목적
Python의 Boto3 라이브러리를 통해 AWS S3 버킷 클라우드에 파일 및 폴더를 관리하는 테스트를 진행해볼 계획이다.
개념
1. Boto3 란?
Python 개발자가 Amazon S3 및 Amazon EC2와 같은 서비스를 사용하는 소프트웨어를 작성할 수 있는 Python용 Amazon Web Services(AWS) 소프트웨어 개발 키트(SDK)
2. AWS S3 (Simple Storage Service) 란?
클라우드 스토리지 | 웹 스토리지| Amazon Web Services
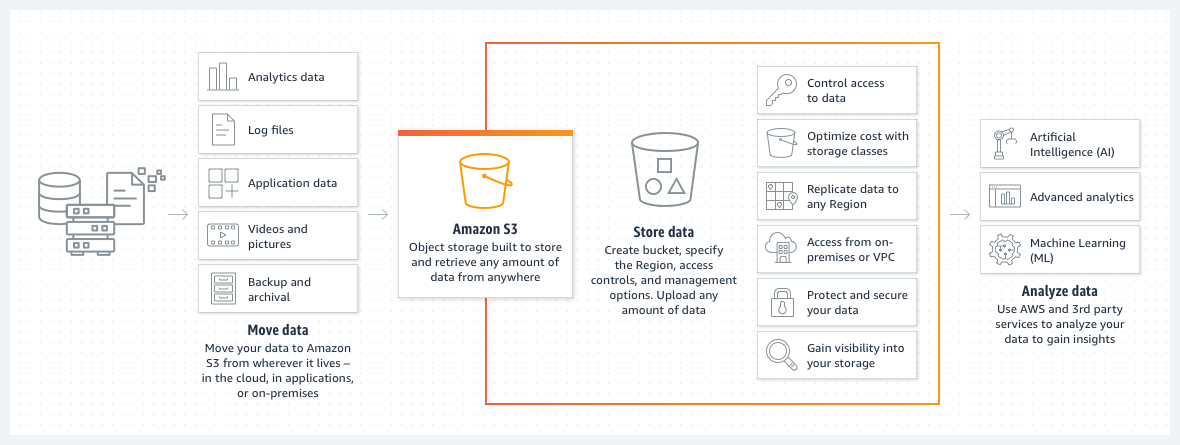
어디서나 원하는 양의 데이터를 검색할 수 있도록 구축된 객체 스토리지로 업계 최고 수준의 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스
실습
전체적인 코드 구조는 다음과 같다.
import boto3
AWS_ACCESS_KEY_ID = '***'
AWS_SECRET_ACCESS_KEY = '***'
AWS_STORAGE_BUCKET_NAME = '버킷 이름'
FILENAME = '업로드/다운로드 할 파일 이름'
KEYNAME = '버킷 상 파일명'
def ManageImg():
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
# 파일 업로드
s3.upload_file(Filename=FILENAME,
Bucket=AWS_STORAGE_BUCKET_NAME, Key=KEYNAME)
# 파일 다운로드
s3.download_file(Bucket=AWS_STORAGE_BUCKET_NAME,
Key=KEYNAME, Filename="원하는 파일명")
# 버킷 파일 삭제
s3.delete_object(Bucket=AWS_STORAGE_BUCKET_NAME, Key="원하는 파일명")
# 버킷의 리스트 확인
contents= s3.list_objects_v2(Bucket=AWS_STORAGE_BUCKET_NAME)['Contents']
for content in contents:
print(content)
# 폴더 포함 업로드
s3.upload_file(Filename=FILENAME,
Bucket=AWS_STORAGE_BUCKET_NAME, Key=f"원하는 디렉토리명/{KEYNAME}")
# 디렉토리 다운로드
contents = s3.list_objects_v2(Bucket=AWS_STORAGE_BUCKET_NAME)['Contents']
for c in contents:
key = c['Key']
directory = '/'.join(key.split('/')[:-1])
fileName = '/'.join(key.split('/')[-1])
if directory == "원하는 디렉토리명":
s3.download_file(Bucket=AWS_STORAGE_BUCKET_NAME,
Key=key, Filename=fileName)
# 폴더 삭제 -> 폴더 안에 객체가 모두 없어지면 자동적으로 없어짐
# 리스트 확인후 컨텐츠 중 해당 폴더에 있는걸 찾고 해당 파일을 모두 제거하면 자동으로 없어짐
contents = s3.list_objects_v2(Bucket=AWS_STORAGE_BUCKET_NAME)['Contents']
for c in contents:
key = c['Key']
directory = '/'.join(key.split('/')[:-1])
if directory == "원하는 디렉토리명":
s3.delete_object(Bucket=AWS_STORAGE_BUCKET_NAME,
Key=key)1. Boto3 라이브러리 설치
→ 우선 라이브러리 설치부터 진행한다.
pip install boto32. AWS Key값, Bucket 정보 가져오기
AWS에서 IAM(역할)을 등록하고 Key값을 가져온다.
IAM에 ‘AmazonS3FullAccess’ 권한을 부여
Key Access Key 발급
AWS_ACCESS_KEY_ID = '***'
AWS_SECRET_ACCESS_KEY = '***'AWS S3의 Bucket을 등록하고 새로운 버킷을 추가한다.
Boto3 라이브러리에서 S3 Client 데이터를 가져오기 위한 Key 값과 Bucket 정보를 가져와 입력
Key Access Key 발급
AWS_STORAGE_BUCKET_NAME = ‘Bucket-Name’3. 업로드할 파일과 Key 설정
Filename : 업로드할 파일의 경로 설정
Key : 버킷 상에 저장할 파일 (파일명 + 파일 형식)
4. 코드 구현
S3 클라이언트 연결
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)→ 이전에 구한 Key값을 입력해 S3의 Client 로그인을 진행
aws_access_key_id : AWS 액세스 키 ID
aws_secret_access_key : AWS 액세스 비밀키파일 업로드
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
# 파일 업로드
s3.upload_file(Filename=FILENAME, Bucket=AWS_STORAGE_BUCKET_NAME, Key=KEYNAME)→ 업로드할 파일(FILENAME)을 정하고 버킷상 저장할 파일명(KEYNAME)을 설정한 후, 버킷과 함께 업로드 진행
- Filename : 업로드할 File Path
- Bucket : 저장할 버킷 명
- Key : 버킷에 저장할 파일 (파일명 + 파일형식)
파일 다운로드
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
# 파일 다운로드
s3.download_file(Bucket=AWS_STORAGE_BUCKET_NAME,
Key=KEYNAME, Filename="원하는 파일명")→ 버킷의 파일(KEYNAME)을 찾아 다운로드할 파일(FILENAME)을 정하고 한 후, 버킷에서 해당 파일을 입력한 File Path로 다운로드 진행
- Bucket : 다운을 진행할 버킷 명
- Key : 버킷에 저장된 파일 (파일명 + 파일형식)
- Filename : 다운로드할 File Path
파일 리스트 출력
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
# 버킷의 리스트 확인
contents= s3.list_objects_v2(Bucket=AWS_STORAGE_BUCKET_NAME)['Contents']
for content in contents:
print(content)→ 입력 한 버킷에 있는 모든 파일 Content를 불러와 출력

- Bucket : 리스트를 가져올 버킷 명
디렉토리 업로드
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
# 디렉토리 포함 업로드
s3.upload_file(Filename=FILENAME,
Bucket=AWS_STORAGE_BUCKET_NAME, Key=f"원하는 디렉토리명/{KEYNAME}")→ 디렉토리를 만들고 파일을 해당 디렉토리에 업로드하는 방식이아닌 디렉토리를 Key값에 입력하면 자동으로 디렉토리가 생성되고 해당 디렉토리 하위에 파일이 저장되는 방식, 나머지 방식은 이전 업로드 방식과 동일하다
- Filename : 업로드할 File Path
- Bucket : 저장할 버킷 명
- Key : 버킷에 저장할 파일 (파일명 + 파일형식)
디렉토리 다운로드
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
# 디렉토리 다운로드
contents = s3.list_objects_v2(Bucket=AWS_STORAGE_BUCKET_NAME)['Contents']
for c in contents:
key = c['Key']
directory = '/'.join(key.split('/')[:-1])
fileName = '/'.join(key.split('/')[-1])
if directory == "원하는 디렉토리명":
s3.download_file(Bucket=AWS_STORAGE_BUCKET_NAME,
Key=key, Filename=fileName)→ 모든 컨텐츠를 확인하여 원하는 디렉토리를 설정해 해당 디렉토리의 하위 파일들을 찾아서 해당 파일을 모두 다운로드하는 형식, 이전 리스트 데이터를 불러오는거와 다운로드의 복합적인 방식이다.
- Bucket : 다운을 진행할 버킷 명
Key : 버킷에 저장된 파일 (파일명 + 파일형식)
Filename : 다운로드할 File Path
폴더 삭제
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
# 폴더 삭제 -> 폴더 안에 객체가 모두 없어지면 자동적으로 없어짐
# 리스트 확인후 컨텐츠 중 해당 폴더에 있는걸 찾고 해당 파일을 모두 제거하면 자동 삭제
contents = s3.list_objects_v2(Bucket=AWS_STORAGE_BUCKET_NAME)['Contents']
for c in contents:
key = c['Key']
directory = '/'.join(key.split('/')[:-1])
if directory == "test":
s3.delete_object(Bucket=AWS_STORAGE_BUCKET_NAME,
Key=key)→ 모든 컨텐츠를 확인하여 삭제할 디렉토리를 설정해 해당 디렉토리의 하위 파일들을 모두 찾고 그 파일들을 모두 제거하면 해당 디렉토리는 자동으로 삭제된다. 이전의 리스트 데이터를 불러오는 것과 파일 삭제의 복합적인 방식이다.
- Bucket : 다운을 진행할 버킷 명
- Key : 버킷에 저장된 파일 (파일명 + 파일형식)
결론
Python에서 제공하는 Boto3 라이브러리를 통해 파일 관리를 진행했습니다. 이를 통해 S3 버킷에 사용자파일을 올리고 관리 할 수 있다는 인사이트를 확보할 수 있었습니다.

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.