
시작
CSAPP 9장 Virtual Memory
pintos project-3 VM을 공부한 내용입니다.
CSAPP 내용은 대부분 생략합니다.
pintos-VM의 내용과 이해하기 위해 필요한 개념만 정리했습니다.
틀린 부분이 있을 수도 있습니다
용어 정리
단 하나의 용어도 바로 생각이 안 난다면 이해하기 어렵습니다.
VM: Virtual Memory (가상 메모리)VA: Virtual Address (가상 주소)PA: Physical Address (물리 주소, DRAM)KVA: 커널 가상 주소 (커널 베이스 위의 VA를 그냥 KVA라고 말하는 것)UVA: 유저 가상 주소 (커널 베이스 아래의 VA를 그냥 UVA라고 말하는 것)PTE: Page Table Entry (VA -> PA 맵핑 정보를 담은 항목)offset: 페이지 안에서 어디 위치인지frame: 프레임, 즉 물리 메모리에서 페이지 단위SPT: Supplemental Page Table (보충 페이지 테이블)VPN: Virtual Page Number (가상 페이지 번호)PPN: Physical Page Number (물리 페이지 번호)
일반화가 들어가 있습니다. (아래 이미지는 용어 이해용) (실제 주소는 16진수 0x0000_0000 ~ 0x7FFF_FFFF)
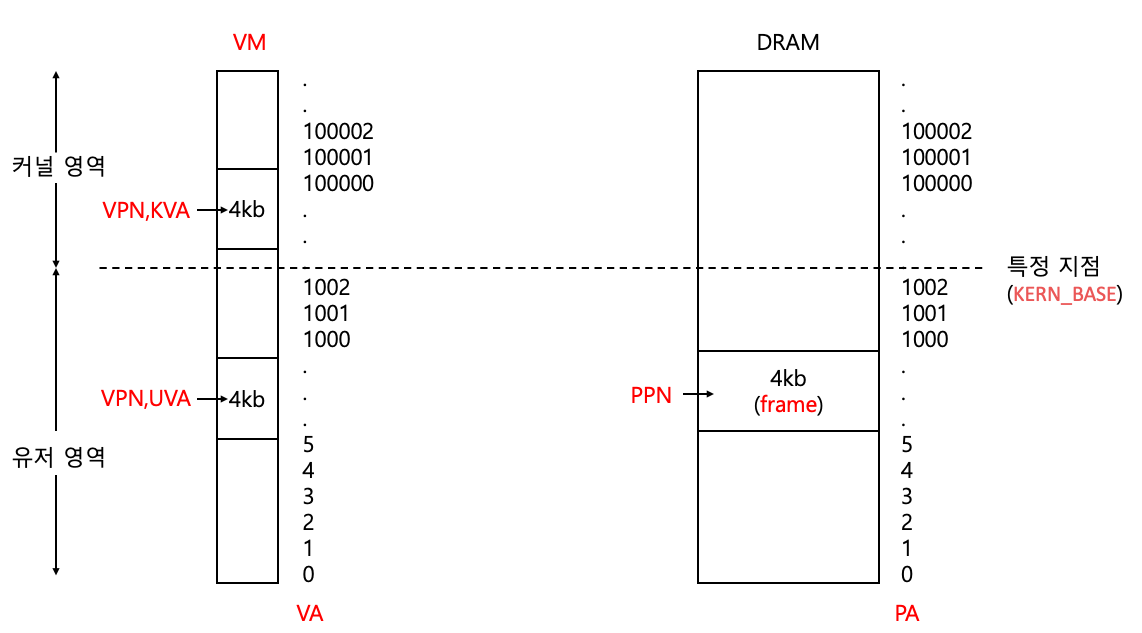
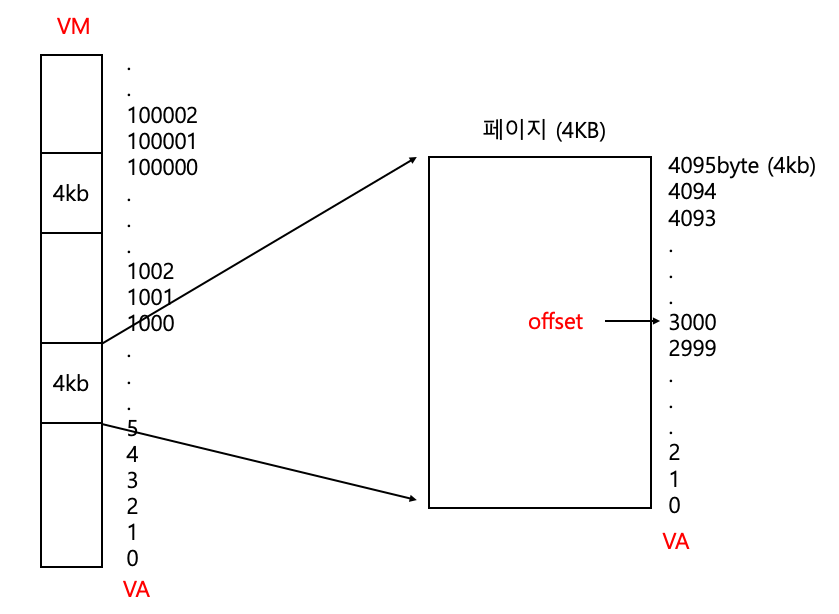
기본적인 구조 및 이해
VA의 구성
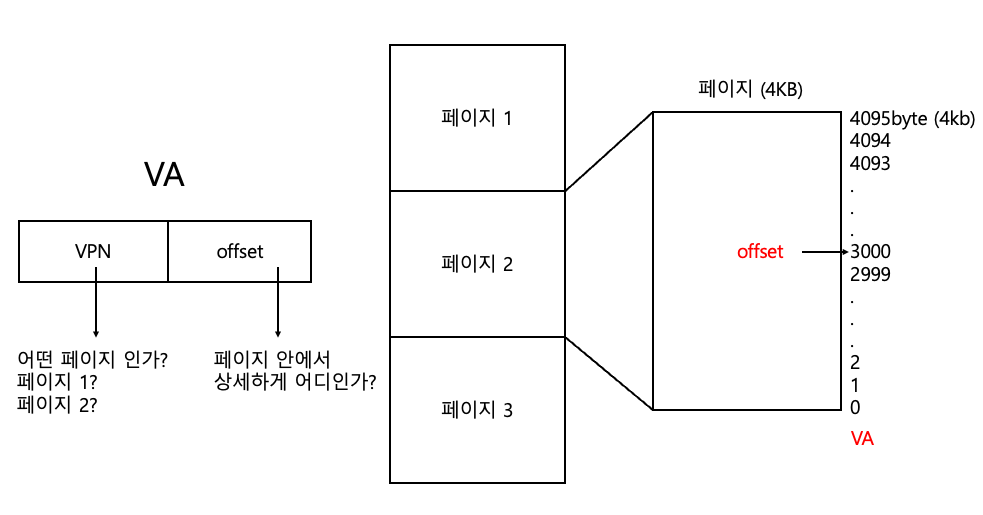
VPO : Virtual Page Offset
우리가 VA, 즉 가상 메모리를 통해서 페이지를 찾고 페이지 안에서 어떤 데이터를 딱 찾으려면 꼭 VPO가 필요하다.
VPN과 VPO를 이해할 땐 2차원 배열을 생각하면 편하다.
[
["apple"], # 페이지 0 (VPN = 0), 오프셋 VPO = 0 이면 "a"
["lemon"], # 페이지 1 (VPN = 1), 오프셋 VPO = 1 이면 "e"
["grape"], # 페이지 2 (VPN = 2), 오프셋 VPO = 2 이면 "a"
["melon"] # 페이지 3 (VPN = 3), 오프셋 VPO = 3 이면 "o"
]
VA의 오프셋과 VPN의 개념은 이해가 안간다면 넘어가도 좋을 것 같다
pintos에서는 페이지가 움직이는게 더 중요해보인다.
VA -> PA 로 바뀌는 과정
페이지
페이지를 왜 쓸까?
배달을 예시로 들어보자.
쿠팡이 배달 올 때 내가 주문했다고 나의 배송 하나만 들고온다면, 기사님 입장에서는 매우 큰 손해이다.
그래서 주위에 있는 모든 배송을 모아서 한번에 배달을 온다.
페이지도 똑같다
1. 메모리도 바이트 단위로 관리하면 너무 힘들다 -> 고정된 크기 페이지(4kb)로 관리한다
2. 페이지 전체가 이동하면 훨신 빠르고, 이동 비용이 감소한다.
가상 메모리 구조의 연결은 "페이지"기준입니다. 페이지로 맵핑하고, 페이지로 할당합니다.
(단편화 해결을 위한 세그멘테이션은 생략합니다)
가상 주소 (진짜. 중요)
가상 주소는 숫자일 뿐이다.
가상 주소는 위치 표시용일 뿐이다.
당연한 소리지만, 메모리를 공부하다보면 이 사실을 까먹고 가상 주소에 어떤 데이터가 저장되거나, 정보가 있다고 오해가 생긴다.
꼭꼭꼭 가상 주소는 물리 메모리의 주소, 즉 위치 표시용이라는 것을 까먹으면 안된다!!!
이 사실을 절대로 잊으면 안된다고 생각한다. 무조건 가상 주소는 숫자. 절대 데이터가 저장되는 것이 아니다.
모든 데이터는 물리 메모리(DRAM) 또는 HDD에 있는 것!!!!!!!!
집 주소 같은 숫자임. 숫자.
예를 들어 가상 주소 VA-1000번 VA-3000번 모두 물리 메모리 PA-4000으로 연결 될 수 있다.
왜냐하면 그냥 연결해논 숫자니까.
물리 주소 위치 표시용 숫자.
진짜 시작!!
pintos-VM 개념 시작!!!!
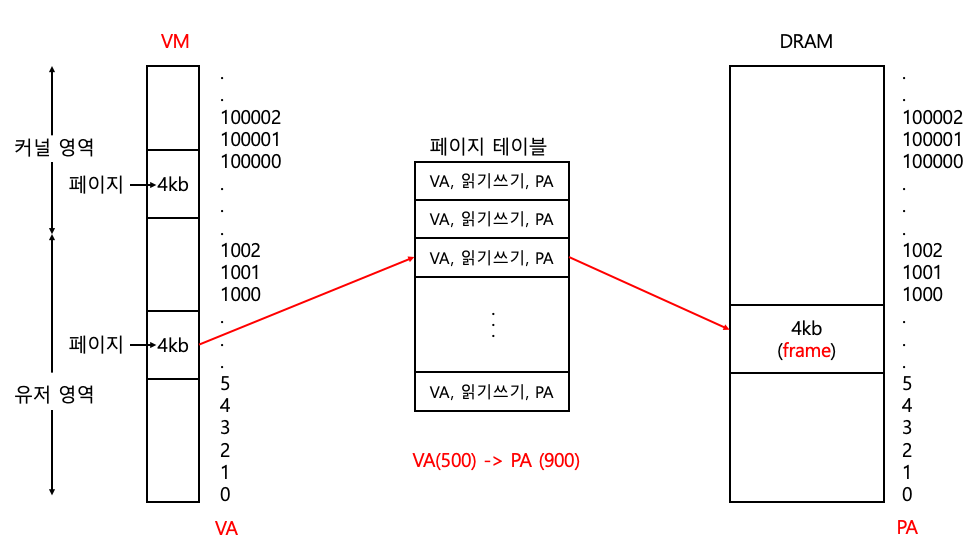
PML4(PTE 포함), SPT (페이지 테이블, 보충 페이지 테이블)
중요!
PML4, SPT는 프로세스 마다 있습니다!!!!!!
또한 SPT, PML4는 물리 메모리에 저장되어 있다!
컴퓨터의 모든 저장 공간은 DRAM(물리 메모리), HDD가 기본이다!!!
PML4
그냥 VA -> PA의 정보가 저장된 표
어떤 정보가 있을까?
| 항목 | 설명 |
|---|---|
| PTE의 프레임 번호 | 가상 주소에 대응하는 물리 프레임 주소 |
| Present 비트 | 해당 페이지가 메모리에 존재하는지 여부 |
| R/W 비트 | 읽기/쓰기 가능 여부 |
| U/S 비트 | 사용자 모드 접근 가능 여부 |
| Accessed / Dirty | 참조됨, 수정됨 여부 |
| 기타 OS-의존 플래그 | 예: 커널 전용 비트 등 |
SPT
보충 페이지 테이블.
일반적인 페이지 테이블은 VA -> PA에 대한 정보를 저장하는 것이 주 목적.
따라서 부가적인 정보는 SPT 보충 테이블에 저장한다.
- 어떤 파일에서 로드된 데이터인지
- 디스크에 있는지. 메모리에 있는지
- 익명 페이지인지, 파일 페이지인지
등등 부가적인 정보가 저장되어 있다.
페이지 형식
VM_UNINIT(초기화 되지 않은 페이지)
- 아직 내용이 채워지지 않은 페이지
- 즉 가상 메모리 공간은 할당 받았지만, 실제 데이터는 로딩이 안된상태 (물리 메모리 할당 안됨.).
- Lazy loading 을 구현하기 위해 사용
- SPT에 등록만 된 상태, 다만 어떤 페이지로 변신할 지 운명은 정해져 있다.
VM_ANON (익명 페이지)
- 특정 파일과 연결 되지 않은 페이지.
- 프로세스의 스택, malloc로 할당 받은 힙 영역 데이터를 저장하는 페이지
→ uninit페이지가 초기화 될 때 anon페이지가 될 수 있다.
VM_FILE (파일 기반 페이지)
- 특정 파일의 내용과 직접 맵핑되는 페이지
- mmap file : 파일의 내용을 메모리의 특정 영역에 직접 연결하여, 메모리에 접근하는 것처럼 파일에 접근할 수있게 한다.
- 페이지 폴트가 발생시, 파일의 위치에서 데이터를 읽어와 물리 메모리 프레임을 채운다.
→ uninit페이지가 초기화 될 때 file페이지가 될 수 있다.
다시 강조!!!
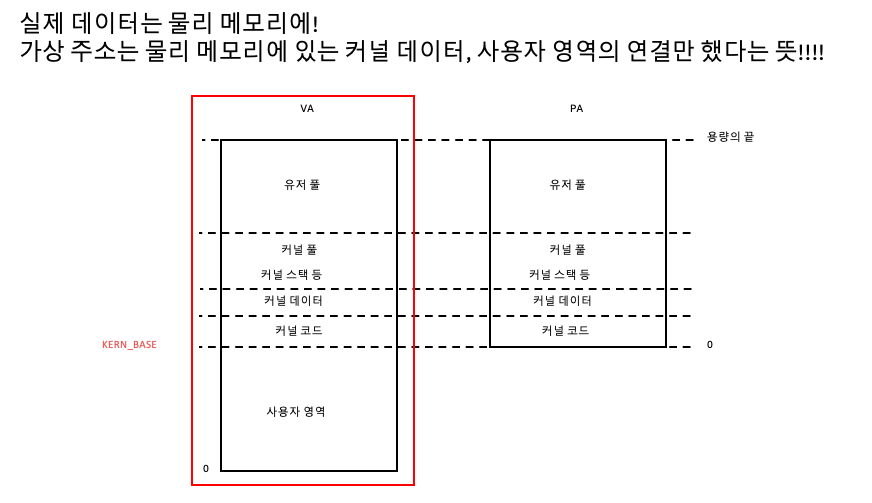
가상 주소에 써있는 커널 데이터, 커널 코드, 사용자 영역의 코드, 데이터, 스택은 데이터 자체가 아님!
가상 주소를 페이지 테이블을 타고 물리 메모리로 들어가면 해당 데이터(커널 코드,스택, 사용자 데이터등)가 있다는 뜻!!!
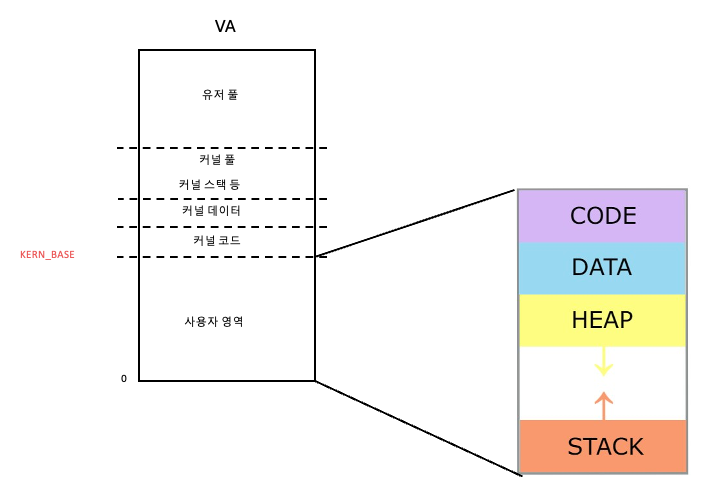
사용자 영역도 우리가 공부했던 메모리 구조랑 똑같다! 다만 페이지의 이동 설명이 메인이기 때문에 뒤에서는 생략합니다!
KERN_BASE와 물리 메모리 (중요)
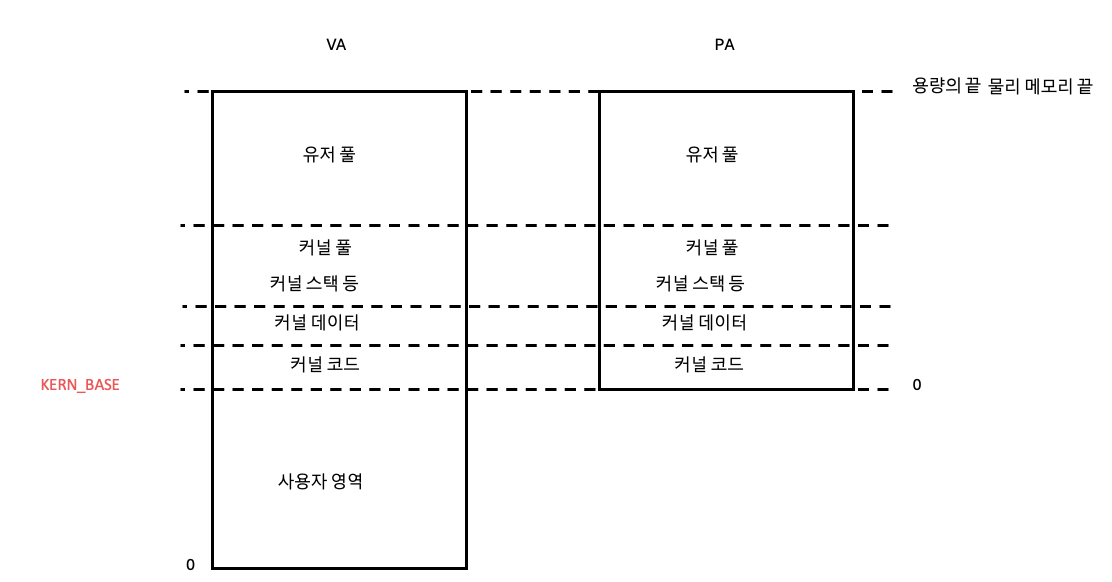
(커널 공간과, 유저 공간의 비율은 무시하시면 됩니다. 이해를 위해 공간 분리만 표현했습니다)
기존의 메모리 구조 그림은 잊어야 한다.
VA의 커널 베이스가 물리 메모리의 0번 시작점과 같다는 사실을 꼭 인지해야한다.
왜 이렇게 하는가?
잘 생각해보면, 물리 메모리를 만지고 조작할 수 있는건 커널 뿐이다.
커널이 물리 메모리의 모든 영역을 자신의 영역 안에 두어야하기 때문에 커널 영역의 시작 지점을 물리 메모리 0번 시작 지점에 맞추는 것이다!
이러한 구조를 가지면 KERN_BASE부터는 물리 메모리와 1대1로 맵핑 된다는 엄청난 장점이 있다!!!
자세한 내용은 뒤에 설명하겠읍니다.
근데 그럼 사용자 영역은 어디에 저장해!!!!!!
물리 메모리 위에 유저풀이 있다 -> 너무 작은데?
이해를 위한 그림으로 그려서 그렇지 실제로는 유저 풀 크다.
커널 부분은 사실 용량 많이 안 먹음.
만약 8gb 램이 있을 때 1gb를 커널이 쓴다고 하면, 나머지 7gb는 유저 풀이다!
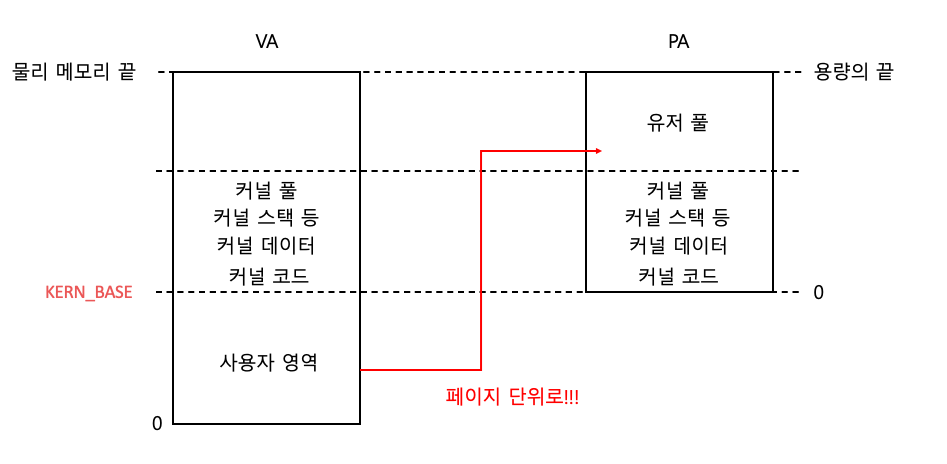
유저 풀을 페이지 단위로 할당하면서 프로세스 별로 나눠 쓴다.
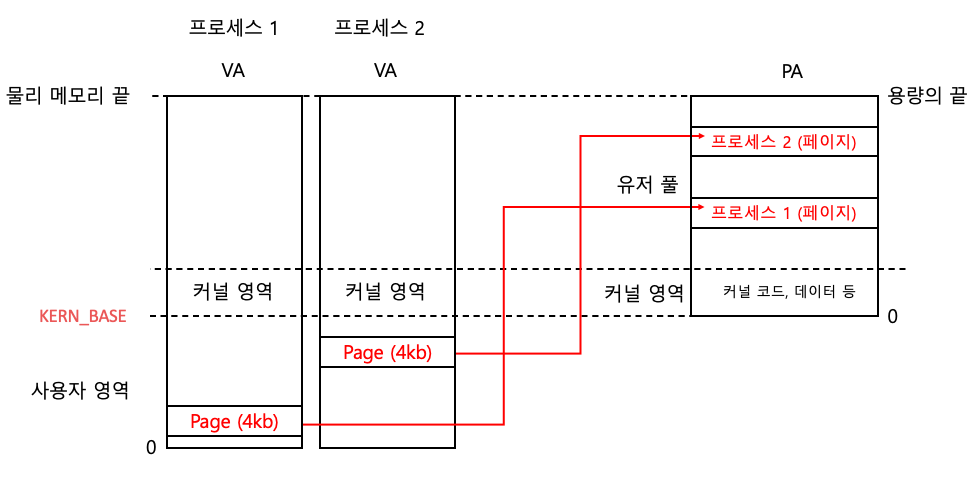
VA에 위에 남은 주소는 뭐야. 뭔데.
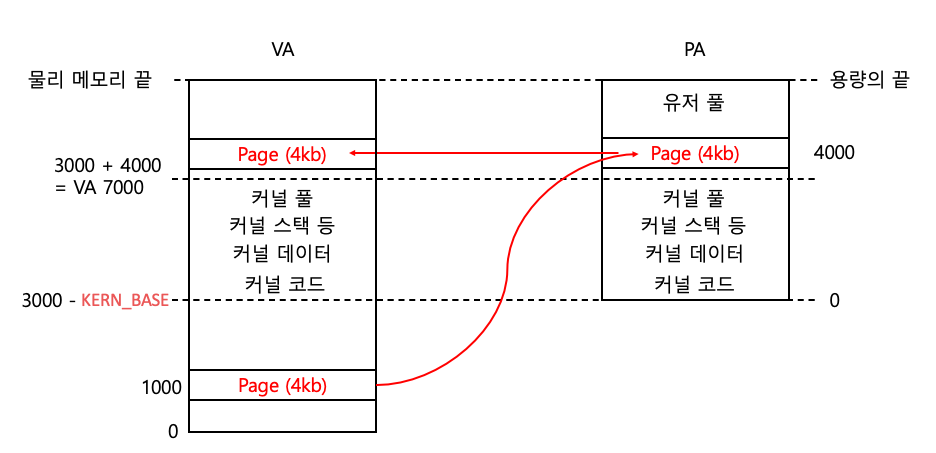
사용자 주소 UVA는 물리 메모리에 맵핑된 데이터를 읽는 것 말고는 할 수가 없다.
그럼 새로운 공간을 만들고, 데이터를 쓰고, 페이지 폴트를 처리하는 등 메모리를 조작하는 일은 커널만 할 수 있다.
이게 커널이 메모리를 조작하고 싶은 상황이다. 따라서 KVA를 얻는 것이다.
하지만 우리는 물리 메모리 PA-4000에 대한 주소는 사용자 영역에만 맵핑이 되어 있다.
커널도 PA-4000에 가고 싶다.
따라서 KERN_BASE + PA를 계산하면 커널용 연결 주소(KVA-7000)를 얻을 수 있다.
야호. 이제 커널이 KVA-7000를 타고 PA-4000을 가서 마음 것 메모리를 조작할 수 있다.
잠깐. 아니 근데 그냥 물리 주소 PA-4000을 알고 있는데?
물론 사용자 영역에 맵핑되어 있는 주소 VA-1000을 타고 페이지 테이블을 거쳐 PA-4000을 얻을 수 있다.

깃 북을 보면 x84-64 시스템에서는 물리 주소(PA)를 통해서 바로 메모리에 접근이 안된다고 한다.
무조건 VA -> 페이지 테이블 -> PA로 접근 해야한다.
따라서 커널이 물리 메모리 PA-4000에 접근하려면 커널도 VA를 얻어야 한다.
가상 메모리도 크기가 작은거 아닌가?
지금까지
가상 주소의 끝이 물리 메모리의 끝과 같은 그림으로 이야기했다.
그럼 가상 주소도 작은거 아닌가? 생각이 들 수 있지만. KERN_BASE 아래의 공간이 있기 때문에
KERN_BASE의 위치를 조절하면 가상 메모리는 훨신 클 수 있다.
여기서도 오해하면 안된다. 그냥 가상 주소 표시가 큰거지. 저장되고 그런건 아니다.
그냥 표시하는 숫자만 물리 메모리 주소보다 넓은거입니당.
KERN_BASE + PA = KVA?
KVA: 커널 가상 주소
요상한 점이 있다. KERN_BASE + PA를 통해서 커널 가상 주소를 받은건 알겠다.
근데 결국 KVA 또한 페이지 테이블을 타고 PA를 받아야하는데. 우리는 페이지 테이블을 작성한 적 없다.
요건 프로세스를 만들고 가상 메모리를 만들 때. KERN_BASE 위로 물리 메모리의 PA랑 맵핑을 다 해놓는다.
왜냐? 1대1 맵핑이기 때문에 우리가 KERN_BASE + PA를 통해서 KVA를 얻을 때 바로 사용할 수 있도록!
Read() 시스템 콜과 메모리 읽기
저는 메모리에 데이터를 읽으려면 read() 시스템 콜을 사용해서 읽는다고 생각했습니다
어? 그럼 UVA 사용자 주소는 왜 있지? 어차피 KVA로 반환 받아서 Read() 시스템 콜로 읽는거 아닌가??
하지만 그것은 틀렸습니다.

파일 fd로부터 size만큼 데이터를 읽어 buffer에 저장
파일을 읽는 시스템 콜이다. 이 부분은 직접 찾아보자!
당연한 이야기였지만. 일반적으로 UVA -> PA의 경우는 유저가 그냥 메모리를 읽으면 된다.
모든 UVA를 커널 모드로 바꿔서 KVA를 반환 받고 Read()로 메모리를 읽으면 컴퓨터 느려터진당
그리고 Read()는 사용자가 커널에게 부탁하는 것! 커널은 Read가 아니라 그냥 맘대로 읽는다!
그럼 Read()는 언제 쓸까? 그것두 한번 찾아보자.
페이지 폴트와 SPT
위키백과를 보면 페이지 폴트는 메모리에 어쩌구 저쩌구라고 써져있다.
쉽게 이해하면!
메모리에 페이지가 없으면, 페이지 폴트라고 이했습니다.
메모리에 페이지가 없으면 페이지 폴트.
메모리는 저장하고 이동하는 단위가 페이지.
페이지가 없으면 페이지 폴트.
그럼 없으면 어디에 있냐!
HDD에 있을 수도 있고, 아직 만든적이 없을 수도 있다.
SPT
프로세스가 생성될 때, 사용할 것으로 정의한 가상 페이지들에 대한 정보는 SPT에 우선적으로 기록된다!!!
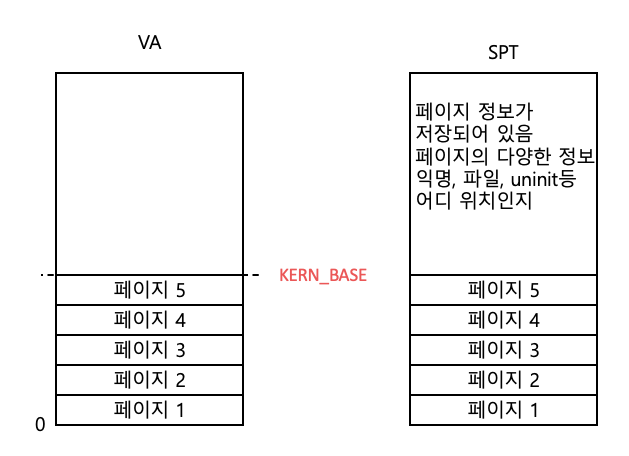
왜나하면 PML4를 보고 페이지가 VA - PA 연결이 안되어있다면, VA - PA 연결 정보를 PML4에 등록해야하는데.
어떤 정보를 보고 등록을 할까? 바로 SPT를 보고 한다!
따라서 프로세스가 생성될 때 사용할 페이지는 우선 SPT에 기록해둔다!
여기서도 절때. 절때. VA의 페이지는 그냥 데이터가 저장된게 아니다.
예를들어 0~4096의 주소(페이지 4kb)는 파일이나 스택 같은 데이터가 저장될꺼야. 라고 형식만 기록해두는 것.
물론 SPT는 물리 메모리에 저장되어 있다. (PML4도 물리 메모리에 저장되어 있음.)
그냥 VA주소가 어떤 역할을 할껀지 SPT라는 테이블에 기록해두는 것!
데이터는 페이지 테이블과 연결이 되고 물리 메모리에 기록 되어야한다!!
Lazy loading

왜 하는걸까??
아직 사용하지도 않는 페이지를 미리 할당한다면, 나중에 쓸건데 미리 물리 메모리에 할당 받아버려서 물리 메모리가 너무 부족하당.
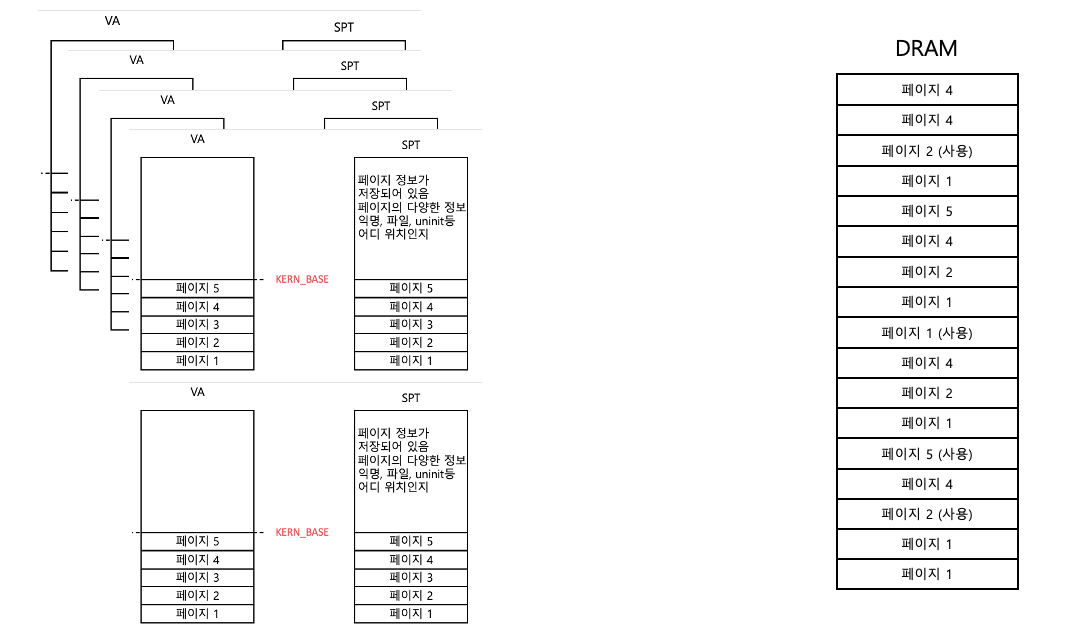
프로세스가 자신의 모든 가상 메모리 페이지 대해서 물리 메모리 공간을 할당 받는다면,
실제로 사용하는건 얼마 없는데. 미리 공간을 차치하는 대참사가 발생한다.
문제는 우리의 컴퓨터는 프로세스가 엄청 많다는 것. 이건 아주 큰 문제다 문제.
그래서 진짜 사용하는 시점, 물리 메모리에 접근할 때 할당한다!!!
물리 메모리 접근 전, 즉 진짜 사용하기 전에는 SPT에 페이지에 대한 정보만 저장해둔다!!
예를들어 "어떤 데이터가 저장될 예정이고, 데이터는 HDD의 hello.c파일이다." 이런 정보만 SPT에 저장한다.
진짜로 접근한다면 SPT를 보고 HDD에서 hello.c 파일을 읽어서 물리 메모리에 써주면 된다!
페이지 폴트 과정을 살펴보자.
페이지 폴트의 경우. 대표적으로
1. 그냥 처음 할당하는 경우 (lazy loading)
2. 스왑의 경우
가 있습니다.
물론
스택 확장, copy-on-write, 읽기 전용에 쓰기 시도등 다양하게 있지만.
대표적인 2가지만 알아보겠습니당.
그냥 처음 할당하는 경우 (lazy loading)
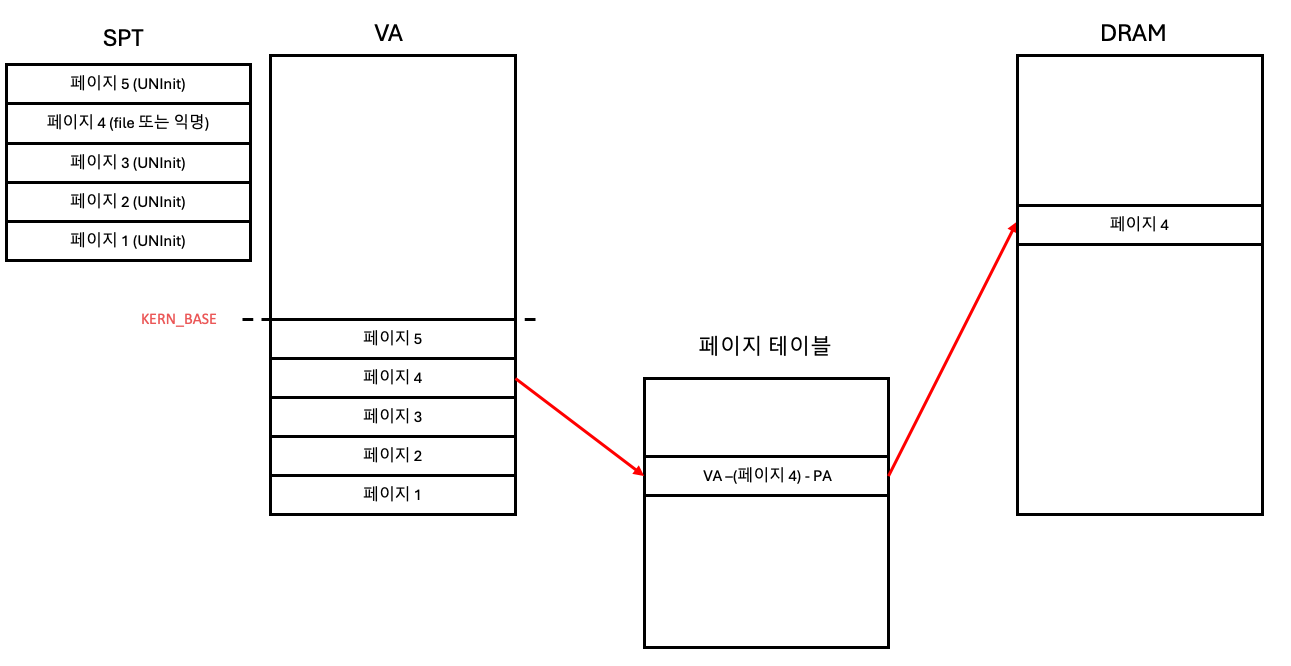
만약 어떤 가상 주소(VA)가 이미 물리 프레임(PA)에 매핑되어 있고, 해당 정보가 하드웨어 페이지 테이블(PML4)에 정상적으로 기록되어 있다면, 사용자 프로그램은 해당 VA에 접근할 때 아무런 문제 없이 MMU를 통해 PA로 변환되어 물리 메모리의 데이터를 읽고 쓸 수 있습니다. (일반적인 메모리 접근!!)
하지만! 이때 페이지 3에 대한 VA를 사용하면 어쩔까? (lazy loading)
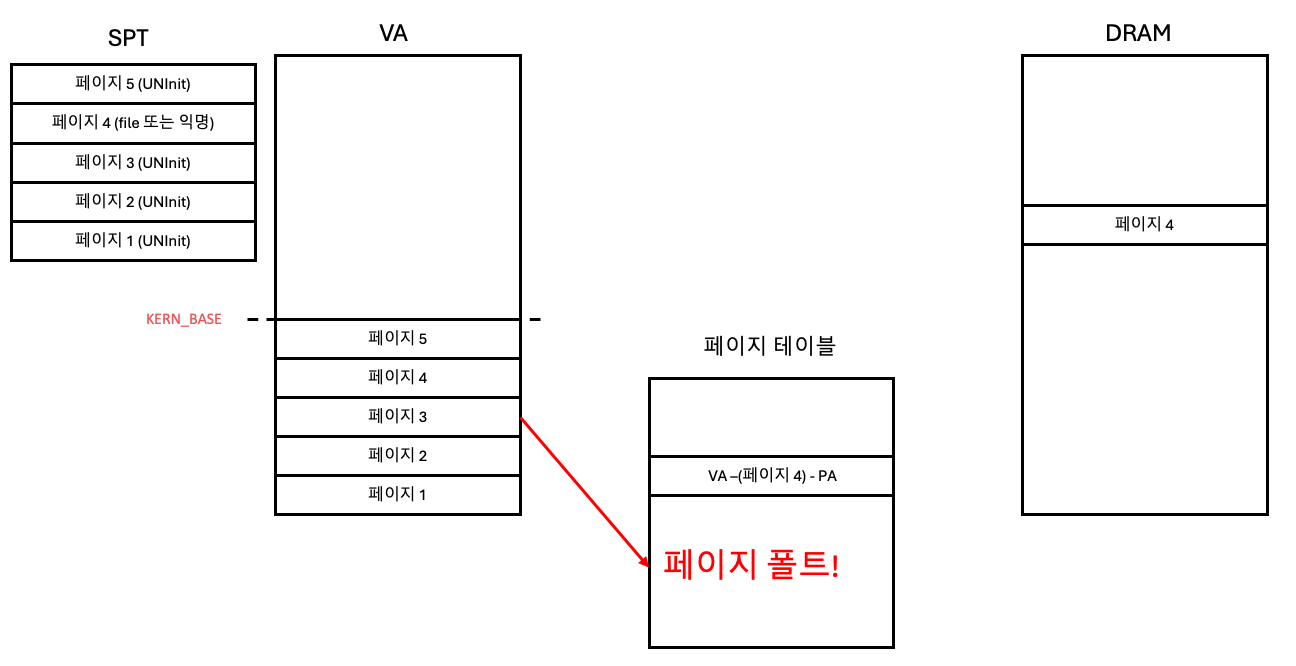
페이지 테이블에 페이지 3에 대한 맵핑 정보가 없기 때문에 바로 폴트 발생!
바로 커널에게 권한을 넘겨주고 페이지 폴트를 처리한다!!!! (이 상황이 Lazy loading!!)
- SPT를 확인한다.
- 페이지 3에 대한 정보가 있는지 확인한다.
- 물리 메모리에 프레임(페이지)를 할당 받는다.
- 할당 받을 때 KVA를 반환 받는다.
- KVA를 통해 물리 메모리에 접근할 수 있다.
- SPT를 보고 필요한 정보를 확인한다.
- SPT를 보니까 파일 페이지가 될 운명이었고, 파일 데이터는 HDD에 있다고 한다.
- HDD에서 파일을 읽는다.
- 아까 받은 KVA를 타고 물리 메모리에 읽었던 내용을 작성한다.
- KVA - KERN_BASE 빼면 물리주소가 나온다.
- 아까 요청했던 사용자 가상 주소와 물리 주소를 페이지 테이블에 연결한다.
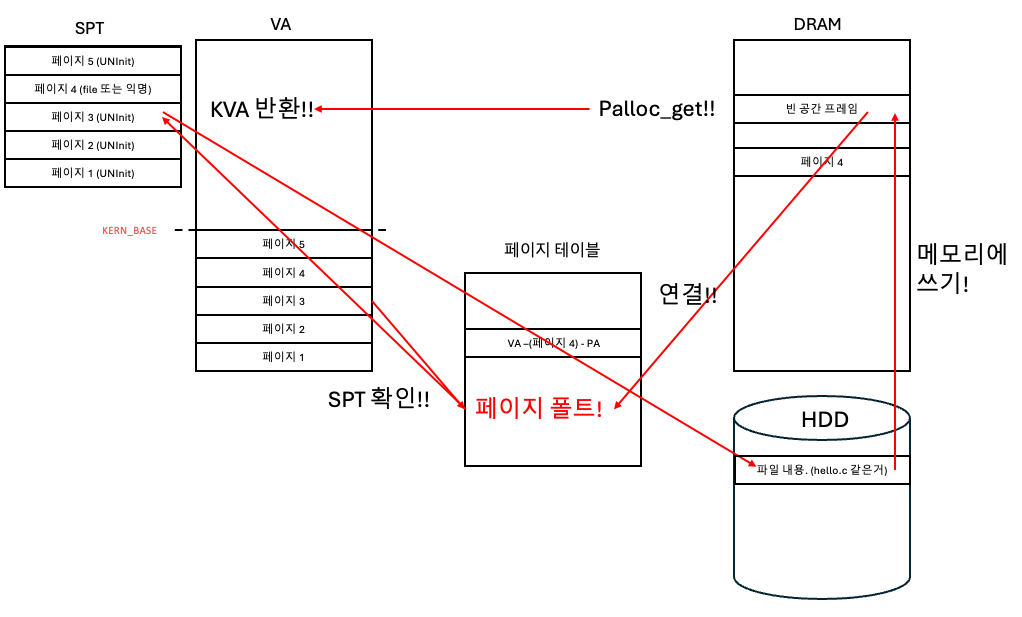
그림이 복잡하지만 순서대로 잘 따라가보자!
스왑의 경우.
스왑은 HDD의 일정 공간을 메모리 보조 공간으로 쓰는 것!!
특별히 HDD,SSD에 만들어논 공간임!!!!
임시 창고 역할!
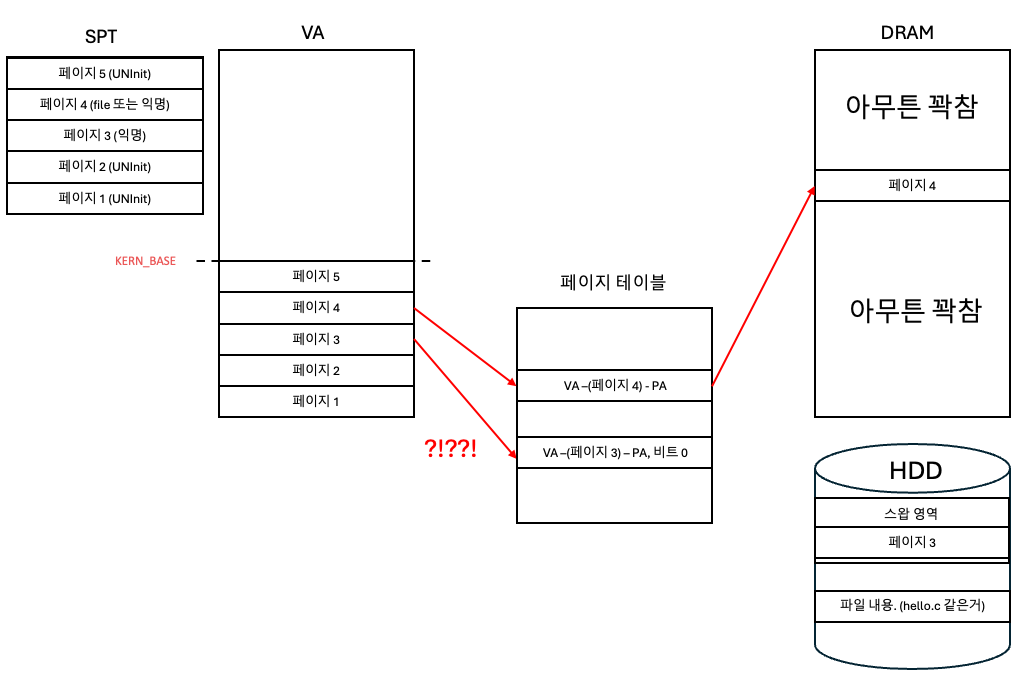
다른 페이지들이 많이 쓰이고 페이지 3는 잘 안써서 스왑 영역으로 쫓겨났음.
또는 다른 프로세스에서 페이지 할당해야하는데 공간이 없어서 잘 안쓰는 페이지 3가 선택 당함.ㅠㅠ
헉! 근데 페이지 3에 대한 요청 발생!!!!
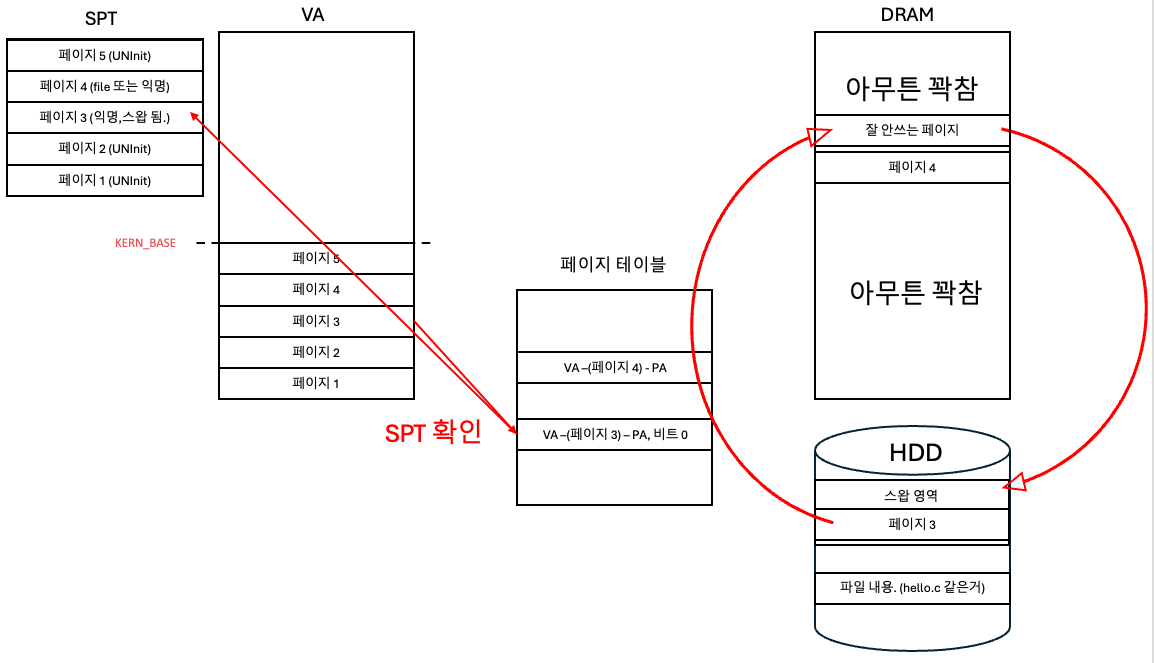
물리 메모리에 남는 공간이 있다면, palloc로 할당 받고 스왑에서 올리면 된다.
근데 물리 메모리에 공간이 없다? 그럼 안쓰는 페이지를 스왑으로 내리고, 페이지 3를 올리면 된다.
마지막으로 PML4 페이지 테이블의 비트를 1로 바꿔주고, SPT에서 물리 메모리에 있다고 수정해준다.
스왑 슬롯에 대한 테이블도 있기 때문에 그것도 수정해준다. 페이지 3가 있던 스롯이 사용 가능으로 바뀐다.
파일 테이블은 스왑에 넣을 필요가 없는 것 같은데?
왜냐하면, 파일 테이블은 결국 HDD에 파일로 저장되어 있다!!
따라서 그냥 물리 메모리에서 쫓겨 날땐. 그냥 쫓아 버리면된다.
익명 페이지는 (스택, 힙) 데이터는 메모리에 저장된 정보가 전부니까, 스왑 영역에 내린다!
파일 기반 페이지(File-backed page)는 내용이 변경되지 않았다면(clean) 그냥 버려지고, 변경되었다면(dirty) 스왑 영역이 아닌 원본 파일에 다시 써준다.
이 부분은 아직 부족해서 직접 찾아보면 좋겠다!
기타
VM을 왜 쓸까?
- 프로세스마다. 독립된 공간을 제공하기 위해.
물리 메모리는 하나지만. 페이지 맵핑 과정을 통해 각각의 프로세스가 자신만의 고유 공간을 가진 것 처럼 보인다.!!
KERN_BASE 와 물리 메모리 0
- 1대1 맵핑을 설명하기 위해 커널 시작 부분을 바로 물리 메모리 0에 표시했지만. 실제로는 부트로더 같은 정보가 먼저 오고, 1mb위에 커널 부분이 시작된다고 합니다. 1대1 맵핑이 된다는 사실이 중요합니다
VA의 사용자 유저 공간
- 이 부분도 실제로는 0번에서 시작하지 않고 조금 위에서 시작합니다.
- 커널 베이스와 사용자 공간 사이도 빈 공간이 있습니다.
일반화
- 이해를 위해 어느 정도 일반화가 들어가 있습니다!
이해를 위해서 참고만 해주시면 좋겠습니다!! 자세한 내용은 검증이 필요합니다!!
코치님이 설명해주신 내용 이미지
코치님이 설명해주신 내용입니다. 최종적으로 이해하면 좋겠습니당. (아래 이미지 제공 코치님.)
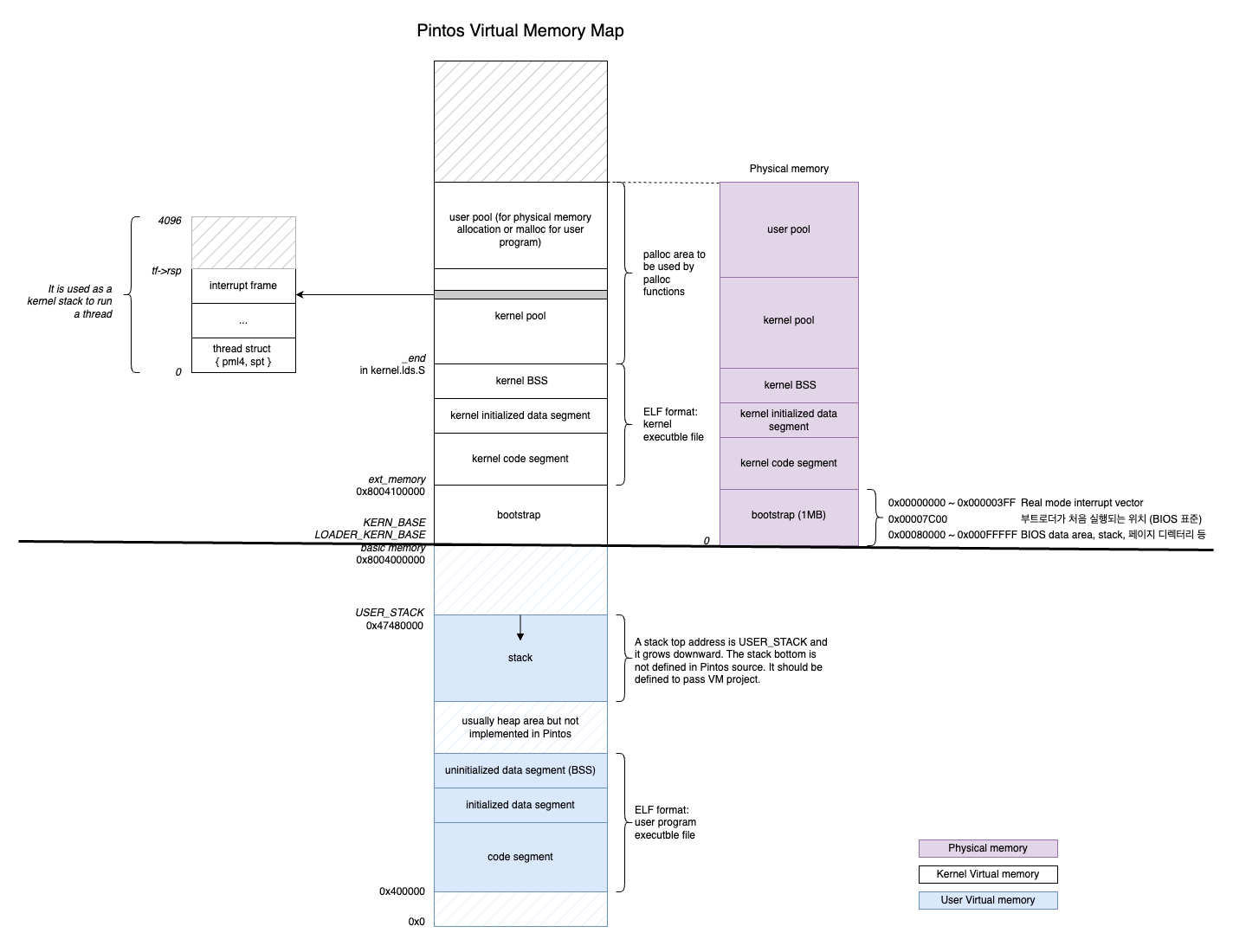
끗





레전드네요. 너무 좋아요 궁굼증이 해소가 되었습니다. 제 블로그도 탐방 부탁드려요. 서로이웃 하고싶어요 반갑습니다.
저희 불우한 환경을 가진 서로를 도와가며 공동체를 잘 꾸며나가봅시다.