이 글은 아래 문서를 의역, 번역한 글입니다. 부족한 영어실력으로 오역이 있을 수 있는 점 이해바랍니다!
Scaling to 100k Users | Alex Pareto
1명의 유저 : 1개의 머신
거의 모든 애플리케이션, 예를 들면, 웹사이트나 모바일 앱에서는 3가지 주요 컴포넌트를 가지고 있다. : API, 데이터베이스, 클라이언트(보통 앱이나 웹사이트)
데이터베이스는 지속성있는 데이터를 저장한다. API서버는 그 데이터에 대한 요청들을 처리한다. 클라이언트는 그 데이터를 유저에게 보여준다.
나는 현대 애플리케이션에서 API로부터 클라이언트를 완전히 분리된 개체로 생각하는 것이 스케일링의 측면에서 훨씬 쉽다는 것을 알아냈다.
우리는 애플리케이션을 처음 만들기 시작할 때, 이 3가지 요소들을 하나의 서버에서 동작하도록 해도 괜찮다. 이것은 한명의 엔지니어가 데이터에베이스, API, 클라이언트를 같은 컴퓨터에 실행시키는 개발환경과 닮아있다.
이론적으로, 우리는 이것을 하나의 DigitalOcean Droplet 또는 AWS EC2 인스턴스로서, 클라우드에 배포할 수 있다.

10명의 유저 : 데이터베이스의 분리
AWS의 RDS 또는 Digital Ocean’s Managed Database 와 같이 관리되는 서비스로서 데이터베이스를 분리한다면, 우리의 서비스는 더욱 나아질 것이다.
이것은 하나의 머신이나 EC2 인스턴스로 셀프 호스팅하는 것보다 약간 더 비싸다. - 하지만, 데이터베이스의 분리를 통해, 우리는 다음을 손쉽게 얻을 수 있다. : 멀티 지역 중복성, 읽기 전용 복제, 백업 자동화 등
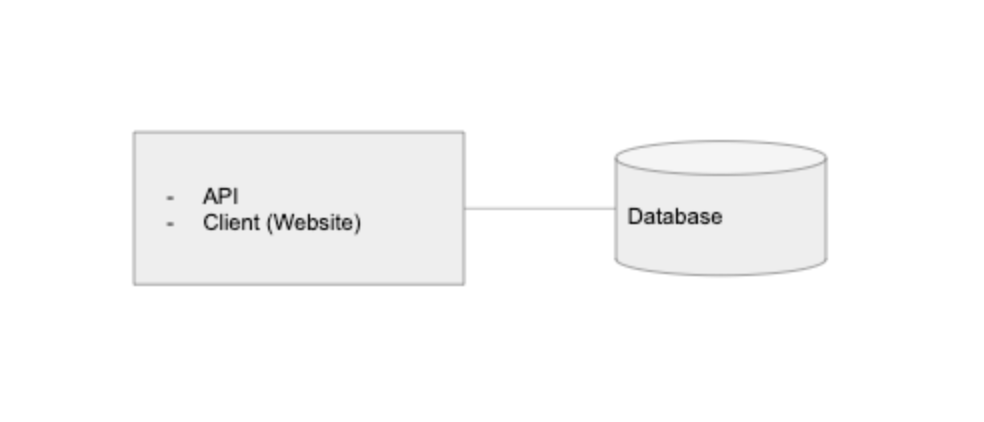
100명의 유저 : 클라이언트의 분리
Graminsta를 사랑하는 사용자들이 생기면서, 트래픽이 점점 고정화되고 있다. 클라이언트를 분리할 차례다! 개체를 분리할때 가장 중요한 것은 확장 가능한 애플리케이션을 만드는 것이다. 시스템의 한 부분에서 많은 트래픽이 발생하면, 우리는 특정 트래픽 패턴에 근거하여 서비스를 확장할 수 있도록 앱을 분리한다.
이것이 내가 API로부터 클라이언트를 분리하여 생각하기를 좋아하는 이유다. 이는 다양한 플랫폼에 확장하는 것을 가능하게 한다. : 웹, 모바일웹, iOS, 안드로이드, 데스크탑 앱, 써드파티 서비스 등. 우리는 이 모든 클라이언트가 같은 API를 사용하게끔 한다.
같은 맥락에서, 유저들의 가장 큰 피드백은 Graminsta를 핸드폰에서도 사용하고 싶다는 것이다. 그래서,우리는 아래와 같이 모바일 앱을 출시했다.
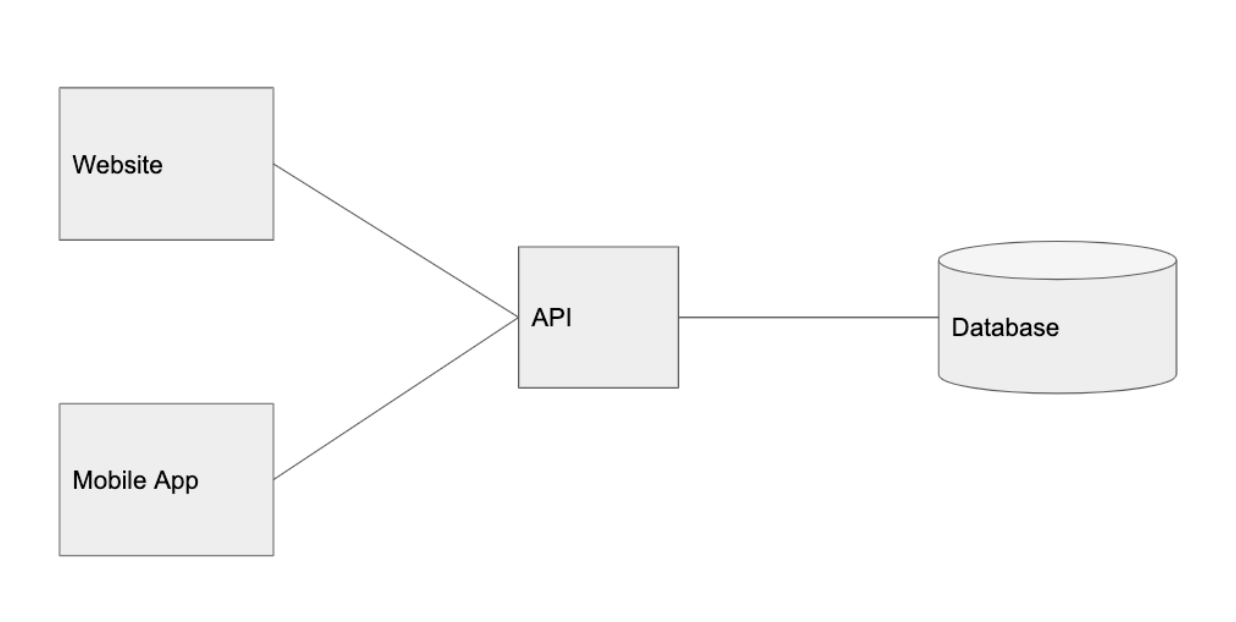
1,000명의 유저 : 로드 밸런스 추가
Graminsta에서 유저들은 여기저기에서 사진을 올리고 있다. 더 많은 유저들을 회원가입을 하고 있다. 하나의 API 인스턴스로는 이 모든 트래픽을 감당할 수 없다. 우리는 더 많은 컴퓨터 파워가 필요하다!
로드 밸런서는 매우 강력하다. 우리는 로드밸런서를 API 앞에 놓고, 로드밸러서가 트래픽을 라우팅한다. 이것은 수평적인 확장을 가능하게 한다. (같은 코드를 실행하는 많은 서버들을 추가함으로써 우리는 더 많은 요청을 처리할 수 있다.)
우리는 웹 클라이언트와 API 앞에 각각의 로드 밸런서를 둘 것이다. 웹 클라이언트와 API의 코드를 실행하는 여러개의 인스턴스를 가질 수 있다. 로드 밸런서는 가장 적은 트래픽을 가진 인스턴스에 요청을 라우팅하게 된다.
우리는 이로써, ‘중복성’을 갖게 된다. 하나의 인스턴스가 죽으면(오버로드 되었거나, 크래쉬된 경우), 시스템 전체가 죽지 않고, 다른 인스턴스가 대신 요청에 응답할 수 있다.
또한, 로드밸런서는 자동 확장을 가능케 한다. 많은 이용자가 온라인일 때는(Superbowl 상태), 인스턴스의 수를 증가시키고, 이용자가 적을때는 인스턴스의 수를 감소시키도록 로드밸런서를 설정할 수 있다.
로드밸런서를 통해서, 우리는 API층을 실제적으로 무한대로 확장할 수 있다. 우리는 더 많은 요청을 얻을때마다 인스턴스를 추가할 것이다.
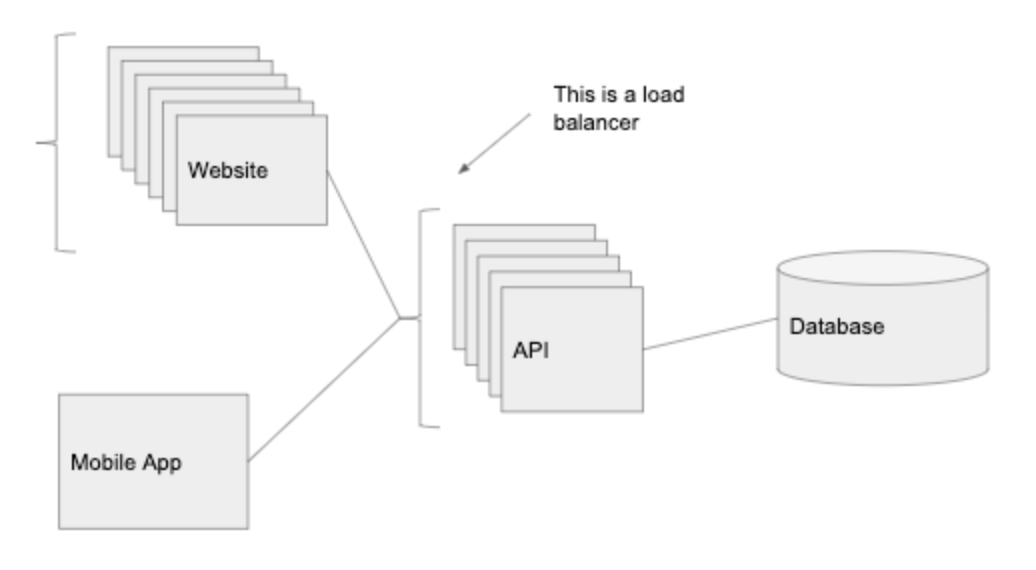
참고 : 이 방식은 Heroku 나 AWS’s Elastic Beanstalk와 같은 PaaS 회사들이 제공하는 서비스와 매우 닮았다. Heroku는 데이터베이스를 분리된 호스트에 놓고, 자동 확장으로 로드밸런서를 관리하고, API 서버와 웹 클라이언트를 분리하여 호스트한다. 따라서, 프로젝트나 초기 스타트업은 Heroku와 같은 서비스를 사용할 것을 추천한다. - 필요한 기본 사항이 바로 제공되기 때문이다.
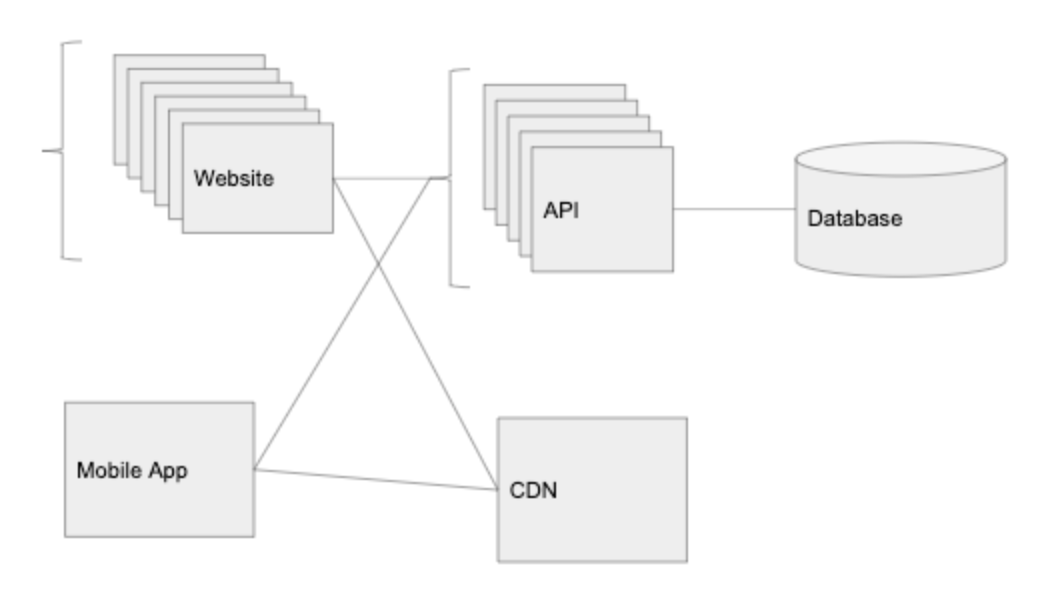
10,000명의 유저 : CDN
많은 이미지들을 업로드하고, 서비스하는 것은 서버에 큰 부담으로 다가온다. 우리는 정적 콘텐츠를 호스트하는 클라우드 스토리지 서비스(AWS’s S3 또는 Digital Ocean’s Spaces)를 사용해야 한다. : 정적 콘텐츠란, 이미지, 비디오, 등이다. 일반적으로, API가 이미지를 보여주고, 업로드해서는 안된다.
우리가 클라우드 스토리지 서비스로부터 명심해야할 또 다른 것은 CDN이다. (AWS에서 이것은 Cloudfront로 불리운다. 하지만, 많은 클라우드 스토리지 서비스는 이 서비스를 바로 제공한다.) CDN는 전세계의 서로 다른 데이터 센터에서 이미지를 자동으로 캐시할 수 있다.
우리의 메인 데이터 센터가 Ohio에서 호스팅되고 있을 때, 만약 다른 사람이 일본에서 이미지를 요청한다면, 클라우드 제공자는 카피본을 만들어서 일본에 있는 데이터 센터에 그것을 저장한다. 일본에서 그 이미지를 요청하는 다음 사람은 그 이미지를 더 빠르게 받을 수 있다. 전세계로 로드되어 보내지기 때문에 시간이 오래 걸리는 이미지나 비디오처럼 큰 사이즈의 파일들을 제공할 때 이러한 방식이 더 중요해진다.
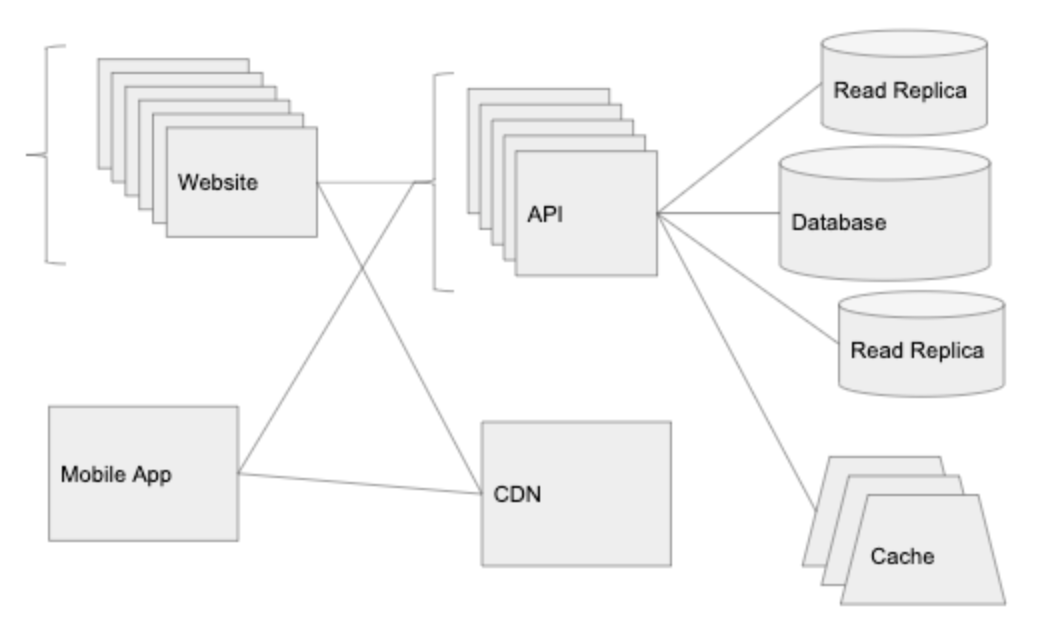
100,000명의 유저 : 데이터 계층 확장
CDN은 여러방면에서 도움이 된다. 유명 유튜버는 Graminsta에 가입하여, 자신의 스토리를 올렸다. API의 CPU와 메모리의 사용량은 낮다. -10개의 API를 로드밸런서에 추가했기 때문이다. - 하지만, 우리는 요청에 대한 많은 타임아웃을 겪고있다. 왜 요청이 오래 걸리게 되는 걸까?
삽질 후 우리는 알아냈다 : 데이터베이스의 CPU가 약 80-90%로 움직이고 있었기 때문이다. 한도가 초과된 것이다.
데이터 계층을 확장하는 것은 매우 까다로운 문제이다. stateless한 요청들을 처리하는 API 서버에서, 우리는 더 많은 인스턴스를 추가할 수 있었지만, 이는 대부분의 데이터베이스 시스템에서는 효과가 없습니다. 이 상황에서, 우리는 가장 인기있는 관계형 데이터베이스 시스템(PostgreSQL, MySQL, etc.)을 알아보았습니다.
캐싱(Caching)
데이터베이스를 최대한 활용하는 가장 쉬운 방법은 새로운 요소를 도입하는 것이다. : cache layer (캐시 계층) 캐시를 실행하는 가장 일반적인 방법은 in-memory key value store 방식(ex. Redis 또는 Memcached)을 사용하는 것이다. 대부분의 클라우드는 이러한 서비스를 갖고 있다 : Elasticache on AWS, Memorystore on Google Cloud.
서비스가 같은 정보에 대해서 데이터베이스에 여러번 반복되는 요청을 보냈을 때, 캐시는 매우 유용하다. 본질적으로, 우리가 데이터베이스를 작동시키고, 캐시에 정보를 저장한 다음에는, 데이터베이스를 다시 손댈 필요가 없다.
예를 들어, Graminsta에서 A가 B의 프로필 페이지에 들어갈 때마다, API 계층은 B의 프로필 정보를 데이터베이스에 요청해야 한다. 이것을 계속해서 일어날 것이다. B가 매 요청때마다 자신의 프로필을 바꾼 것이 아니라면, 이 정보는 캐시하기 적합한 데이터이다.
우리가 Redis에서 30초의 만료시간을 가진 user:id 의 키를 근거로, 데이터베이스로부터 결과를 캐시할 것이다. 누군가 B의 프로필에 접근할 때, 우리는 Redis를 먼저 체크하고, Redis에 데이터가 있다면, 바로 데이터를 제공한다.
대부분 캐시는 데이터베이스보다 확장하기 쉽다. Redis는 Redis Cluster mode로 만들어지고, 이는 로드밸러서와 유사하다. 여러개의 머신에 Redis 캐시를 배분할 수 있게 된다.
높은 수준으로 확장된 애플리케이션들은 캐싱의 장점을 충분히 수용하고 있고, 이는 빠른 API를 만드는데 있어서 아주 필수적인 부분이다. 더 좋은 쿼리와 더 좋은 퍼모먼스의 코드는 문제의 한 부분이다. 하지만, 캐시 없이는, 수백만의 유저들을 수용할만큼 확장할 수 없을 것이다.
참고
Redis(레디스)란? Redis, 레디스 레디스 소개 및 아키텍처, 주의할 점(Redis Overview, Redis Architecture, Tool Tip)
Read Replicas
데이터베이스에 대한 타격을 줄이기 위한 또다른 방법은 DBMS를 활용하여 읽기용 복제본을 추가하는 것이다. 관리 서비스를 활용한다면, 이것은 one-click으로 만들 수 있다. 읽기용 복제본은 master DB를 바탕으로 최신 상태의 데이터를 유지하고, SELECT 구문만 사용 가능하다.
더 나아가서
앱을 계속 확장하면서, 우리는 서비스를 독립적으로 확장하는 것에 초점을 두어야 한다. 예를 들면, 우리가 만약 웹소켓을 사용한다면, 웹소켓 처리 코드를 빼내는 것이 합리적이다. 우리는 이 코드를 로드밸러서 뒤에 새로운 인스턴스에 올릴 수 있다. 이는 얼마나 많은 HTTP 요청이 들어오는가와 상관없이, 웹소켓 연결이 얼마나 열리고, 닫히는가에 대해서만 확장하고 축소할 수 있다.
또한, 데이터 계층의 한계에 부딪힐 수 있다. 데이터베이스를 sharding하고 partitioning 때이다. 이 두가지 상황은 모두 오버헤드가 발생하지만, 무제한으로 데이터 계층을 효율적으로 확장할 수 있을 것이다.
sharing 이란?
노드 생성, 동작 원리 및 shard란? :: 개인적인공간
우리는New Relic 또는 Datadog와 같은 서비스를 설치하여 모니터링하고 싶어질 것이다. 그럼, 우리는 어떤 요청이 느리고, 어느 부분이 개선되어야 하는 이해하게 될 것이다. 앱을 확장할 때마다, 우리는 병목현상을 찾고, 해결하는 데에 초점을 맞출 것이다. - 앞 섹션에서 말한 아이디어를 적용하면서
