Chapter 1_Database Cluster, Databases, and Tables
This chapter and the next chapter summarize the basic knowledge of PostgreSQL to help to read the subsequent chapters.
This chapter describes the following topics:
- The logical structure of a database cluster
- The physical structure of a database cluster
- The internal layout of a heap table file
- The methods of writing and reading data to a table
If you are already familiar with these topics, you may skip over this chapter.
1.1 데이터베이스 클러스터의 개념적 구조
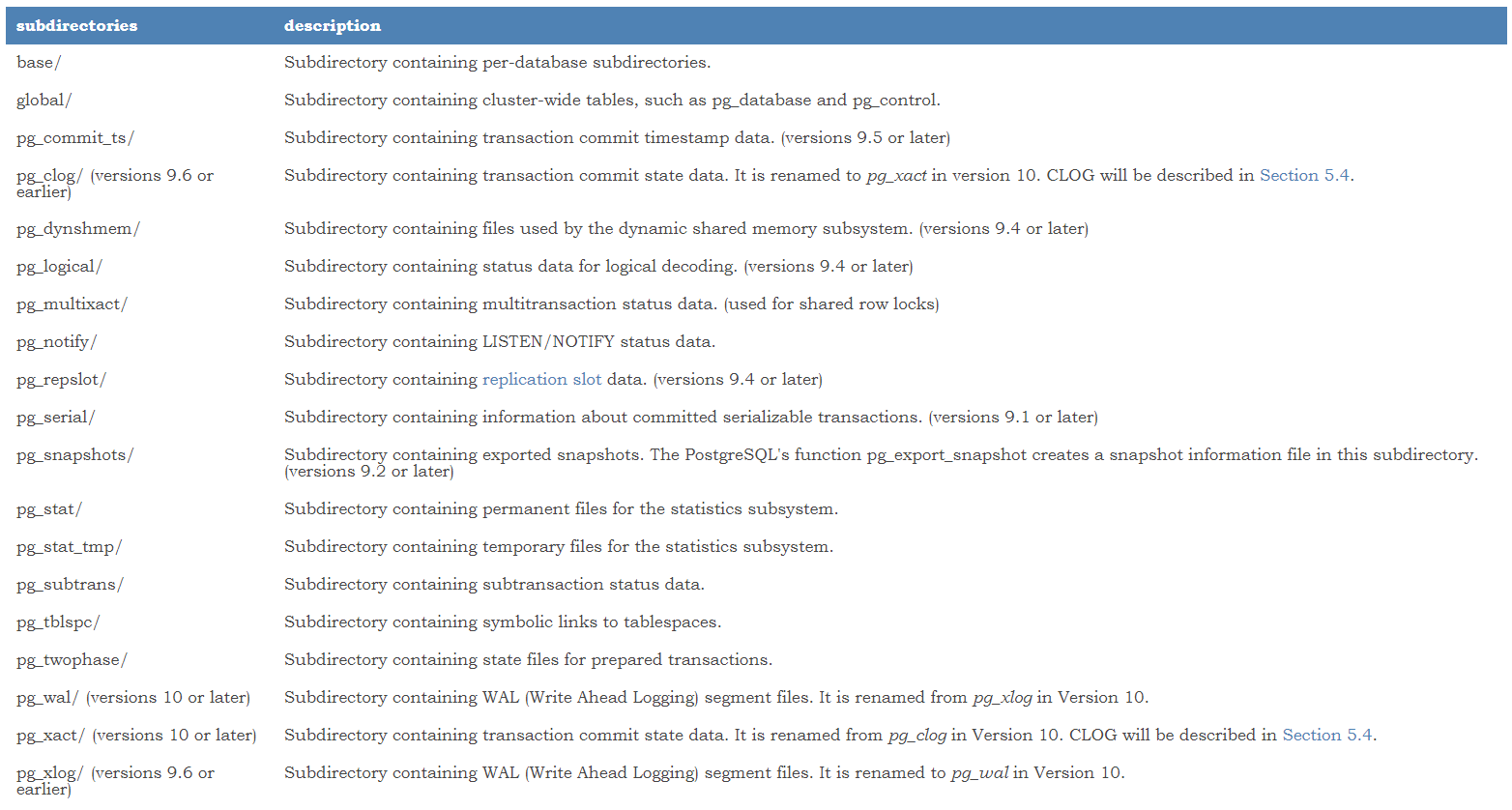
DB cluster: PostgreSQL이 관리하는 여러 DB 파일들의 묶음.
- 이때 DB cluster은 DB Server의 그룹을 뜻하는 것이 아니다.
- PostgreSQL은 단일 server, 단일 cluster로 동작한다.
- DB cluster 내부의 DB들은 각자 논리적으로 독립된 상태로 존재한다.
DB objects: 저장, 참조를 위한 DB structure
- DB 내부를 보면 여러 data structure가 존재한다.
- Such as indexes, sequences, views, functions... 이들 전부 DB object - DB 자체도 일종의 DB object이다.
DB cluster과 DB, 그리고 DB 내부의 요소에 관한 관계는 다음과 같음
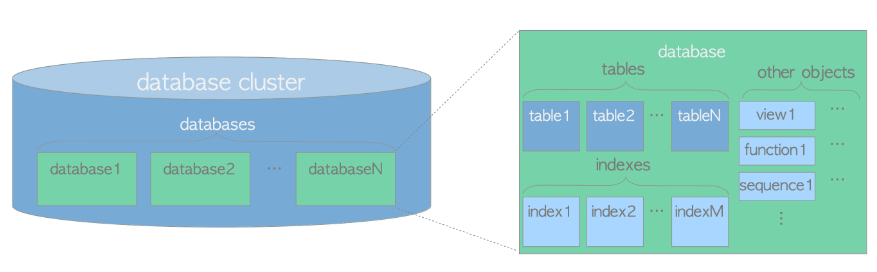
PostgreSQL의 모든 DB object는 object identifier(OIDS)에 의해 관리된다.
OIDS
- 4 byte integer
- system catalogue에서 확인할 수 있음
1.2 데이터베이스 클러스터의 물리적 구조
DB cluster은 기본적으로 single directory이다(= base directory).
DB 파일은 base subdirectory 하위의 subdirectory에 저장됨.
initdb: 새로운 PostgreSQL DB cluster를 생성함.
PGDATA: 특정 하위 directory에 새 DB cluster(base directory)가 만들어지도록 경로를 지정한 변수.
tablespace: 일반적인 RDBMS의 tablespace와 조금 다르다.
base directory 이외의 data를 저장하는 single directory를 의미함.
아래 그림은 PostgreSQL DB cluster 의 물리적 구조를 나타낸 그림이다.
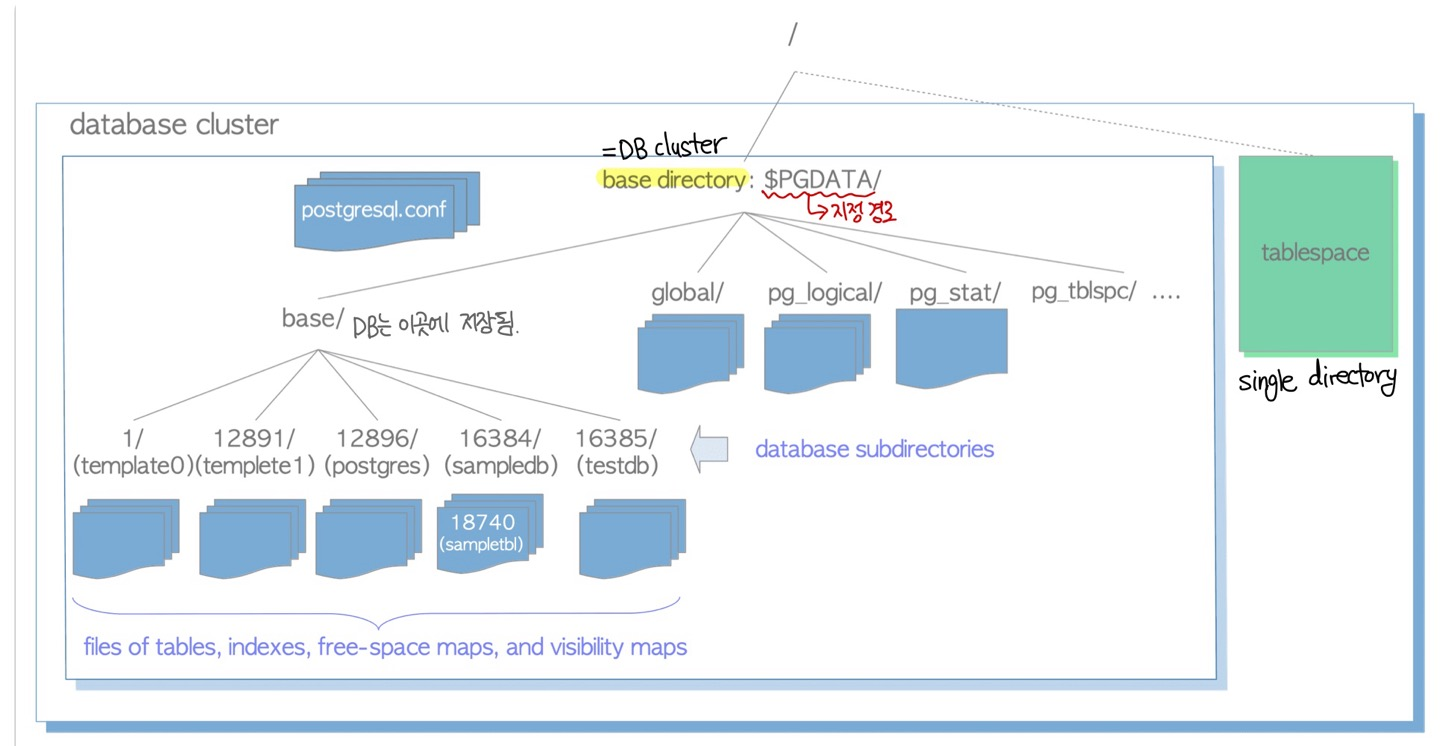
1.2.1 데이터베이스 클러스터의 설계
궁금할 때 찾아 읽는 것으로 하자

1.2.2 데이터베이스의 설계
A database is a subdirectory under the base subdirectory.
DB directory 이름들은 각각의 OID들과 동일하다.
ex) 샘플링된 DB의 OID가 16384인 경우, 그 서브 디렉토리 이름은 16384이다.
$ cd $PGDATA
$ ls -ld base/16384
drwx------ 213 postgres postgres 7242 8 26 16:33 163841.2.3 테이블 및 인덱스와 연관된 파일의 설계
크기가 1GB 미만인 테이블이나 인덱스는 소속된 DB directory 아래에 하나의 파일로 저장된다.
Q. 1GB 단위로 저장되는 것은 PostgreSQL의 default 값인 것인가요?
임의로 설정된 값이어서 변동이 가능한건지, PostgreSQL의 특성상 꼭 1GB로 저장해야 하는 것인지 궁금합니다.
A. 밑에 답변되어있음.
relfilenode: data file 관리
DB의 oid가 내부적으로 테이블과 인덱스를 관리한다.
대체로 oid와 relfilenode 값은 일치하지만 늘 그런 것은 아니다.
sampledb=# SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'sampletbl';
relname | oid | relfilenode
-----------+-------+-------------
sampletbl | 18740 | 18740
(1 row)보다시피 이 경우 oid와 relfilenode 값은 동일하다.
또한 테이블 sample tbl의 데이터 파일 경로가 'base/16384/18740'이라는 것도 알 수 있다. (oid와 DB name 일치함)
$ cd $PGDATA
$ ls -la base/16384/18740
-rw------- 1 postgres postgres 8192 Apr 21 10:21 base/16384/18740relfilenode 값 변경: 명령어 TRUNCATE, REINDEX, CLUSTER 사용하면 됨.
ex) if we truncate the table sampletbl, PostgreSQL will assign a new relfilenode (18812) to the table, removes the old data file (18740), and creates a new one (18812).
sampledb=# TRUNCATE sampletbl;
TRUNCATE TABLE
sampledb=# SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'sampletbl';
relname | oid | relfilenode
-----------+-------+-------------
sampletbl | 18740 | 18812
(1 row)+a (버전 9.0 이상)
pg_relation_filepath: OID 또는 file name 입력 시 해당 파일의 경로를 반환
sampledb=# SELECT pg_relation_filepath('sampletbl');
pg_relation_filepath
----------------------
base/16384/18812
(1 row)Q. 테이블/인덱스의 파일 크기가 1GB를 넘으면?
A. PostgreSQL은 relfilenode.1과 같은 이름의 새 파일을 만들어 사용한다.
새 파일이 채워지면 PostgreSQL은 relfilenode.2와 같은 이름의 또 다른 새 파일을 만들어 저장함.
$ cd $PGDATA
$ ls -la -h base/16384/19427*
-rw------- 1 postgres postgres 1.0G Apr 21 11:16 data/base/16384/19427
-rw------- 1 postgres postgres 45M Apr 21 11:20 data/base/16384/19427.1테이블과 인덱스의 최대 파일 크기 변경하는 법
PostgreSQL을 구축할 때 configuration, option --with-seggsize를 사용하여 변경 가능.
테이블마다 '_fsm'과 '_vm'으로 되어있는 두 개의 파일이 존재한다.
인덱스는 '_fsm'만 있음
_fsm: free space map. 테이블 파일 내의 각 페이지의 여유 공간 용량에 대한 정보를 저장
_vm: visibility map. 테이블 파일 내의 각 페이지의 가시성에 대한 정보를 저장
$ cd $PGDATA
$ ls -la base/16384/18751*
-rw------- 1 postgres postgres 8192 Apr 21 10:21 base/16384/18751
-rw------- 1 postgres postgres 24576 Apr 21 10:18 base/16384/18751_fsm
-rw------- 1 postgres postgres 8192 Apr 21 10:18 base/16384/18751_vm'_fsm'과 '_vm' 파일은 data file의 fork로 생성된다.
data file : fork number 0
free space map : fork number 1
visibility map : fork number 2
1.2.4 테이블스페이스
A tablespace in PostgreSQL is an additional data area outside the base directory.
tablespace에 관한 레이아웃은 다음과 같다.
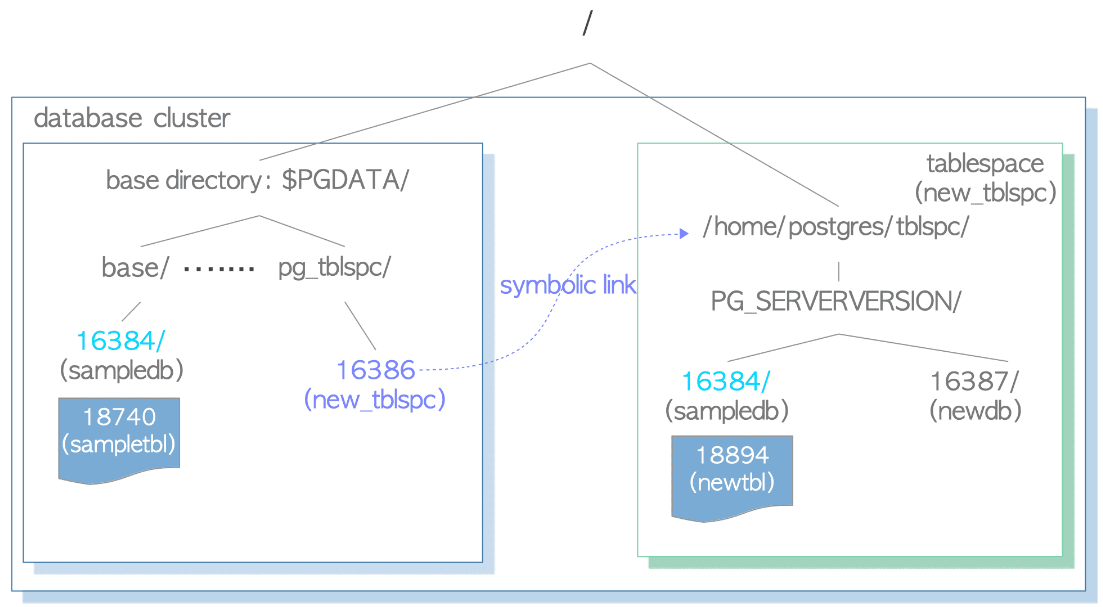
CREATE TABLESPACE를 실행할 때 지정된 디렉토리 아래에 테이블스페이스가 생성된다. 그 디렉토리 아래에 version-specific subdirectory가 생성된다.
version-specific subdirectory 네이밍 규칙
PG _'Major version'_'Catalogue version number'
예를 들어, '/home/postgres/tblspc'에 OID가 16386인 테이블스페이스 'new_tblspc'를 만들면 해당 테이블스페이스 하위에 'PG_14_202011044'라는 이름의 서브디렉토리가 생성된 것을 확인할 수 있다.
$ ls -l /home/postgres/tblspc/
total 4
drwx------ 2 postgres postgres 4096 Apr 21 10:08 PG_14_202011044테이블스페이스 디렉토리는 pg_tblspc subdirectory에서 심볼릭 링크로 주소가 지정된다. 링크명은 테이블스페이스의 OID 값과 동일
$ ls -l $PGDATA/pg_tblspc/
total 0
lrwxrwxrwx 1 postgres postgres 21 Apr 21 10:08 16386 -> /home/postgres/tblspc테이블스페이스 하위에 새 데이터베이스(OID 16387)를 작성하면 해당 DB directory가 version-specific subdirectory 하위에 생성된다.
$ ls -l /home/postgres/tblspc/PG_14_202011044/
total 4
drwx------ 2 postgres postgres 4096 Apr 21 10:10 16387base directory 하위에 작성된 데이터베이스에 속하는 새로운 테이블을 작성하면, 먼저 version-specific subdirectory 아래에 새로운 디렉토리가 작성된다. 새로운 디렉토리의 이름은 기존 데이터베이스의 OID와 동일하다. 그 뒤엔 새로 생성된 디렉토리 아래에 새로운 테이블 파일을 배치한다.
sampledb=# CREATE TABLE newtbl (.....) TABLESPACE new_tblspc;
sampledb=# SELECT pg_relation_filepath('newtbl');
pg_relation_filepath
---------------------------------------------
pg_tblspc/16386/PG_14_202011044/16384/188941.3 힙 테이블 파일의 내부 레이아웃
데이터 파일(heaptable, index, free space map, visibility map)은 고정된 길이의 페이지(또는 블록)로 나뉘는데, 이는 기본적으로 8192바이트(8KB)이다.
block numbers : 각 파일 내의 페이지에 0부터 순차적으로 매겨진 번호
파일이 가득 차 있으면 PostgreSQL은 파일의 말단에 빈 페이지를 새로 추가하여 파일 크기를 키운다.

페이지의 내부 레이아웃은 데이터 파일 형식에 따라 달라진다.
페이지는 세 가지 종류의 데이터를 담고있다 :
1. heap tuple :
- record data itself
- stacked in order from the bottom of the page
2. line pointer (=item pointer)
- 4 bytes long
- holds a pointer to each heap tuple
- form a simple array that plays the role of an index to the tuples
- offset number : 튜플의 인덱스 번호. 1부터 순차적으로 번호가 매겨짐.
- 새로운 투플이 페이지에 추가되면 새로운 라인 포인터도 배열 위로 밀어 올려 새로운 투플을 가리키게 됨.
3. header data
- 24 byte long
- defined by the structure PageHeaderData
- allocated in the beginning of the page
- contains general information about the page
- PageHeaderData 구조체의 변수
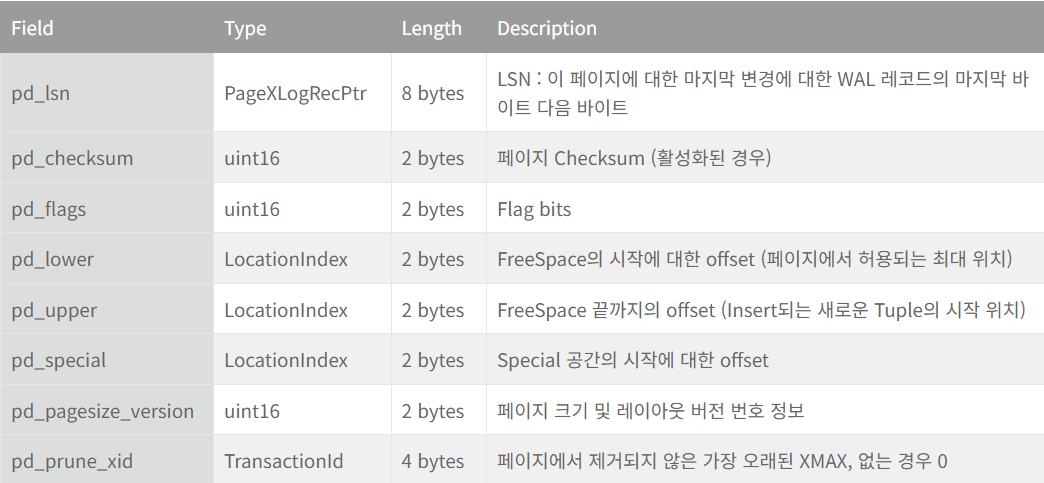
The structure PageHeaderData is defined in
src/include/storage/bufpage.h
페이지에는 Line Pointer와 Item 사이에 여유 공간(아무것도 할당되지 않은 공간)이 남아있을 수 있다.
FreeSpace(=hole) : 마지막 Line Pointer의 끝과 최신 Item의 시작 사이의 빈 공간
새로운 ItemId(Line Pointer)는 이 영역의 시작 부분부터 할당되고, 새로운 Item(Tuple)은 이 영역의 끝부분부터 할당된다.
PostgreSQL은 해당 영역에 아무것도 추가할 수 없을 때 페이지가 가득 찬 것으로 판단하고, 공간 확보를 위해 파일 끝에 빈 페이지를 추가한다.
TID(=tuple identifier) : 테이블 내에서 튜플을 식별하기 위해 사용되는 식별자. (block number, offset number) 한 쌍의 값으로 이루어져 있다.
1.4.1 투플을 쓰는 방법
투플을 쓰는 방법을 이해하기 위해, 오직 하나의 힙 튜플을 포함하는 하나의 페이지로 구성된 테이블을 가정한다.
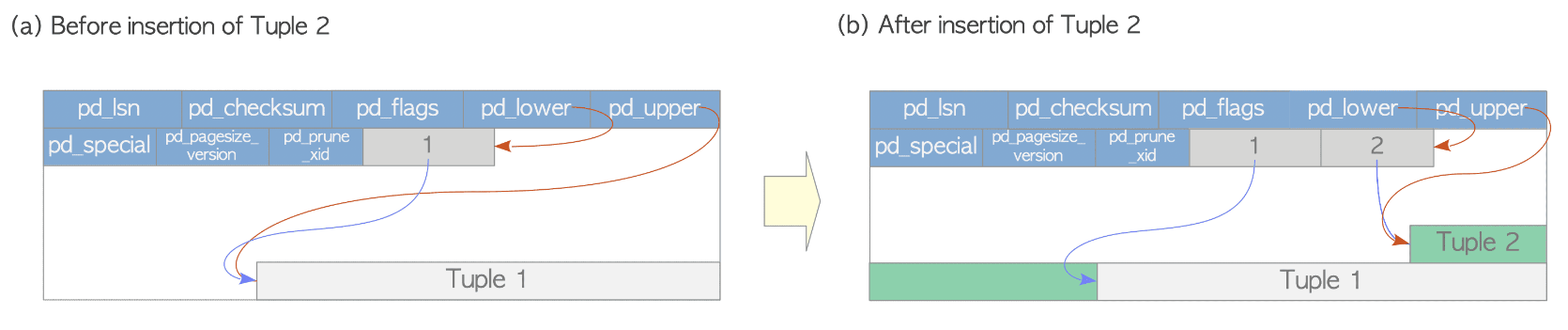
이 페이지의 pd_lower는 라인 포인터 1을 가리키고, 라인 포인터 1과 pd_upper point는 모두 Tuple 1을 가리킨다.
(그림 (a) 참조)
Tuple 2가 삽입되면 밑에서부터 순차적으로 쌓이기 때문에, Tuple 1 앞에 배치된다. 라인 포인터 2는 라인 포인터 1 뒤에 추가되고, Tuple 2를 가리킨다. pd_lower는 라인 포인터 2를 가리키고, pd_upper는 Tuple 2를 가리키도록 변경된다.
(그림 (b) 참조)
이 페이지 내의 다른 헤더 데이터 (ex) pd_lsn, pg_checksum, pg_flag 또한 적절한 값으로 업데이트된다.
1.4.2 투플을 읽는 방법
투플을 읽는 방법은 두 가지가 있다 :
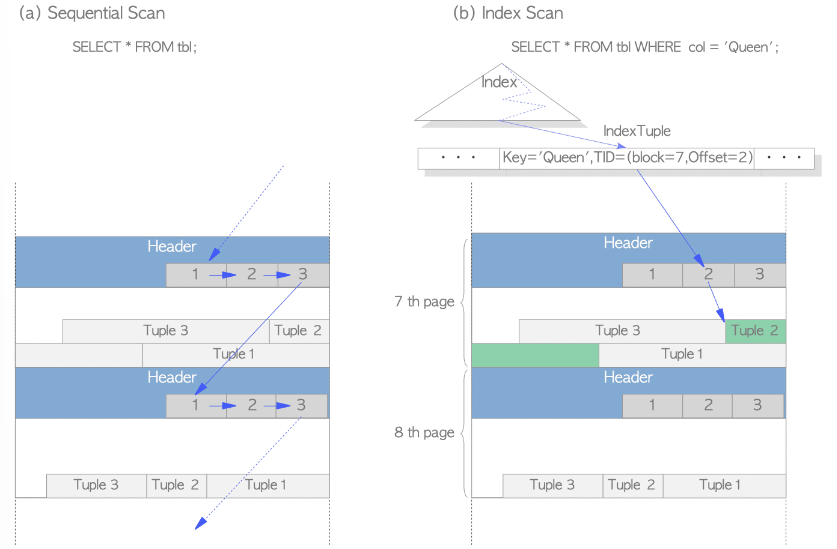
(a) sequential scan
각 페이지의 모든 line pointer를 스캔하여 모든 페이지의 모든 튜플을 순차적으로 읽어들임.
(b) B-tree index scan
index file : 인덱스 튜플을 포함하는 파일. 각 인덱스 튜플은 인덱스 키와 타겟 힙 튜플을 가리키는 TID로 구성됨.
찾고자 하는 키를 가진 인덱스 튜플을 찾았다면 PostgreSQL은 TID 값을 이용하여 원하는 힙 튜플을 읽는다.
예를 들어, 그림 (b)에서 획득한 인덱스 튜플의 TID 값은 '(블록 = 7, 오프셋 = 2)'이다. 이는 타겟 힙 튜플이 테이블 내의 7번째 페이지에서 두 번째 튜플임을 뜻하므로 PostgreSQL은 페이지에서 불필요한 스캔 없이 원하는 힙 튜플을 읽을 수 있게 된다.
