 전송 : Master Thread가 비동기적으로 바이너리 로그를 읽어 Slave 서버로 전송합니다.
- Relay Log 기록 : Slvae의 I/O Thread는 Master로 부터 받은 데이터를 릴레이 로그(Relay log)에 기록합니다.
- 최종 반영: Slave의 SQL Threa가 릴레이 로그를 읽어 자신의 스토리지 엔진에 데이터를 최종 적용합니다.
MySQL Replication 구현
1. Mariadb 설치 및 파일 설정
# dnf install -y mariadb 먼저 mariadb 를 설치한 후, DB 설정 파일(/etc/my.cnf.d/mariadb-server.cnf)에서 Replication을 위한 설정을 해줍니다.
-> 설정 파일 수정 후 DB 재시작
[mysql]
# 1. 서버 고유 ID (Slave와 중복 X)
server_id=1
# 2. 바이너리 로그 활성 및 파일명 지정
log-bin=mariadb-bin
# 3. GTID(Global Transaction ID) 사용 설정
gtid_domain_id=0
# 4. 읽기 전용 설정 (운영 실수 방지) - Slave에만 설정
read_only=1 -
server_id=1 : 복제 그룹 내에서 각 서버를 식별하는 고유 번호로 Master와 Slave는 반드시 서로 다른 번호를 부여해야 합니다.
-
log_bin=mariadb-bin : 모든 데이터 변경 사항(CUD)을 기록하는 바이너리 로그를 활성화합니다. 이 로그 파일이 있어야 Slave가 내용을 읽어갈 수 있습니다.
-
gtid_domain_id=0 : 트랜잭션이 발생하는 영역(Domain)을 구분해주는 ID입니다.
-
read_only=1 : Slave 서버에서 사용자가 직접 데이터를 수정하는 것을 막습니다. 복제 데이터의 일관성을 유지하기 위해 Slave는 반드시 읽기 전용으로 두는 것이 현업의 규칙입니다.
📝 GTID란?
복제되는 모든 트랜젝션에 부여되는 '고유 번호'로 여러 대의 서버가 서로 데이터를 주고받다보면 트랜잭션의 흐름이 꼬일 수 있으므로 이때 영역을 구분해줘야 한다.
2. 복제 계정 생성 (Master에서 실행)
Slave 서버가 Master에 접속해서 로그를 가져갈 수 있도록 전용 권한을 가진 계정을 만들어야 합니다.
-- 복제 전용 계정 생성
CREATE USER 'repl'@'%' IDENTIFIED BY '비밀번호';
-- 복제 권한 부여
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
-- 권한 적용
FLUSH PRIVILEGES;3. 복제 시작 (Slave에서 실행)
이제 Slave 서버에서 Master를 바라보도록 Replication 명령을 내립니다.
CHANGE MASTER TO
MASTER_HOST='마스터_IP',
MASTER_USER='repl',
MASTER_PASSWORD='비밀번호',
MASTER_USE_GTID=slave_pos; -- GTID 방식을 사용하겠다는 의미
START SLAVE;4. 정상 작동 확인
모든 설정을 마쳤고, 실제로 Slave가 Master의 데이터를 잘 가져오는지 확인해보겠습니다.
-- Slave 서버에서 실행
SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_Running: Yes <-- Master 로그를 잘 가져오고 있는가?
Slave_SQL_Running: Yes <-- 가져온 로그를 DB에 잘 반영하고 있는가?Slave_IO_Running과 Slave_SQL_Running 이 모두 Yes로 되어있어야 Replication이 정상적으로 동작하는 것을 의미합니다. 만약 Master 서버의 바이너리 로그를 제대로 받아오지 못한다면 Error 부분에 표시되는 오류 내용을 확인하여 조치 할 필요가 있습니다.
마무리
지금까지 DB 이중화의 개념과 MySQL Replication을 직접 구현하는 방법에 대해 알아보았습니다.
Master-Slave 구조를 통해 읽기와 쓰기 트래픽을 분리함으로써 단일 DB 환경에서 발생하던 병목 현상을 상당 부분 해소할 수 있었습니다. 하지만 이 방식만으로는 Master 서버의 장애 라는 근본적인 위험을 해결할 수 없습니다. 여젼히 모든 쓰기 작업은 단 하나의 Master 서버에 의존하기 때문에 만약 Master 서버에 장애가 발생하면 복구전까지 데이터 유실과 다운 타임을 피할 수 없습니다.
그래서 다음 포스팅에서는 이러한 문제를 보완하기 위해 Slave 서버를 새로운 Master로 즉시 승격시켜 서비스 연속성을 보장하는 방법을 다뤄보려 합니다. 지능형 프록시인 MariaDB MaxScale을 활용해 수동 관리의 번거로움을 덜고 고가용성(HA)을 구현하는 과정을 살펴보겠습니다.
