OVERVIEW
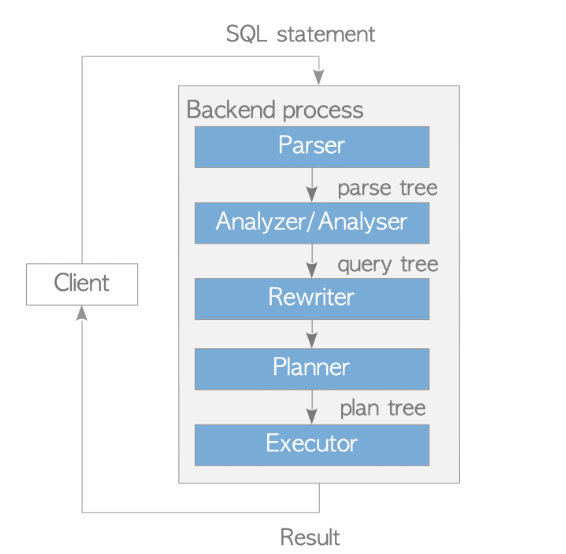
PostgreSQL의 경우, 9.6 버전에서 구현된 병렬 쿼리는 여러 백그라운드 워커 프로세스를 사용하지만, 기본적으로 하나의 백엔드 프로세스가 연결된 클라이언트로부터 발행된 모든 쿼리를 처리한다. 이 백엔드는 다섯 개의 서브시스템으로 구성되어 있다.
1. Parser
일반 텍스트로 된 SQL 문을 파스 트리로 변환
2. Analyzer/Analyser
파스 트리 분석 & 쿼리 트리 생성
3. Rewriter
규칙 시스템에 저장된 규칙에 기반하여 쿼리 트리를 변형
4. Planner
쿼리 트리에서 가장 효과적으로 실행될 수 있는 플랜 트리를 생성
5. Executor
플랜 트리에서 생성된 순서대로 테이블과 인덱스에 액세스하여 쿼리를 실행
3.1.1. Parser
파서는 일반 텍스트의 SQL 문으로 후속 서브시스템에서 읽을 수 있는 파스 트리를 생성한다.
다음 쿼리를 예시로 들어보면,
testdb=# SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;다음 그림 (b) 에서는 (a)에 나타난 쿼리의 파스 트리를 설명하고 있다.
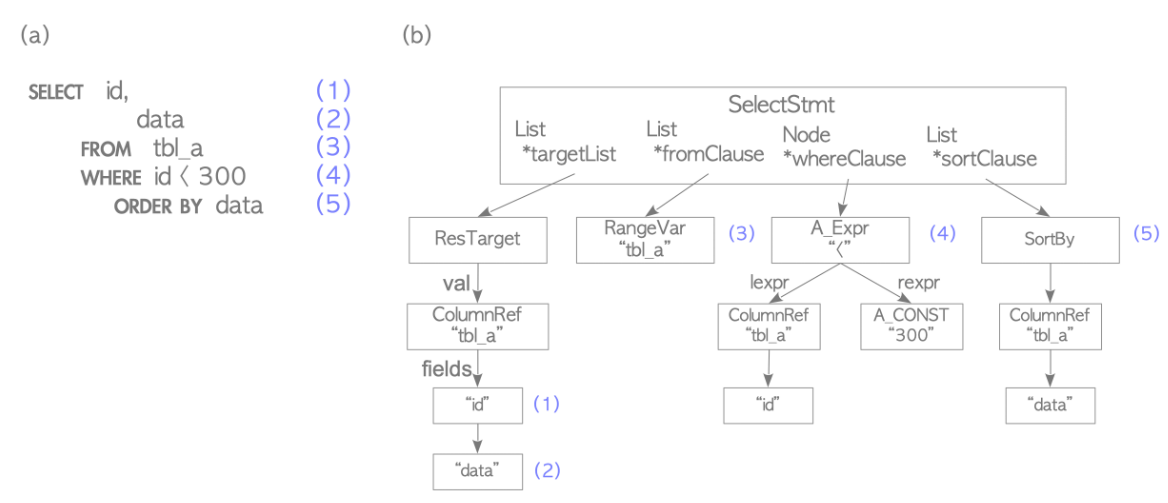
SELECT 쿼리의 요소와 해당하는 파싱 트리의 요소는 동일한 번호가 매겨진다. 예를 들어, (1)은 테이블의 'id' 열이다. (2)는 테이블의 'data'열이다.
파서는 파스 트리를 생성할 때 입력의 구문만을 확인한다. 따라서 쿼리에 구문 오류가 있는 경우에만 오류를 반환한다.
파서는 입력 쿼리의 의미를 확인하지 않는다. 예를 들어, 쿼리에 존재하지 않는 테이블 이름이 포함되어 있더라도 파서는 오류를 반환하지 않는다. 의미론적인 체크는 Analyzer/Analyser에서 수행된다.
3.1.2. Analyzer/Analyser
analyzer/analyser는 parser에 의해 생성된 파스 트리의 의미 분석을 수행하고 쿼리 트리를 생성한다.
Query 구조체에는 해당 쿼리의 유형 (SELECT, INSERT 등)과 여러 개의 leaf가 포함되어 있다. 각 leaf는 리스트나 트리를 형성하며 개별적인 절에 대한 데이터를 보유하고 있다.
다음은 위 sql문 (a)의 쿼리에 대한 쿼리 트리를 보여준다.
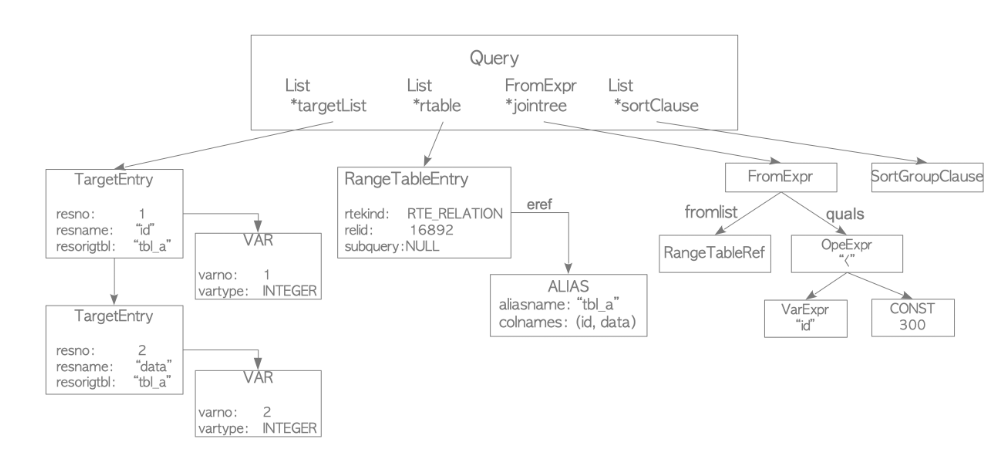
위 쿼리 트리는 간단히 다음과 같이 설명된다:
targetlist는 이 쿼리의 결과로 나타나는 열들의 목록이다. 이 예에서는 SELECT id, data를 했기 때문에 목록이 'id'와 'data' 두 열로 구성되어 있다. 입력 쿼리 트리에서 '∗'를 사용하는 경우 analyzer/analyser는 명시적으로 이를 모든 열로 대체한다.
Range table(=rtable)은 이 쿼리에서 사용되는 relation들의 목록이다. 이 예에서는 목록이 'tbl_a' 테이블에 대한 정보를 포함하고 있으며, 테이블의 OID와 테이블의 이름과 같은 정보를 가지고 있다.
jointree는 FROM 절과 WHERE 절을 저장한다.
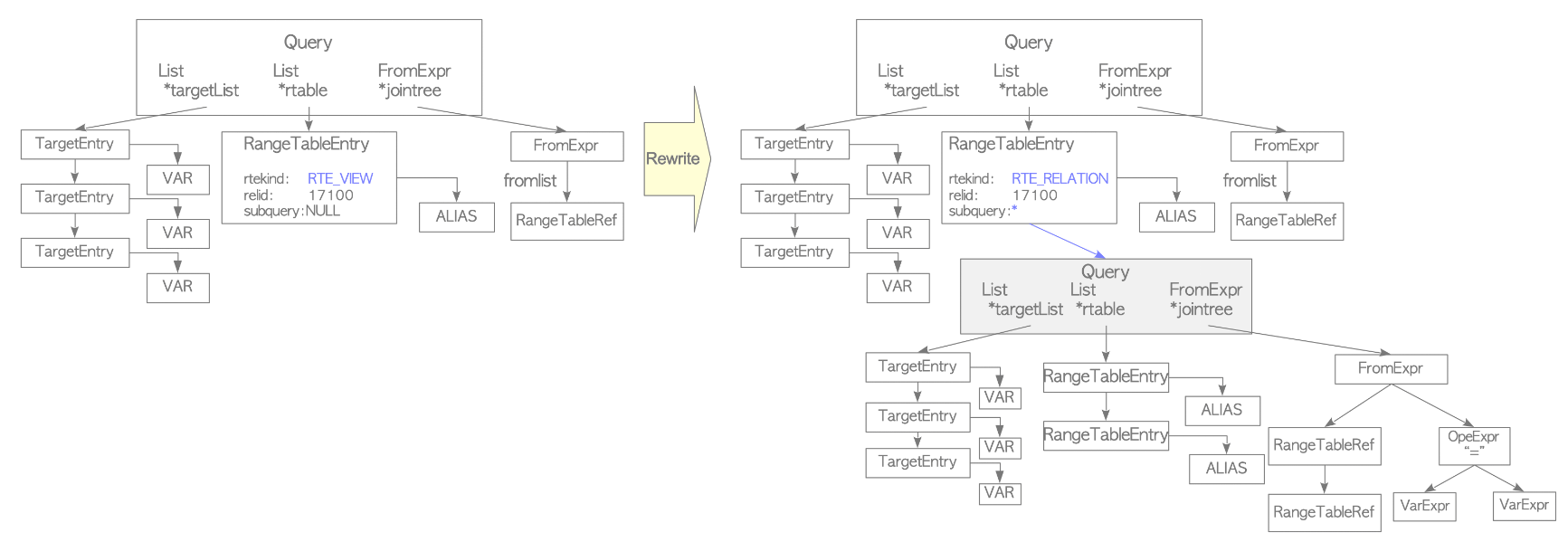
3.1.3. Rewriter
rewriter는 규칙 시스템을 실현하는 시스템이다. 필요한 경우, pg_rules 시스템 카탈로그에 저장된 규칙에 따라 쿼리 트리를 변환한다.
PostgreSQL에서 뷰(Views)는 규칙 시스템을 사용하여 구현된다. CREATE VIEW 명령으로 뷰가 정의될 때, 연관된 규칙이 자동으로 생성되어 카탈로그에 저장된다.
View란?
뷰는 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블이다.
필요한 데이터만 볼 수 있기 때문에 관리가 용이하다는 장점이 있다. 뷰로 구성된 내용에 대한 삽입, 삭제, 갱신, 연산에는 제약이 따른다.
sampledb=# CREATE VIEW employees_list
sampledb-# AS SELECT e.id, e.name, d.name AS department
sampledb-# FROM employees AS e, departments AS d WHERE e.department_id = d.id;위와 같은 뷰가 이미 정의되어 있고 해당 규칙이 pg_rules 시스템 카탈로그에 저장되어 있다고 가정했을 때, 뷰를 포함하는 쿼리가 발행되면 우선 parser는 아래 그림 좌측에 나와 있는 것처럼 파스 트리를 생성한다.
sampledb=# SELECT * FROM employees_list;이 단계에서 rewriter는 pg_rules에 저장된 해당 뷰의 파스 트리를 연결하여 range table 노드를 연결한다. view로 미리 정의된 쿼리 트리를 규칙에 따라 이어붙이는 역할을 한다고 생각하면 될 것 같다.
3.1.4. Planner and Executor
Planner는 rewriter로부터 쿼리 트리를 받아 실행자가 가장 효과적으로 처리할 수 있는 쿼리 플랜 트리를 생성한다.
PostgreSQL의 EXPLAIN은 플랜 트리를 표시한다.
testdb=# EXPLAIN SELECT * FROM tbl_a WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_a (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
(4 rows)이 결과는 다음 그림에 나와 있는 플랜 트리를 보여준다.
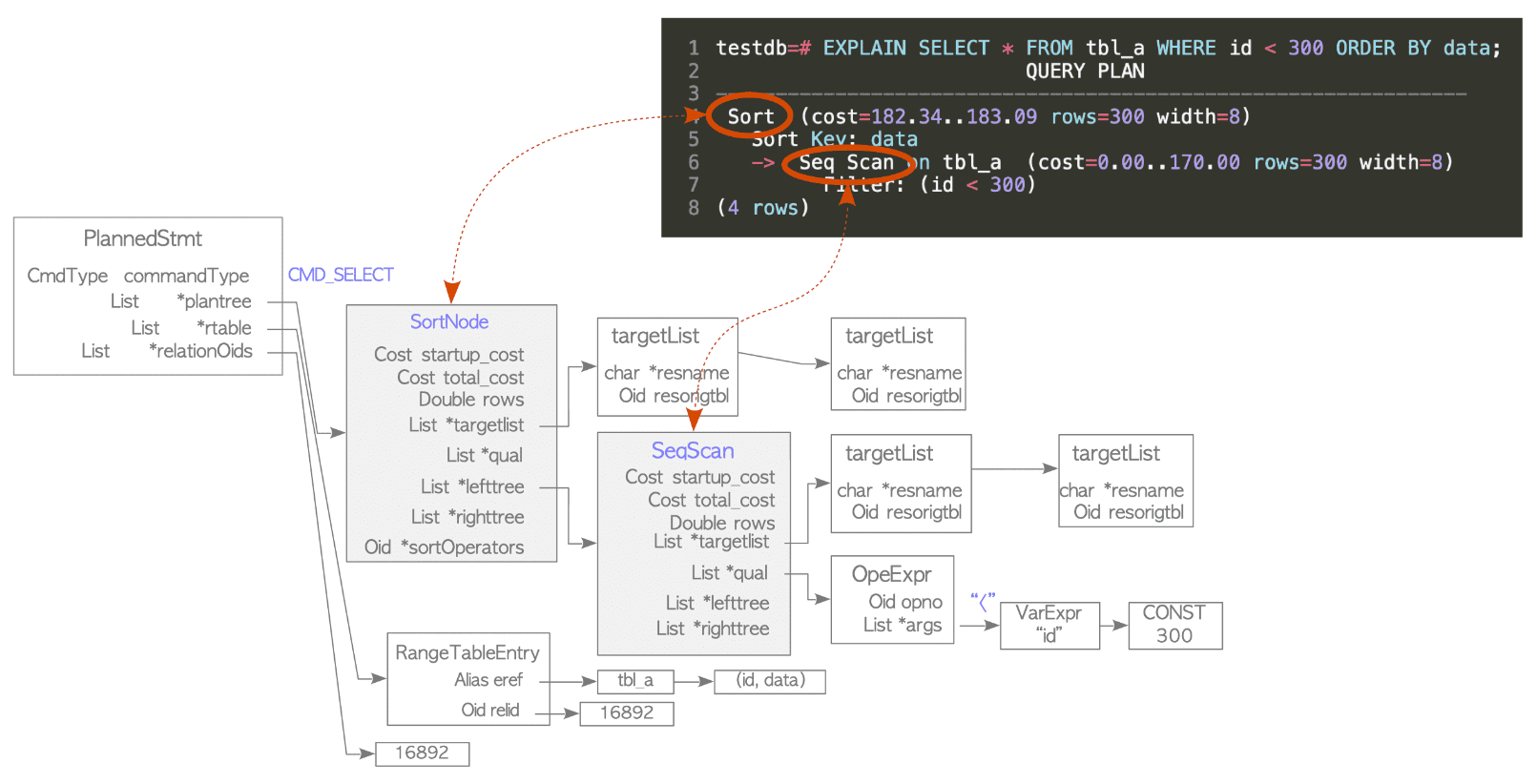
plan tree는 plan node라는 요소로 구성되어 있으며, PlannedStmt 구조체의 plantree 리스트에 연결된다.
executor가 쿼리를 처리하는 과정에서 필요한 정보는 plan node에 위치하고 있다. 단일 테이블 쿼리의 경우, executor는 plan tree의 단말에서 시작하여 루트까지 처리한다.
예를 들어, 위에 나와 있는 *plantree는 SortNode와 SeqScan노드로 이루어져 있는 리스트이다. 따라서 executor는 SeqScan을 통해 tbl_a 테이블을 스캔한 다음 얻은 결과를 정렬한다.
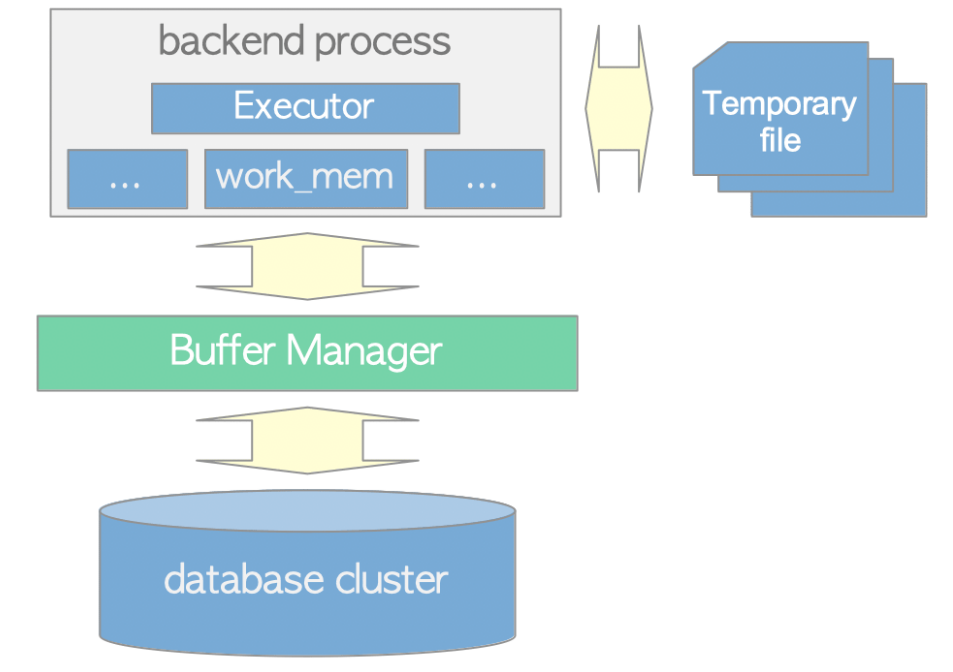
Executor는 버퍼 매니저를 통해 데이터베이스 클러스터의 테이블과 인덱스를 읽고 쓴다. 쿼리를 처리할 때 executor는 미리 할당된 temp_buffers 및 work_mem과 같은 메모리 영역을 사용하며 필요한 경우 임시 파일을 생성한다.