벨로그 포스팅 스크래퍼 만들기
벨로그 -> 개인 블로그로 이전을 준비하며
이 많은 게시글을 어떻게 다 옮기지? 라고 생각하다가 스크래핑을 생각해냈다.
우선 내가 만든 개인 블로그는 정적 페이지로 배포하는 것이기 때문에
내가 작성했던 포스팅을 마크다운으로 작성된 md파일로 변환시켜 저장했어야 했다.
처음 간단하게 생각한 것은 puppeteer로 브라우저 켜서, 로그인 한 후에 내 게시글들 수정하기 들어가서 마크다운 파싱된 부분을 다 복사해서 가져오면 되지 않을까? 라고 했는데..
1차 당황..
벨로그는 소셜 계정으로만 계정을 만들 수 있었고, 블로그 계정을 지메일을 쓰는 나는 크로미움 환경에서 로그인을 시도했으나, 안전하지 않은 로그인이라 로그인이 불가능했다.
그렇다면 이걸 어떻게 하지? 하다가 로그인을 하지 않고, 해당 아이디의 게시글의 innerHtml 모두 긁어온 다음에 마크다운으로 다시 파싱하는 방법을 선택했다.
그렇다면 이제 벨로그 스크래퍼를 만들어보자!
설계 방식
- 우선 벨로그 계정 첫 페이지로 들어간다.
-
여기에 제일 아래쪽 까지 스크롤을 내린 다음 모든 벨로그 포스팅 link를 긁어온다
-
각 포스팅 페이지로 진입하여, title, 작성일, 포스팅 내용을 모두 긁어온다.
-
긁어온 내용을 한 페이지당 하나의 마크다운으로 파싱한다.
사용한 라이브러리
- 스크래퍼 : puppeteer
예전에도 작성한 적이 있는데, node.js와 찰떡이라는 구글에서 제공하는 라이브러리이다. - 파서 : turndown
html -> 마크다운으로 파싱을 해주는 라이브러리이다.
시작
yarn add puppeteer우선 라이브러리를 설치한다.
1. 브라우저 열고 메인 페이지로 이동
async function scrapeVelogPosts(username) {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
page.setViewport({ width: 1200, height: 2000 });
await page.goto(`https://velog.io/@${username}`);
console.log('스크래핑 종료');
}
scrapeVelogPosts(스크랩 해올 유저 아이디);퍼펫티어 메소드를 정리한 글이 있어서 공유해봄
https://velog.io/@jiwonyyy/puppeteer를-사용한-웹사이트-스크래핑-2-퍼펫티어-유용한-method
2. 메인페이지에 도착. 스크롤 젤 아래로 내리기
그런데 벨로그는 포스팅 목록에 무한 스크롤을 구현하고 있기 때문에 스크롤을 제일 아래까지 내리는 작업을 해주어야 한다.
(큰 로직은 index.js 파일에 쓰고, 짜잘한 utils는 파일을 분리하여 써줌)
페이지 안에서 javascript로 document.querySelectorAll()등을 사용하려면 evaluate method를 사용해주어야 한다!
async function scrollToBottom(page) {
await page.evaluate(async () => {
await new Promise((resolve, reject) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.documentElement.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}scrollHeight에 도달할 때 까지 100px씩 아래로 스크롤 하는 함수이다.
3. 링크와 summary 긁어오기
우선 처음에는 링크만 긁어오려 했으나, 추후에 summary를 볼 수 있는 곳이 메인 페이지 밖에 없다는 사실을 깨닫고 코드를 수정하였다 ㅠㅠ
data를 스크랩해올때는 selector를 잘 쓰는 것이 좋다
물론 스크랩 할때 className이 명확하게 써져있는 것이 가장 편한 케이스 이지만..
벨로그의 경우 styled-components로 css작업을 하였는지

className으로 가져오는 것은 맞지 않는 것 같아서, nth-child를 사용하였다.
nth-child는 페이지 구조가 바뀌면 틀어지는 위험성이 있으나.. 어쩔 수 없었다.
- 링크의 경우 해당 컴포넌트의 a태그의 href를 추출했고,
- summary의 경우 해당 컴포넌트의 p태그의 innerText를 추출했다.
- 그리고 {link : "벨로그 링크", summary : "포스팅 요약"} 과 같은 object에 저장하였다.
const postsWithLinkAndSummaries = await page.evaluate(() => {
const linkSelector =
'#root > div:nth-child(2) > div:nth-child(3) > div:nth-child(4) > div:nth-child(3) > div:nth-child(1) > div > a:nth-child(1)';
const links = Array.from(document.querySelectorAll(linkSelector)).map(
(el) => el.getAttribute('href')
);
const summarySelector =
'#root > div:nth-child(2) > div:nth-child(3) > div:nth-child(4) > div:nth-child(3) > div:nth-child(1) > div > p';
const summaries = Array.from(
document.querySelectorAll(summarySelector)
).map((el) => el.innerText);
const postsWithLinkAndSummaries = links.map((link, index) => ({
link: link,
summary: summaries[index],
}));
return postsWithLinkAndSummaries;
});
4. 모든 링크로 페이지 열기
위에서 정의한 postsWithLinkAndSummaries는 아래와 같은 형태일 것이다.
[
{ link: '/@jiwony/제목1', summary: '포스팅 요약' },
{ link: '/@jiwony/제목1', summary: '포스팅 요약' },
{ link: '/@jiwony/제목1', summary: '포스팅 요약' },
];이제 각각의 링크에 들어가서 내용을 스크랩 해오는 작업을 해야할 것이다.
여기서 개인마다 전체 포스팅 개수가 몇개일 지도 모르고, 수백개일 경우 이 모든 링크를 한번에 다 여는 것은 맞지 않기 때문에 한번에 켜지는 최대 탭 개수를 정하여 나눠서 열기로 한다.
let tabCount = 5;
let tabs = new Array(tabCount);
for (let i = 0; i < tabs.length; i++) {
tabs[i] = [];
}
await Promise.all(
postsWithLinkAndSummaries.map(async (postsData, index) => {
tabs[index % tabCount].push(postsData);
})
);postsWithLinkAndSummaries를 각각 5개씩 나누어 배열에 담았다.
물론 전체 포스팅 개수가 별로 없으면 이 작업은 중요하지 않을 수도 있음!
5개씩 link로 페이지를 열어보자
스크랩 해오는 순서는 상관 없기 때문에 (어차피 블로그에서 날짜로 sort해서 보여줄 것임) Promise.all을 써주면 된다.
await Promise.all(
tabs.map(async (linksAndSummaries) => {
const postPage = await browser.newPage();
for await (const linkAndSummary of linksAndSummaries) {
postPage.goto(`https://velog.io${linkAndSummary.link}`);
const post = await scrapPost(postPage, linkAndSummary);
createMarkdownFile(post);
}
})
);각각의 페이지에서 scrapPost함수를 실행하고, 그 결과물로 createMarkdownFile()을 할 것이다.
5. 포스트 제목, 날짜, 내용 스크랩 해오기
이제 포스트 페이지에 들어가서 제목, 날짜, 내용을 스크랩해올 차례이다!
이것만 하면 이제 80%는 다한 셈이다.
scrapPost 기능을 구현해보자!
다행히 콘텐트 부분은 시멘틱 태그가 잘 되어 있었고, 클래스네임도 어느정도 작성이 되어있어서 selector로 데이터를 가져오기가 쉬웠다.
그리고 content부분은 html코드를 markdown으로 파싱하는 작업을 따로 할것이기 때문에 색칠된 부분의 innerHtml을 가져오면 된다.
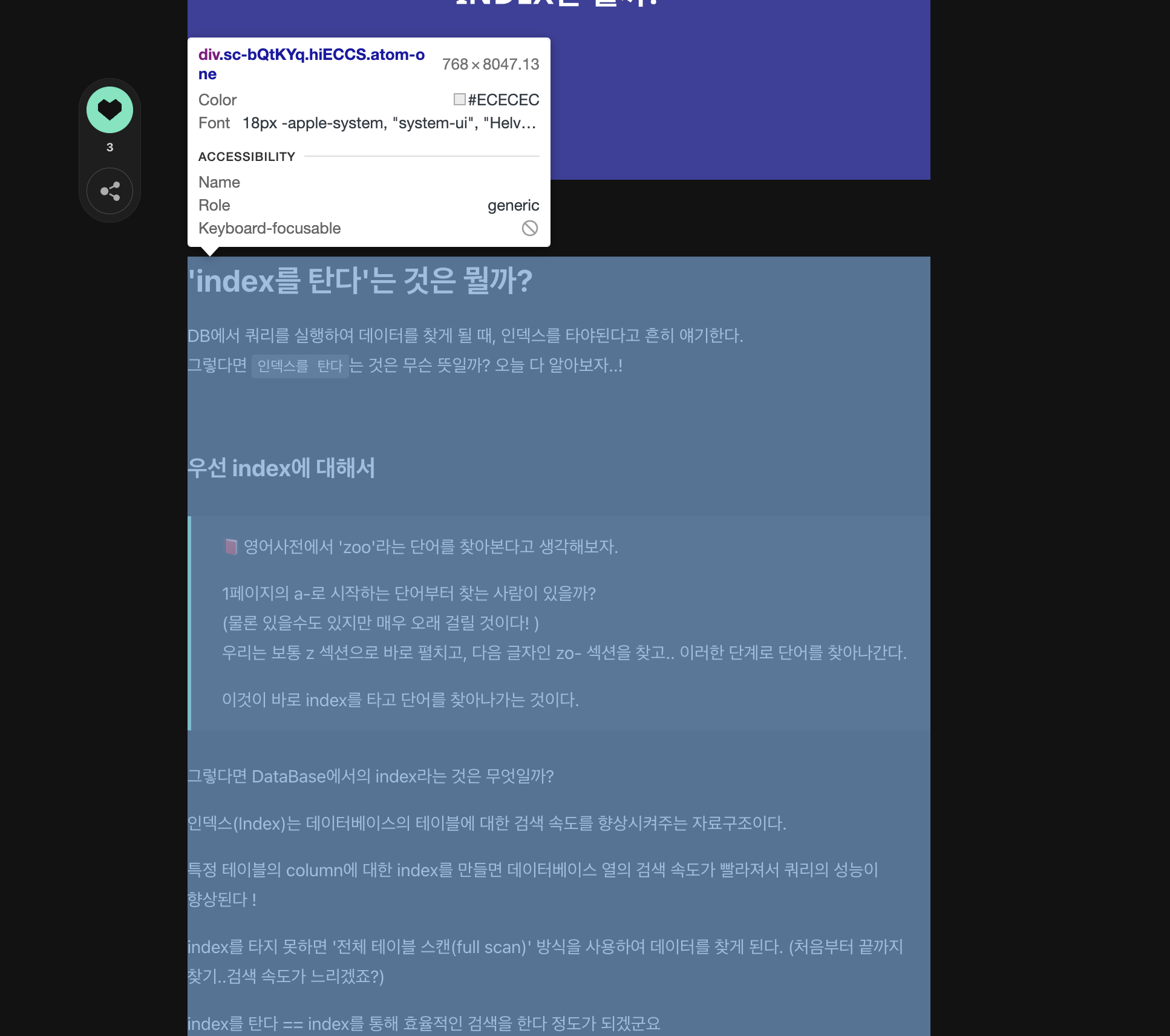
async function scrapPost(page, linkAndSummary) {
try {
await page.waitForNavigation();
await page.waitForSelector('h1:nth-child(1)');
await page.waitForSelector('div.information > span:nth-child(3)');
await page.waitForSelector('div.atom-one');
const postTitle = await page.evaluate(() => {
const selector = 'h1:nth-child(1)';
const title = document.querySelector(selector).innerText;
return title;
});
const postCreatedAt = await page.evaluate(() => {
const selector = 'div.information > span:nth-child(3)';
const createdAt = document.querySelector(selector).innerText;
return createdAt;
});
const postContent = await page.evaluate(() => {
const selector = 'div.atom-one';
const content = document.querySelector(selector).innerHTML;
return content;
});
return {
title: postTitle,
createdAt: postCreatedAt,
content: postContent,
summary: linkAndSummary.summary,
fileName: linkAndSummary.link.split('/')[2],
};
} catch (e) {
console.log('❌❌❌❌', page.url(), e);
}
}[point]
- 날짜의 경우, 7일 내의 경우는
~일 전으로 뜨고, 그 이전의 글의 경우2023년 00월 00일로 뜨는데 일단 긁어와서 파싱해주기로 한다. - 포스트의 제목을 fileName으로 지정할 경우, 띄어쓰기, 특수문자등 때문에 파일 이름을 또다시 파싱해주어야 하는 아주 귀찮은 일이 발생하기 때문에 fileName은 link의 아이디 뒷부분을 사용한다.
6. html을 마크다운으로 파싱하기 (turndown)
라이브러리를 설치하고,
yarn add turndownturn down service를 사용해봅시다!
const TurndownService = require('turndown');convertToMarkdown이라는 함수를 만들어 봅니다.
여기서 난항이었던 점은, turndown은 마크다운으로의 파싱을 지원하지만,
<pre> 태그를 ```과 같이 파싱을 해주진 않는다.
그래서 custom rule을 추가해주어야 한다!
className은 'laguage-js'와 같이 뜨는데, 그중에서 뒤에 언어 부분 'js'만 뽑아와야지 마크다운에서 코드블락이 제대로 보인다.
그렇지 않으면 인식을 못해서 언어별로 코드블락 구분 불가 ㅠㅠ
function convertToMarkdown(html) {
const turndownService = new TurndownService();
turndownService.addRule('pre', {
filter: 'pre',
replacement: function (content, node) {
const language = node.firstChild && node.firstChild.className;
const codeBlock =
'\n```' + (language?.split('-')[1] || '') + '\n' + content + '\n```';
return codeBlock;
},
});
return turndownService.turndown(html);
}7. 날짜 formatting
- 위에서 긁어온 날짜 부분이
6일 전과 같은 포맷도 있고,2023년 03월 01일과 같은 형태도 있다. - 통일된 yyyy-mm-dd 형태로 포매팅 해주는 함수를 만든다.
function formatDateAgo(dateString) {
if (dateString.includes('전')) {
const currentDate = new Date();
const daysAgo = dateString.split('일')[0];
const daysToSubtract = parseInt(daysAgo, 10);
currentDate.setDate(currentDate.getDate() - daysToSubtract);
const year = currentDate.getFullYear();
const month = (currentDate.getMonth() + 1).toString().padStart(2, '0');
const day = currentDate.getDate().toString().padStart(2, '0');
return `${year}-${month}-${day}`;
}
const parts = dateString.split(' ');
const year = parts[0].replace('년', '');
const month = parts[1].replace('월', '').padStart(2, '0');
const day = parts[2].replace('일', '').padStart(2, '0');
return `${year}-${month}-${day}`;
}
8. md 파일로 저장하기
이제 진짜진짜 다왔다. 모든 데이터를 합쳐서 md파일로 저장해본다.
scrapPost 함수로 반환된 값은 다음과 같다.
const post = {
title: postTitle,
createdAt: postCreatedAt,
content: postContent,
summary: linkAndSummary.summary,
fileName: linkAndSummary.link.split('/')[2],
};
이 data를 parameter로 받는 createMarkdownFile 함수를 만든다.
fileSystem.writeFile 함수를 사용해서, 원하는 경로에 해당 md파일을 저장하면 끝!
function createMarkdownFile(data) {
const markdownContent = `---
title: '${data.title}'
date: '${formatDateAgo(data.createdAt)}'
category: ''
summary : '${data.summary}'
---
${convertToMarkdown(data.content)}`;
fs.writeFile(`posts/${data.fileName}.md`, markdownContent, (err) => {
if (err) {
console.error(err);
} else {
console.log(`${data.fileName} 파일 생성완료!`);
}
});
}그리하여 완성된 벨로그 크롤러!
const puppeteer = require('puppeteer');
const { scrollToBottom, scrapPost, createMarkdownFile } = require('./helpers');
async function scrapeVelogPosts(username) {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
page.setViewport({ width: 1200, height: 2000 });
// 벨로그 메인 페이지로 이동
await page.goto(`https://velog.io/@${username}`);
// 무한 스크롤 제일 아래로 내려옴
await scrollToBottom(page);
const postsWithLinkAndSummaries = await page.evaluate(() => {
const linkSelector =
'#root > div:nth-child(2) > div:nth-child(3) > div:nth-child(4) > div:nth-child(3) > div:nth-child(1) > div > a:nth-child(1)';
const links = Array.from(document.querySelectorAll(linkSelector)).map(
(el) => el.getAttribute('href')
);
const summarySelector =
'#root > div:nth-child(2) > div:nth-child(3) > div:nth-child(4) > div:nth-child(3) > div:nth-child(1) > div > p';
const summaries = Array.from(
document.querySelectorAll(summarySelector)
).map((el) => el.innerText);
const postsWithLinkAndSummaries = links.map((link, index) => ({
link: link,
summary: summaries[index],
}));
return postsWithLinkAndSummaries;
});
let tabCount = 5;
let tabs = new Array(tabCount);
for (let i = 0; i < tabs.length; i++) {
tabs[i] = [];
}
await Promise.all(
postsWithLinkAndSummaries.map(async (postsData, index) => {
tabs[index % tabCount].push(postsData);
})
);
await Promise.all(
tabs.map(async (linksAndSummaries) => {
const postPage = await browser.newPage();
for await (const linkAndSummary of linksAndSummaries) {
postPage.goto(`https://velog.io${linkAndSummary.link}`);
const post = await scrapPost(postPage, linkAndSummary);
createMarkdownFile(post);
}
})
);
await browser.close();
console.log('스크래핑 종료');
}
scrapeVelogPosts('jiwonyyy');
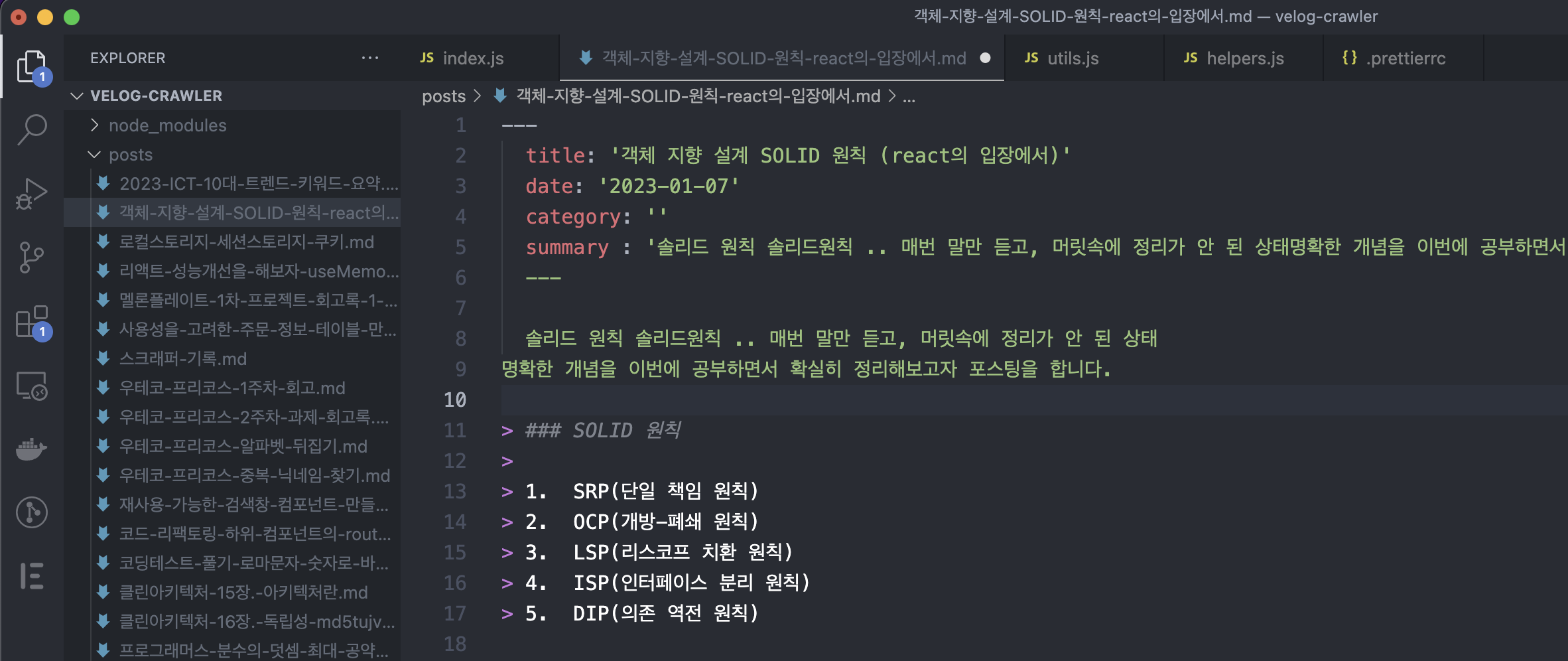
이렇게 파일이 잘 저장되고, auto-format이 안되어있기 때문에 마지막으로 전체 md파일 포매팅 때리기!
yarn prettier -w **/*.md
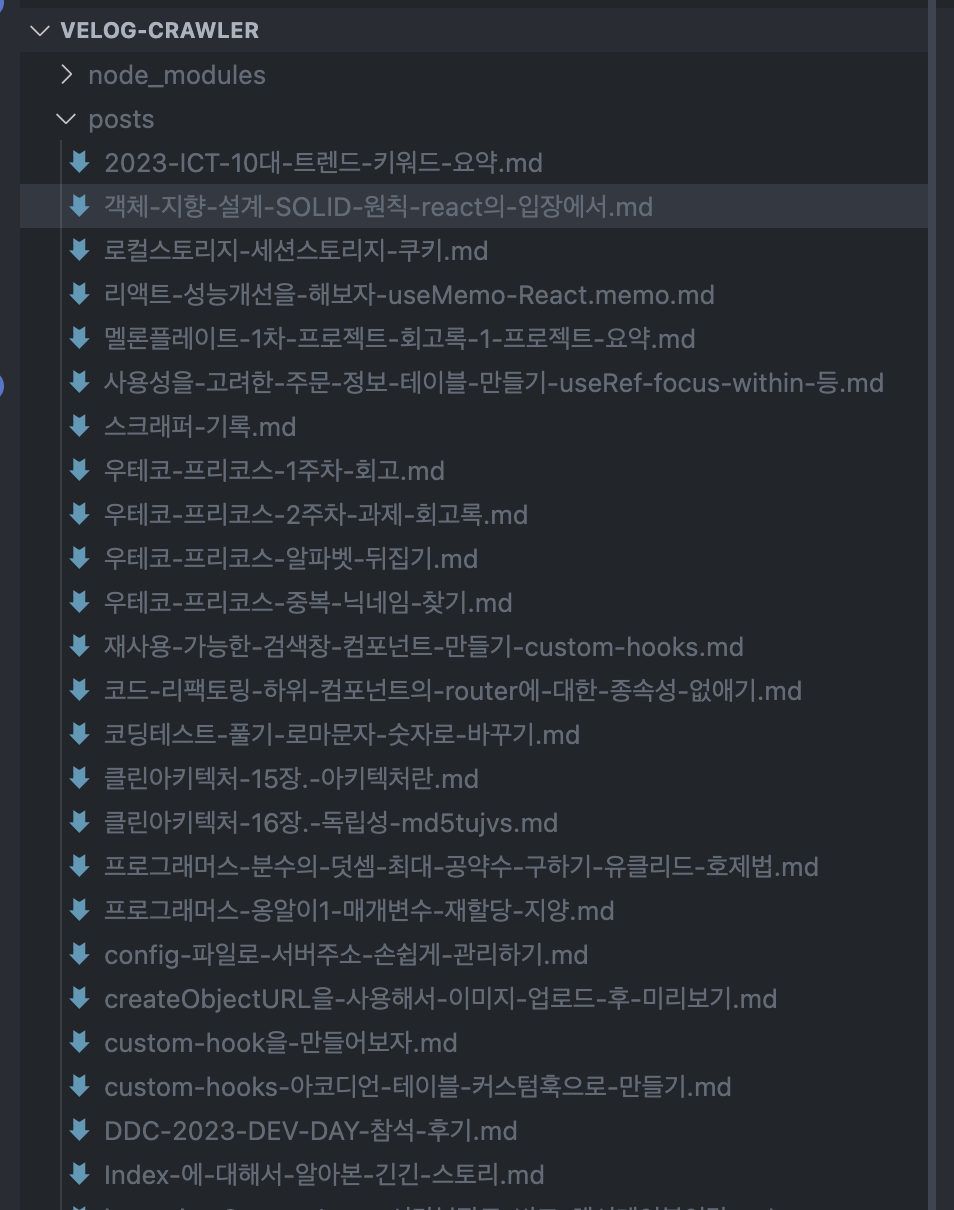
posts가 쌓여있는 내 디렉토리를 보니 아주 뿌듯하다
git ignore에 해당 디렉토리 추가하는거 잊지말기..

와 저도 md 파일로 옮기는거 만들고 있었는데 도움 많이 되었습니다!