
시작.
pintos를 딱 시작하면 뭐 해야하지 라는 생각이 매우 크게 든다.
그럼 시작 전에 알면 좋은 지식과 배경 지식을 학습해보자
pintos가 뭘까
진짜 OS임! OS니까 커널이 있음!
→ 직접 커널을 만들고, 그걸 부팅해서 디버깅하는 프로젝트!!!
즉
Pintos는 운영체제(OS)의 근본 개념을 직접 구현하고 실험해보는 학습 플랫폼. 단순히 이론을 배우는 것이 아니라, 다음과 같은 핵심 기능을 직접 만들어보며 체득할 수 있도록 구성
- 스레드 관리와 CPU 스케줄링
- 시스템 콜 처리
- 사용자 프로세스 실행
- 가상 메모리 관리
- 파일 시스템 구현
pintos의 디렉터리 구조
pintos/
├── threads/ ← Project 1: 스레드, 스케줄링, 동기화
├── userprog/ ← Project 2: 사용자 프로그램 실행, 시스템 콜
├── vm/ ← Project 3: 가상 메모리
├── filesys/ ← Project 4: 파일 시스템
├── devices/ ← I/O 장치 코드 (공통 사용)
├── lib/ ← Pintos 내부 라이브러리
├── lib/kernel/ ← 커널 전용 라이브러리
├── tests/ ← 프로젝트별 테스트
├── examples/ ← 사용자 프로그램 예제
└── Makefile ← 빌드 설정디렉터리 구조도 한번 알아보자.
pintos의 환경!
QEMU??
CPU, 메모리를 가짜로 만들어서 운영체제를 실행시켜주는 에뮬레이터/가상화 도구!
- x86, ARM, RISC-V 등 다양한 CPU 아키텍처 에뮬레이션 가능
- 실제 하드웨어 없이도 리눅스, 윈도우, 커널 등 실행 가능
- 주로 커널 개발, OS 연구, 크로스 플랫폼 테스트에 많이 씀
시스템 계층 구조를 알아보자!
┌──────────────────────────────────────┐
│ 물리 하드웨어 (Host PC) │
│ ┌────────────────────────────────┐ │
│ │ 도커 (우분투(코드 작성,컴파일)) │ │
│ │ ┌──────────────────────────┐ │ │
│ │ │ QEMU (가상 CPU 등) │ │ │
│ │ │ ┌────────────────────┐ │ │ │
│ │ │ │ Pintos 커널 (C로 짠) │ │ │ │
│ │ │ └────────────────────┘ │ │ │
│ │ └──────────────────────────┘ │ │
│ └────────────────────────────────┘ │
└──────────────────────────────────────┘(도커기준) 전체 흐름을 알아보자
우분투 (개발환경)
└── 코드 작성 + 컴파일 (make)
└── kernel.bin 생성
└── QEMU 실행 (pintos 스크립트가 실행)
└── QEMU 안에서 Pintos 커널 부팅
└── Pintos 안에서 테스트 실행중요한 것.
우리는 우분투,도커의 환경에서 코딩을하고, 컴파일을하고, 기타 등등 활동을 진행!
make check를 통해 QEMU를 실행하는 것!! 그 위에 pintos 커널을 돌리는 것!!!!!!
우분투에서 프로그램을 실행시켜본다 생각하면 편하다!!
Pintos는 리눅스에서 실행되는 게 아니라, QEMU에서 독립적으로 부팅되는 “OS 커널”이다.
단지 그 커널을 만들고 실행 명령 내리는 개발 환경이 우분투(리눅스)이다!
뭘 해야할까?
흐름만 파악해보자!!!!
| 단계 | 주제 | 구현 목표 | 학습 키워드 | 난이도 |
|---|---|---|---|---|
| 1 | Threads | 커널 수준 스레드와 스케줄러 구현 및 개선 | thread, priority scheduling, semaphore, lock, condition variable | ⭐ |
| 2 | User Programs | 사용자 프로그램 로딩, 시스템 콜 처리 | system call, process, exec, wait, user-kernel mode | ⭐⭐ |
| 3 | Virtual Memory | 가상 메모리 구조 및 페이지 교체 구현 | virtual address, page fault, page table, swap, lazy loading | ⭐⭐⭐ |
| 4 | File System | 파일 시스템 기능 구현 및 성능 향상 | inode, buffer cache, file descriptor, directory, disk I/O | ⭐⭐⭐⭐ |
Project 1: Threads
- 목표: 커널 스레드를 만들고, 스케줄링 정책을 직접 구현합니다.
- 해야 할 일:
thread_create()로 새로운 스레드 생성priority scheduling과alarm clock구현- 동기화 기법(
semaphore,lock,condvar) 이해 및 구현
- 핵심 학습: 병행성(concurrency), 스케줄러, 인터럽트 제어
Project 2: User Programs
- 목표: 사용자 프로그램을 로딩하고 시스템 콜 인터페이스를 구현합니다.
- 해야 할 일:
- ELF 바이너리 파싱하여 메모리에 로딩
exec,exit,wait구현- 파일 시스템 접근을 위한 시스템 콜(
read,write,open) 구현
- 핵심 학습: 사용자 모드 ↔ 커널 모드 전환, 인터럽트 핸들링, 프로세스 제어
Project 3: Virtual Memory
- 목표: 페이지 단위 메모리 관리, 스왑 및 페이지 교체 알고리즘 구현
- 해야 할 일:
page fault발생 시 핸들러 작성lazy loading,stack growth,swap-in/out구현- 페이지 교체 알고리즘 (
clock,FIFO등) 선택적 구현
- 핵심 학습: 주소 공간 구조, TLB, 페이지 테이블
Project 4: File System
- 목표: 파일 시스템을 개선하고 성능을 향상시킵니다.
- 해야 할 일:
- 파일 및 디렉터리 생성/삭제
inode,sector,block직접 다루기buffer cache로 성능 최적화
- 핵심 학습: 지속성(persistence), 디스크 I/O, 데이터 무결성
알면 좋은 내용!!
인터페이스? 레이어?
약속! 어떤 기능에 대한 약속과 추상화!!!
어떻게 사용지하는지 알지만 돌아가는 구조는 모르는 것!
| 인터페이스 종류 | 예시 |
|---|---|
| 프로그래밍 인터페이스 | 함수 호출, API, 메서드 명세 |
| 하드웨어 인터페이스 | USB 포트, HDMI |
| 소프트웨어 인터페이스 | 리눅스 시스템 콜, 라이브러리 헤더 |
| 사용자 인터페이스 | CLI, GUI, 앱 UI |
레이어?
자기 자신의 층만 보는 것!!!
기능을 분리하거나, 단계를 분리하는 것
레이어는 자기와 아래 단계 레이어만 생각하고 동작하는 것!!!!
- HTTP는 IP가 뭔지 몰라도 동작함
- IP는 전선이 뭔지 몰라도 패킷 보냄
→ 인터페이스 + 레이어 구조 덕분!!
즉!!!
- 어디를 공부 해야하고 봐야하는지 구분하고!
- 어디까지 알아야 하는지 판단하고
- 나의 레이어가 아닌 것은 인터페이스를 통해 잘 활용하기!!
- 내가 책임져야 할 부분을 구분하는 것! 아닌 부분은 신경쓰지 말기!!
레이어와 인터페이스를 구분하지 못하면!
1. 코드를 전체를 다 보다가 회사 짤리고!
2. 상위 기능을 고치면 아래의 기능이 망가지고!
3. 문제가 많이 생긴다!!!
pintos에서 보면?
- threads/, userprog/, vm/, filesys/ 는 각각 레이어
- 각 주제는 아레의 레벨을 감싸는 상위 인터페이스를 제공!
- 이 구조 덕분에, 하나만 집중해서 수정하고 분석 가능!
filesys/
↑
vm/
↑
userprog/
↑
threads/
즉!! 각 단계가 진행이 안된다면 다음 단계를 진행할 수 없음!!
다음 단계에서는 이전 단계를 함수 호출만 해서 사용!!| 레이어 | 주요 인터페이스 | 설명 |
|---|---|---|
| threads/ | thread_create, schedule, timer_sleep | 커널 스레드, 타이머 |
| userprog/ | process_execute, syscall_handler | 유저 프로그램 실행, 시스템 콜 |
| vm/ | vm_install_page, page_fault_handler | 페이지 매핑, 페이지 폴트 처리 |
| filesys/ | filesys_create, file_read, file_write | 파일 열고 쓰고 지우기 등 |
GDB에 대해서 알아보자
GNU 디버거(GNU Debugger)
-> 프로그램을 멈추고 하나하나 확인하는 것!
| 명령어 | 설명 |
|---|---|
| break <라인번호/함수> | 중단점 설정 |
| run | 프로그램 실행 |
| next / n | 다음 줄 실행 (함수 안으로는 안 들어감) |
| step / s | 다음 줄 실행 (함수 내부로 들어감) |
| continue / c | 다음 중단점까지 실행 |
| print <변수> | 변수 값 출력 |
| bt / backtrace | 함수 호출 스택 추적 |
| list | 현재 실행 위치 근처 코드 보기 |
| info locals | 지역 변수들 보기 |
| quit | GDB 종료 |
예시를 들어보자
ex) segmentation fault 발생
# 컴파일 할 때 디버깅 정보 넣기
gcc -g mycode.c -o myprog
# gdb ./myprog
# break → run → step → print
(gdb) break main # main 함수에 중단점 설정
(gdb) run # 실행
(gdb) step # 한 줄씩 실행
(gdb) print x # 변수 x 값 출력
# 에러 발생 부분 확인!
(gdb) backtrace # 함수 호출 스택 추적
# 이상한 포인터나 배열 접근이 있는지 확인
(gdb) list
(gdb) print ptrpintos에서 GDB 사용법
→ QEMU로 실행되니까 원격 디버깅 형태로 붙여한다
즉 호스트 컴퓨터에서 GDB써야한다! (원격으로 도커 안에 접속해서)
안에서 QEMU 실행 + 밖에서 GDB 연결” 이 원칙
아닐 수도 있음. 참고용.
Makefile, Build 시스템 구조
자동 빌드 스크립트! makefile을 읽고 어떤 파일을 컴파일할지 결정!
소스 → 목적 파일 → 실행 파일 흐름으로 진행
빌드 시스템 구조
📁 src/
└─ 📁 threads/
├─ Makefile ← 해당 디렉토리용 빌드 규칙
├─ *.c, *.h ← 소스파일
└─ 📁 build/ ← 생성된 목적파일과 실행파일
├─ *.o
├─ kernel.o
└─ kernel.bin ← 실제 커널 이미지포인터
포인터는 메모리 주소를 저장하는 변수
즉. 데이터의 값이 아니라 데이터가 있는 위치를 기억!
예시
int x = 42;
int *p = &x; // p는 x의 주소를 저장함x: 정수값 42를 저장&x: x의 주소p: x의 주소를 저장하는 포인터p: 포인터가 가리키는 값, 즉 42
pintos에서 포인터
구조체 리스트, 락 구조체, 페이지 테이블 항목에서 많이 쓰인다!
컴퓨터 흐름이랑 같이 보기
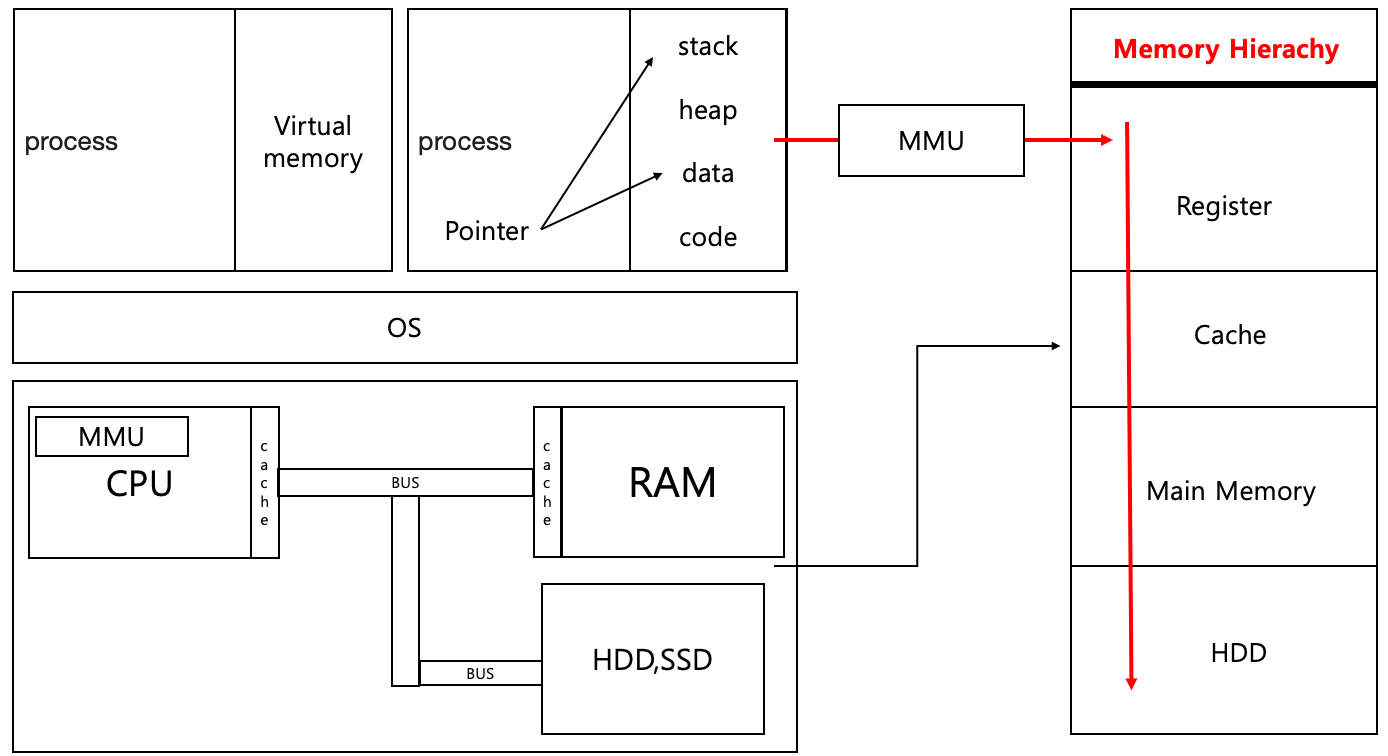
커널
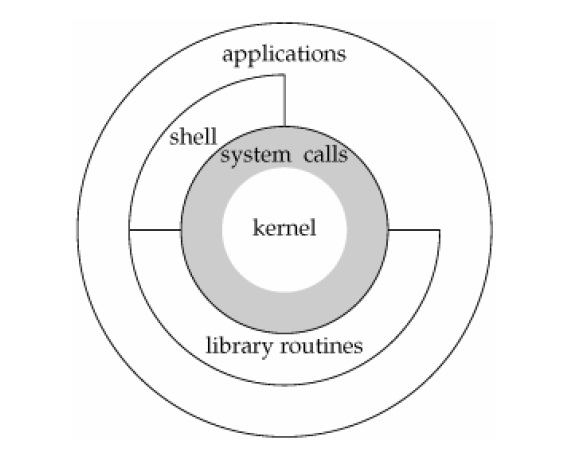
시스템 콜
시스템 콜은 사용자 프로그램이 운영체제 커널에게 특권 기능(파일 입출력, 메모리, 프로세스 등)을 요청하는 방법
사용자 프로그램은 직접 하드웨어를 다룰 수 없기 때문에, 운영체제에게 “이거 해주세요!” 하고 요청하는 것!
동작 흐름
-
사용자 프로그램이 시스템 콜 함수 호출
→ 예:
write(fd, buf, size) -
인터럽트(Interrupt 0x30) 발생시켜 커널 진입
→ Pintos에서는
syscall_handler()로 진입 -
커널에서 시스템 콜 번호 확인 후 해당 함수 실행
→ 예:
SYS_WRITE→sys_write()호출 -
필요한 리소스(파일, 메모리 등) 접근
→ 파일 디스크, 페이지 테이블 등 내부 자료구조 사용
pintos에서의 시스템 콜
- 인터럽트 번호: 0x30
- 인터럽트 핸들러 위치:
userprog/syscall.c - syscall 번호는 enum으로 정의됨:
주로 사용하는 시스템 콜
| 시스템 콜 | 기능 | 호출 예시 |
|---|---|---|
halt() | 시스템 종료 | halt(); |
exit(status) | 프로세스 종료 및 상태 반환 | exit(-1); |
exec(cmd_line) | 새로운 유저 프로세스 실행 | exec("echo hello"); |
wait(pid) | 자식 프로세스 종료까지 대기 | wait(pid); |
read(fd, buffer, size) | 파일 읽기 | read(0, buf, 100); |
write(fd, buffer, size) | 파일 쓰기 | write(1, msg, len); |
create(file, size) | 새 파일 생성 | create("abc.txt", 1024); |
open(file) | 파일 열기 | open("abc.txt"); |
close(fd) | 파일 닫기 | close(fd); |

핀토스 너무 막연해서 어떻게 공부할지 막막했는데 흐름이 확실히 잡히네용 감사합니다 :)