
DATA WAREHOUSING
Data warehouse는 multiple sources에서 모든 정보들을 저장하는 저장소이다. 단일 사이트에 통합된 스키마로 저장되며, historical data를 포함하므로 과거 트렌드에 대한 연구가 가능하다.
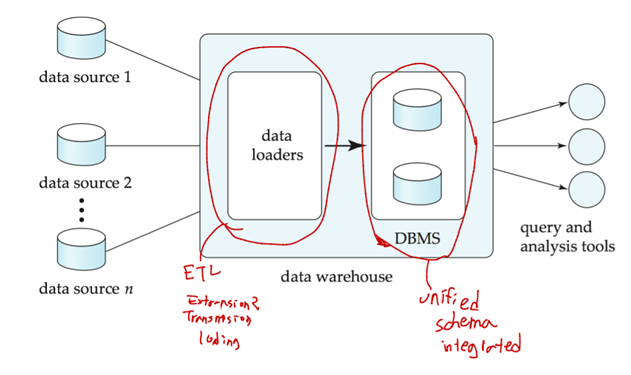
Design Issues
Source driven architecture: data src가 새 정보를 data warehouse로 보낸다.
Destination driven architecture: data warehouse가 data src에게 새 정보를 요청한다.
웨어하우스와 data src를 정확하게 동기화(synchronized)하는 것은 사실 너무 비싸..그래서 웨어하우스에 약간 out-of-dated(오래된) data가 있어도 ok! Data update에는 online transaction(source) processing (OLTP) systems에서 주기적으로 다운로드.
More Warehouse Design Issues
Data transformation and data cleansing
실수 없애고 중복 purge(제거)하고 서로 다른 src에 있는 데이터들 합치고…
How to propagate updates?
src의 원본 데이터가 바뀌면 웨어하우스 스키마에 있는 materialized view 등도 바뀌어야..
What data to summarize
Raw data는 너무 큼. Aggregate values로도 충분함! 그래서 raw data를 query optimizer 사용해서 aggregate values로 바꿔 저장하기도 한다.
Multidimensional Data and Warehouse Schemas
Fact tables: 큰 테이블
Dimension tables: 상대적으로 작은 테이블
Attributes of fact tables can be usually viewed as..
- Measure attributes: 어떤 숫자로 된 값. Aggregated 될 수 있는 값.
- Dimension attributes: 속성을 보여주는 attribute. Id, color…
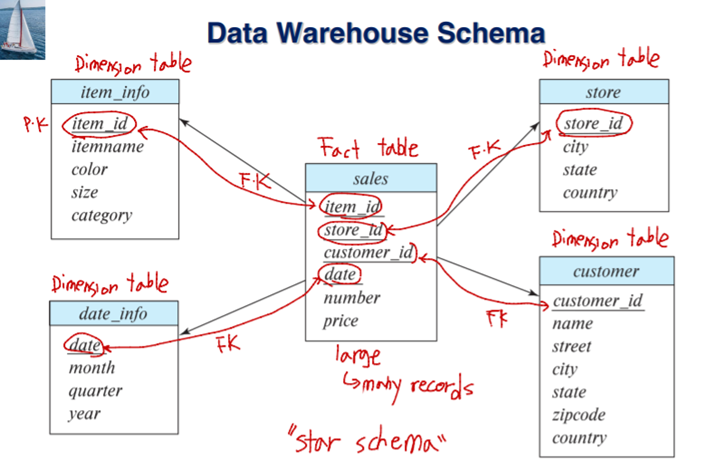
Resultant schema는 star schema라고 불림
Snowflake schema라고 더 복잡한 스키마도 있는데 얘는 multiple levels of dimension tables을 가진다. Fact table도 여러 개일 수 있음.
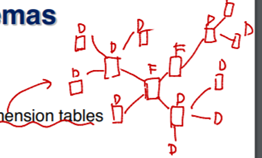
일반적으로.. fact Table이 dimension tables이랑 join된 다음에 dimension table attributes에 group by하고 그 다음에 fact table의 measure attributes에 aggregation을 취한다.
어떤 어플들은 data를 공통 스키마로 가져오는 것이 쓸데없다고 생각함. 그래서 등장한…
Data Lake
schema integration 없이 data를 다양한 format으로 저장할 수 있는 저장소. 초기 노력은 줄지만, 쿼리문 짤 때 더 수고스러움.
Database Support for Data Warehouses
웨어하우스의 데이터는 추가만 되고 업데이트는 안된다.
👉concurrency control overheads를 피할 수 있다.
웨어하우스는 column-oriented storage를 자주 사용한다. (Ex: Id attribute들을 배열로 저장)
👉IO/Memory 비용 절감
Data Mining
data maning은 큰 db를 반자동으로 분석하여 유용한 패턴을 찾는 과정. 머신 러닝과 비슷하지만, 더 큰 볼륨의 데이터를 다룬다.
Data mining는 knowledge discovery in databases (KDD)의 파트 중 하나이다. 어떤 유형의 knowledge는 rule로 표현될 수 있다. 일반적으로, knowledge은 과거의 데이터 인스턴스에 기계 학습 기술을 적용하여 모델을 형성함으로써 발견된다. 그런 다음 새 인스턴스를 예측하는 데 모델을 사용한다.
Types of Data Mining Tasks
Prediction는 과거의 history를 기반으로 한 것.
Some examples of prediction mechanisms
- Classification: 어떤 item이 어떤 class에 속하는지 예측. Training instances(past history)에 value랑 클래스가 제공됨(라벨링 된 학습데이터라고 이해하면 될 듯)
- Regression formulae(회귀 공식): unknown function의 매핑 집합에 대해, 새로운 parameter value에 대한 function result를 예측.
Descriptive Patterns
- Associations(연관성): 특정 유형의 고객들이 좋아하는 책들이 있다면, 그 유형에 속하는 고객 A는 그 책을 좋아할 확률이 높다. (추천 시스템) Associations은 causation(인과관계)를 탐지하는 첫 번째 단계로 쓸 수 있다.
- Clusters(grouping): 예) 장티푸스 환자의 분포를 보니 오염된 우물 근처에 많더라.. 클러스터 탐지는 전염병 탐지에 중요함
Classification Rule
Classification Rule은 새 obj를 class에 배정하는 걸 돕는다.
Ex: 새 자동차 회사가 시장에 들어갈 때 리스크는 어느정도? 클래스1-위험 클래스2-보통- 클래스3- 안전
이러한 Classification Rule에는 다양한 데이터가 사용될 수 있다. 교육수준, 나이 등등.. (ex 수입이 얼마 이상이면 안전…)
Rule은 항상 맞는 건 아니고, 가끔 틀릴 때도 있다. 이러한 Classification Rule은 Decision Tree로 나타낼 수 있다.
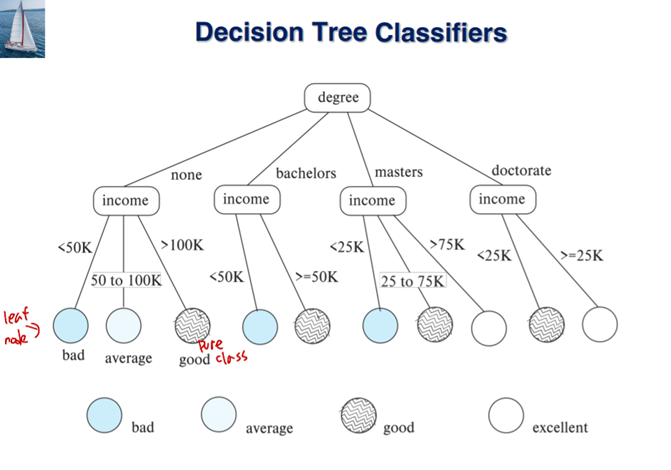
Decision tree는 partitioning attribute와 partitioning condition에 따라 데이터를 나눔
Leaf node: same 클래스에 속한 모든 item or 모든 조건이 다 고려돼서 분기가 끝난 상태 (트리에서 끝)
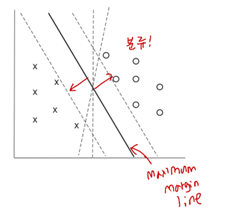
Support Vector Machine Classifiers
maximum margin line: 두 클래스를 가장 잘 나누면서 거리가 가장 먼 선.
Support Vector Machine
2개가 아니라 n개로 분류한다면? SVMs은 직선이 아닌 곡선 separators를 사용할 수 있다.
✔ Transformation functions은 비선형이고 kernel functions이라고 불림.
✔ separators는 transformed space에서는 plane(평면)이고, original space에서는 곡선
정확한 separators가 없을수 있음! best separates points 찾는다.
N-ary classification can be done by N binary classifications. 클래스에 속하는지 아닌지…
Neural Network Classifiers
인공 신경망은 여러 개 레이어를 가짐. Weight of edge가 분류의 핵심! 각 output value를 보고 어떤 class에 속하는지 분류.
Backpropagation algorithm: weight 조정에 쓰임
Deep learning: 매우 많은 training instance에 대한 deep neural network의 훈련
CNN-이미지 분류, RNN-text processing, and machine translation, speech recognition
Regression
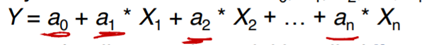
Regression는 클래스 보다는 어떤 값를 예측. 주어진 X들을 가지고 Y를 예측한다. 위 식을 linear regression이라고 부름. Fiting을 통해서 더 최적의 a값 찾는 과정을 curve fitting이라고 함.
a(계수)가 근사값일수 있는데, 그 이유는 noise in the data 혹은 relationship 이 정확한 polynomial(다항식)이 아니기 때문. Regression은 가장 적합한 a값 찾는 것을 목표로 한다.
Association Rules
빵을 산 사람은 우유도 같이 사기 쉽다.( bread =>milk)
- Left head side: antecedent(위 예제에서 빵)
- right hand side: consequent(위 예제에서 우유)
- Population: set of instance.
- Support: satisfies both the antecedent and the consequent of the rule. 전체 경우의 수에서 두 아이템이 같이 나오는 비율(Fragment)
- Confidence: how often the consequent is true when the antecedent is true.(correctness) 빵을 샀을 때 우유를 샀을 확률
Finding Support
메모리를 아끼기 위해, 각 pass마다 일부의 itemset만 고려하는 multiple passes쓴다.
Optimization: 어떤 itemset의 출현 횟수가 작아서 제거했다면, 그거의 supersets을 더 이상 고려 안해도 된다.
Clustering
Clustering: 직관적으로 주어진 데이터들에서 점들의 군집을 찾는 것.
distance metrics을 사용하여 다양한 방식으로 공식화 될 수 있다.
Centroid: 각 차원에서의 좌표의 평균을 취하여 계산된 점.(각 클러스터 안의 어떤 center position)
Hierarchical clustering
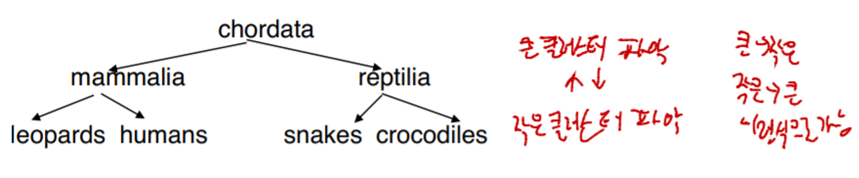
Agglomerative clustering algorithms: bottom up. 작은 클러스터부터 본다.
Divisive clustering algorithms: top-down. 큰 클러스터부터 본다.
Clustering and Collaborative Filtering
어떤 사람의 과거 행적/그 사람과 비슷한 사람의 선호도를 보고 영화,책 등등을 추천.
