
자료 구조는 크게 선형 자료 구조와 비선형 자료 구조로 나뉜다.
선형 자료 구조: 연결 리스트, 배열(선형 리스트), 스택, 큐, 벡터 등.비선형 자료 구조: 트리, 그래프, 해시 테이블, 힙, 맵, 셋, 우선순위 큐 등.
선형 자료 구조 (Linear Data Structures)
선형 자료 구조란 데이터 요소가 일렬로 나열되어 있는 자료 구조를 말한다.
데이터를 순차적으로 저장하고 접근할 수 있으며, 각 요소는 바로 이전 요소와 다음 요소와 관련이 있다.
📌 무작위 접근(직접 접근)과 순차적 접근
무작위 접근(random access): 무작위 접근이란 직접 접근이라고도 하며, 배열에서 특정 요소에 인덱스를 사용하여 직접적으로 접근할 수 있는 능력을 의미한다. 배열의 모든 요소가 메모리 내에서 연속된 위치에 저장되어 있기 때문에 가능한 것이다. 무작위 접근(직접 접근)은 데이터를 저장된 순서로 검색해야 하는순차적 접근과는 반대되는 개념이다.- 무작위 접근(직접 접근)의 예시: 배열에 100개의 요소가 있고, 여기서 42번째 요소에 접근하려면 배열의 시작 위치로부터 41개의 요소를 건너뛰고 42번째 요소에 바로 접근할 수 있다.
1. 연결 리스트 (Linked list)
- 연결 리스트는 데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화시킨 자료 구조이다.
- 연결 리스트의 가장 첫 번째 노드를 헤드(head)라고 부른다. 마지막 노드는 null을 가리킨다. 만약 연결 리스트가 비어있는 경우, head는 null을 참조하게 된다.
1-1. 연결 리스트의 시간 복잡도
▼ 단일 연결 리스트의 시간 복잡도
| 구분 | 접근 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 평균 | O(n) | O(n) | O(1) | O(1) |
| 최악 | O(n) | O(n) | O(1) | O(1) |
- 끝에서 삽입/삭제 시 시간 복잡도: O(1)
- 중간에서 삽입/삭제 시 시간 복잡도: O(n)
▼ 이중 연결 리스트의 시간 복잡도
| 구분 | 접근 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 평균 | O(n) | O(n) | O(1) | O(1) |
| 최악 | O(n) | O(n) | O(1) | O(1) |
- 끝에서 혹은 중간에서 삽입/삭제시 시간 복잡도 모두 동일하게 O(1)
👉🏻 연결 리스트의 종류에 따라 시간 복잡도가 다를 수 있으며, 특히 삽입 혹은 삭제 시 삽입/삭제하는 위치(중간에서 삽입/삭제할지, 끝에서 삽입/삭제할지)에 따라 달라진다.
1-2. 연결 리스트의 장단점
-
장점
-
동적 크기: 연결 리스트는 동적으로 크기를 조절할 수 있으므로, 요소의 추가 및 삭제가 배열보다 효율적이다. 중간에 요소를 추가하거나 삭제할 때, 인접한 요소를 이동할 필요가 없다.
-
빠른 삽입 및 삭제: 위의 설명과 같이 주위의 요소들을 이동시킬 필요가 없으므로 배열에 비해 빠르다.
-
메모리 효율성: 연결 리스트는 요소가 메모리 내에서 연속적으로 저장되지 않으므로, 메모리 공간을 더 효율적으로 활용할 수 있다. 각 요소는 데이터와 다음 요소를 가리키는 포인터로 구성되어 있다.
-
-
단점
-
느린 탐색(빠른 접근이 어려움): 배열과 달리 연결 리스트는 데이터에 무작위 접근(random access)을 할 수 없기 때문이다. 따라서 특정 요소에 접근하기 위해 첫 번째 노드부터 순차적으로만 탐색해야 한다. 이로 인해 배열에 비해 느린 접근 시간(O(n))을 가진다.
-
추가적인 메모리 사용: 각 노드마다 포인터가 필요하므로, 연결 리스트는 배열보다 더 많은 메모리를 사용할 수 있다.
-
불연속적 메모리 사용: 연결 리스트의 요소들은 메모리에서 불연속적으로 저장되므로 캐시 지역성을
활용하기 어렵다.
-
1-3. 연결 리스트는 언제 사용하는 것이 좋을까?
-
크기가 동적으로 변하는 경우: 연결 리스트는 요소를 동적으로 추가하거나 삭제할 수 있는 경우에 적합하다.
-
중간 삽입 및 삭제가 빈번한 경우: 배열은 중간 요소를 추가하거나 삭제할 때 오버헤드가 크지만, 연결 리스트는 이러한 작업에 적합하다.
-
메모리 사용량을 최적화해야 하는 경우: 연결 리스트는 메모리를 더 효율적으로 사용할 수 있으므로, 메모리 사용량을 최소화해야 하는 상황에 적합하다.
-
순차적 접근만 필요한 경우: 연결 리스트는 순차적으로 요소에 접근하는 경우에 배열에 비해 불리하지 않다.
1-4. 연결 리스트의 종류
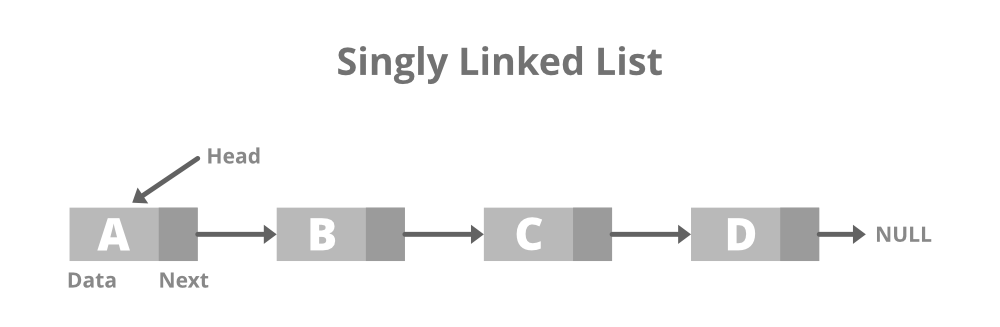
📌 단일 연결 리스트 (Singly Linked List)
- 각 노드는 next 포인터라는 1개의 포인터만 가진다.
- 단일 연결 리스트의 노드는 다음 노드에 대한 참조만 가지고 있기 때문에 노드를 단방향으로 밖에 탐색하지 못한다.
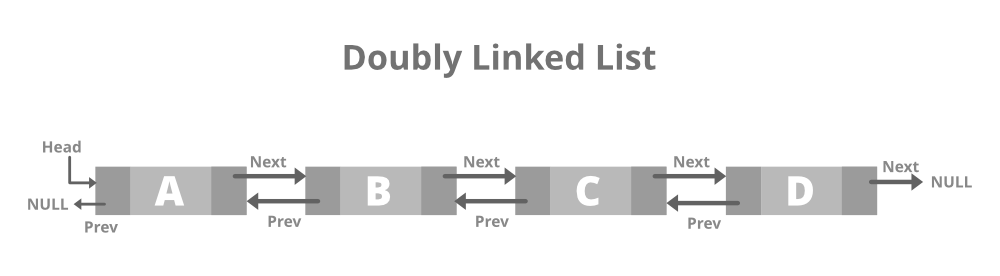
📌 이중 연결 리스트 (Doubly Linked List)
- 각 노드는 next 포인터와 prev 포인터라는 2개의 포인터를 가진다.
- 이중 연결 리스트의 노드는 다음 노드 뿐만 아니라 이전 노드의 참조하여 양방향으로 탐색이 가능하도록 만들어 검색 속도를 향상시킬 수 있는 방법을 제공한다.
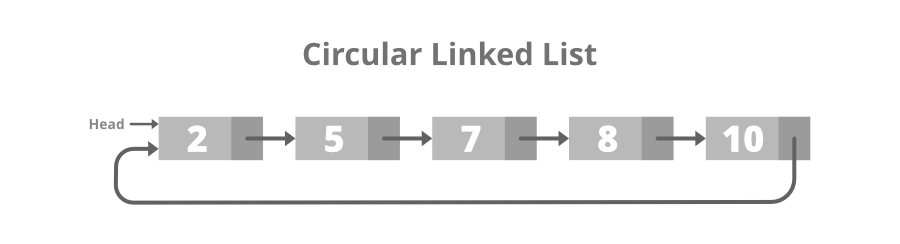
📌 원형 연결 리스트 (Circular Linked List)
- 원형 연결 리스트는 싱글 연결 리스트에서 맨 마지막 노드가 head 노드를 가리키는 마치 루프 형태를 가지는 유형이다.
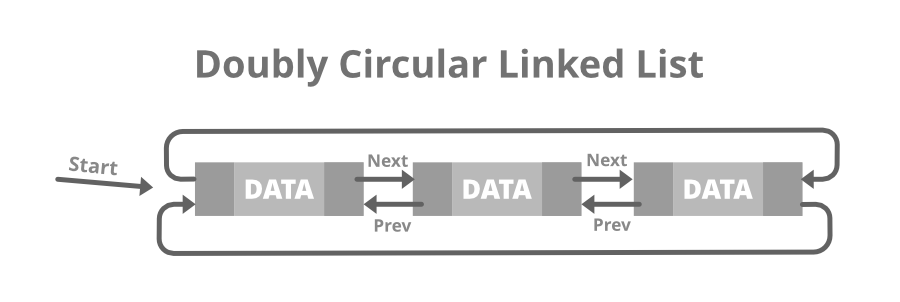
📌 원형 이중 연결 리스트 (Doubly Circular Linked List)
- 이중 연결 리스트와 같지만 마지막 노드의 next 포인터가 head node를 가리킨다.
1-5. JavaScript로 연결 리스트 구현하기 (예제 코드)
- 연결 리스트는 데이터 요소인 Node를 연결하여 선형 데이터 구조를 만드는데 사용된다.
- 각 Node는 데이터(data)와 다음 노드를 가리키는 포인터(next)로 이루어져 있다.
// 연결 리스트 노드 클래스 (각 노드 생성)
class Node {
constructor(data) {
this.data = data;
this.next = null; // 다음 노드를 가리키는 포인터
}
}
// 연결 리스트 클래스 (연결 리스트 구현)
class LinkedList {
constructor() {
this.head = null; // 첫 번째 노드를 가리키는 포인터
}
// 연결 리스트에 새로운 요소 추가
append(data) {
const newNode = new Node(data);
if (!this.head) {
this.head = newNode;
} else {
let current = this.head;
while (current.next) {
current = current.next;
}
current.next = newNode;
}
}
// 연결 리스트 출력하는 method
print() {
let current = this.head;
const result = [];
while (current) {
result.push(current.data);
current = current.next;
}
console.log(result.join(' -> '));
}
}
// 연결 리스트 사용 예제
const linkedList = new LinkedList();
linkedList.append(1);
linkedList.append(2);
linkedList.append(3);
linkedList.append(4);
linkedList.print(); // 출력: 1 -> 2 -> 3 -> 4
2. 배열 (Array)
- 배열은 같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합이다. 또한, 중복을 허용하고 순서가 있다.
- 고정 크기의 메모리 공간에 동일한 데이터 타입의 요소를 연속적으로 저장한다. 각 요소는 인덱스를 사용하여 접근할 수 있다.
2-1. 배열의 시간 복잡도
| 구분 | 접근 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 평균 | O(1) | O(n) | O(n) | O(n) |
| 최악 | O(1) | O(n) | O(n) | O(n) |
2-2. 배열의 장단점
-
장점
-
빠른 접근: 배열은 인덱스를 사용하여 요소에 빠르게 접근할 수 있다. 인덱스를 알고 있다면 배열의 특정 위치에 있는 요소에 즉시 접근할 수 있다. O(1) 시간 복잡도로 접근이 가능하다.
-
메모리 관리: 배열은 메모리 내에서 연속된 공간에 요소를 저장하므로, 메모리 관리가 상대적으로 효율적이다.
-
다양한 연산 지원: 배열은 다양한 연산을 지원한다. 예를 들어, 요소 추가 및 삭제, 검색, 정렬 등 다양한 데이터 조작 작업을 수행할 수 있다.
-
캐시 지역성: 배열의 요소는 메모리에 연속적으로 저장되므로, 캐시 메모리의 지역성을 활용하여 성능을 향상시킬 수 있다.
-
-
단점
-
고정 크기: 배열은 생성 시 크기가 고정되므로 요소를 추가하려면 배열을 확장해야 한다. 크기 조정이 필요한 경우 많은 연산이 필요하며, 배열을 복사해야 할 수도 있다.
-
메모리 낭비: 배열은 크기가 고정되므로 미리 큰 메모리 공간을 할당하면서 사용하지 않는 공간을 낭비할 수 있다.
-
요소 추가 및 삭제의 비효율성: 배열의 중간에 요소를 삽입하거나 삭제할 때, 해당 위치 이후의 모든 요소를 이동해야 한다. 이로 인해 추가 및 삭제 작업이 비효율적일 수 있다.
-
연속된 메모리 요구: 배열은 연속된 메모리 공간에 요소를 저장하므로, 메모리가 연속적이지 않은 경우 배열을 사용하기 어려울 수 있다.
-
정적 타입: 대부분의 배열은 정적 타입(같은 데이터 타입의 요소만 포함)을 가지므로 다양한 데이터 타입을 함께 저장하기 어렵다.
-
2-3. 배열은 언제 사용하는 것이 좋을까?
-
빠른 접근 및 검색이 필요한 경우: 배열은 인덱스를 사용하여 요소에 빠르게 접근할 수 있으므로 검색 작업이 빈번한 경우에 유용하다. 인덱스를 알고 있다면 요소에 대한 직접적인 접근 즉, 무작위 접근(random access)이 가능하며, 이는 O(1) 시간 복잡도로 이루어진다. (데이터 추가와 삭제와 같은 동적인 작업을 많이 하는 경우 배열 대신 연결 리스트를 사용하는 것이 유리할 수 있다.)
-
크기가 고정된 경우: 만약 데이터 집합의 크기가 고정되어 있고 크기 조정이 필요하지 않은 경우에 배열을 사용하는 것이 효율적이다. 크기가 고정된 배열은 메모리 할당과 해제에 드는 오버헤드가 없다.
-
메모리 관리가 중요한 경우: 배열은 요소를 연속된 메모리 공간에 저장하므로, 메모리 관리가 상대적으로 간단하고 효율적이다.
-
정적 타입 데이터: 배열은 보통 동일한 데이터 타입의 요소를 저장하는 데 사용된다. 정적 타입의 데이터를 다룰 때 배열은 효과적이다.
-
캐시 지역성 활용이 가능한 경우: 배열은 요소가 메모리 내에서 연속적으로 저장되므로, 캐시 메모리의 지역성을 활용하여 성능을 향상시킬 수 있다.
-
다양한 연산이 필요한 경우: 배열은 다양한 연산을 지원합니다. 정렬, 필터링, 매핑, 리듀싱 등 다양한 데이터 조작 작업을 수행할 수 있습니다.
2-4. JavaScript로 배열 구현하기 (예제 코드)
// 빈 배열 생성
const myArray = [];
// 배열에 요소 추가
myArray.push(1);
myArray.push(2);
myArray.push(3);
// 배열 내용 출력
console.log("배열 내용:", myArray); // [1, 2, 3]
// 배열 길이 확인
const length = myArray.length;
console.log("배열 길이:", length); // 3
// 특정 인덱스의 요소 접근
const element = myArray[1];
console.log("인덱스 1의 요소:", element); // 2
// 배열 순회 (for...of 루프 사용)
console.log("배열 순회:");
for (const item of myArray) {
console.log(item);
}
// 배열 내 특정 값 찾기
const targetValue = 2;
const index = myArray.indexOf(targetValue);
console.log(`${targetValue}의 인덱스: ${index}`); // 1
// 배열에서 요소 제거
const removedElement = myArray.pop(); // 마지막 요소 제거
console.log("제거된 요소:", removedElement); // 3
console.log("배열 내용 (pop 후):", myArray); // [1, 2]
// 배열 요소 변경
myArray[0] = 0;
console.log("배열 내용 (변경 후):", myArray); // [0, 2]
3. 벡터 (Vector)
- 벡터는 동적으로 요소를 할당할 수 있는 동적 배열(Dynamic Array)이다.
- 배열과 유사하지만 동적으로 크기가 조절되며, 요소를 추가하거나 제거 시 다시 할당할 필요가 없다.
- 컴파일 시점에 개수를 모른다면 벡터를 사용한다. 또한 중복을 허용하고, 순서가 있고, 무작위 접근(random access)이 가능하다.
3-1. 벡터의 시간 복잡도
| 구분 | 접근 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 평균 | O(1) | O(1) | O(n) | O(n) |
| 최악 | O(1) | O(1) | O(n) | O(n) |
- 맨 뒤의 요소를 삽입/삭제할 때에는
O(1)
3-2. 벡터의 장단점
-
장점
-
빠른 랜덤 액세스: 배열의 형태를 가지며, 요소에 빠르게 접근할 수 있다. 인덱스를 사용하여 O(1) 시간에 원하는 요소에 접근할 수 있다.
-
빠른 순차 액세스: 순차적으로 모든 요소에 접근할 때 빠르며, 메모리 상에 연속된 요소로 저장되므로 CPU 캐시의 지역성을 활용할 수 있다.
-
크기 조절 가능: 동적으로 크기를 조절할 수 있으므로, 요소의 개수가 변하는 상황에서 효율적이다. 크기가 가변적이기 때문에 메모리를 효율적으로 관리할 수 있다.
-
-
단점
-
삽입 및 삭제 비효율성: 벡터의 크기를 조절할 때, 일반적으로 요소를 다른 메모리 영역으로 복사해야 하므로, 삽입 또는 삭제 작업이 느릴 수 있다. 요소를 중간에 삽입하거나 삭제하는 경우에는 추가적인 작업이 필요하여 이 때 시간 복잡도가 O(n)이 된다.
-
메모리 오버헤드: 크기가 큰 벡터를 사용할 때는 크기를 조절할 때마다 추가 메모리 할당 및 복사 작업이 발생할 수 있어 메모리 오버헤드가 발생할 수 있다.
-
할당된 메모리 고정: 벡터는 메모리를 미리 할당받아 사용하므로, 처음에 설정된 크기를 초과하여 요소를 추가하려면 배열을 확장해야 한다. 이 때 크기 조절 작업이 발생하며, 이로 인해 성능 저하가 발생할 수 있다.
-
3-3. 벡터는 언제 사용하는 것이 좋을까?
-
요소의 개수가 미리 알려지지 않은 경우: 벡터는 크기를 동적으로 조절할 수 있으므로, 요소의 개수가 미리 알려지지 않거나 계속해서 변할 때 유용하다.
-
빠른 랜덤 엑세스가 필요한 경우: 벡터는 배열처럼 인덱스를 사용하여 요소에 빠르게 접근 가능하므로 특정 위치에 있는 요소를 자주 찾아야 하는 상황에서 유용하다.
-
순차 액세스도 필요한 경우: 요소를 순차적으로 탐색하는 작업에도 벡터는 좋은 성능을 제공한다. 연속된 메모리 위치에 저장되어 있으므로 CPU 캐시를 효율적으로 활용할 수 있다.
-
메모리에 효율적인 동적 배열이 필요한 경우: 벡터는 크기 조절을 관리해주므로 메모리 사용을 효율적으로 관리할 수 있다.
-
같은 데이터 형식의 요소를 다루는 경우: 동일한 데이터 형식의 요소를 다루기에 특히 유용하다. 예를 들어 숫자 배열, 문자열 배열 등의 경우에 활용된다.
-
변경 빈도가 낮은 경우: 요소의 추가 및 삭제가 자주 발생하지 않는 경우 유용하다. 추가 및 삭제 작업이 빈번하게 발생하는 경우에는 다른 자료 구조(예: 연결 리스트)를 고려해야 한다.
3-4. JavaScript로 벡터 구현하기 (예제 코드)
- 일부 프로그래밍 언어(예: C++의
std::vector, Java의ArrayList)에는 Vector를 지원하는 내장 라이브러리나 클래스가 있으며, 이를 사용하여 쉽게 구현할 수 있다. - 하지만 자바스크립트에는 따로 없으며, 일반적으로 내장
배열(Array)을 사용하여 벡터와 비슷한 기능을 구현할 수 있다. 자바스크립트의 배열은 크기를 동적으로 조절할 수 있기 때문이다.
// Vector와 유사한 동작을 수행하는 배열을 생성.
const vector = [];
// 요소 추가 (Append)
vector.push(1);
vector.push(2);
vector.push(3);
// 요소 접근 (Random Access)
const element = vector[1]; // 2
// 요소 삭제
vector.pop(); // 마지막 요소 제거
// 요소 삽입
vector.splice(1, 0, 4); // 인덱스 1에 4를 삽입
// 배열의 내용 출력
console.log(vector); // [1, 4, 2]
// 배열 길이 확인
const length = vector.length; // 34. 스택 (Stack)
- 스택은 가장 마지막으로 들어간 데이터가 가장 첫 번째로 나오는
후입선출(LIFO, Last In First Out)의 성질을 가진 자료 구조이다. - 재귀적인 함수, 알고리즘에 사용되며 웹 브라우저 방문 기록 등에 쓰인다.

4-1. 스택의 시간 복잡도
| 구분 | 접근 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 평균 | O(n) | O(n) | O(1) | O(1) |
| 최악 | O(n) | O(n) | O(1) | O(1) |
4-2. 스택의 장단점
-
장점
-
단순한 구조: 스택은 매우 간단한 자료 구조로, 구현 및 사용이 쉽다. 이해하기 쉽기에 다양한 응용 프로그램에서 사용된다.
-
빠른 접근 및 조작: 데이터를 추가 및 제거 시 일반적으로 상수 시간(O(1))에 수행된다. 이는 스택이 데이터의 양에 상관없이 빠른 속도로 작업할 수 있음을 의미한다.
-
-
단점
-
크기 제한: 스택은 일반적으로 고정된 크기를 가지며, 스택이 가득 찬 경우 더 이상의 요소를 추가할 수 없다.
-
한 방향으로만 조작: 데이터를 한 쪽 방향(단방향)으로만 조작할 수 있다. 즉, 스택은 가장 최근에 추가한 요소만 제거하거나 접근할 수 있다.
-
비효율적인 중간 삽입 및 삭제: 스택은 중간에 있는 요소를 삽입하거나 삭제하는 작업에는 비효율적이다. 중간 요소를 변경하려면 일반적으로 상위 요소들을 모두 제거한 다음 다시 추가해야 한다.
-
4-3. 스택은 언제 사용하는 것이 좋을까?
-
후입선출(LIFO) 작업: 후입선출 순서로 데이터를 저장하고 관리하는 데 사용된다. 가장 최근에 추가된 요소가 가장 먼저 제거되는 경우에 사용된다.
-
재귀 함수 호출: 프로그램에서 함수를 호출하면 호출 스택(Call stack)에 호출된 함수의 정보(Stack frame)가 저장된다. 재귀 함수 호출 또한 스택을 사용하며, 재귀 알고리즘에서 중요한 역할을 한다.
-
역추적(Backtracking) 및 History 관리: 탐색 및 역추적 알고리즘에서 스택을 사용하여 이전 상태를 기록하고 필요한 경우 이전 상태로 돌아갈 수 있도록 도와준다.
- 예시: 경로 찾기, 게임 플레이, 문제 해결 및 결정 트리 탐색과 관련이 있다. 체스 게임에서 가능한 수를 계산하거나, 경로 탐색 알고리즘에서 경로를 역추적할 때, 또한 방문한 웹 페이지의 이력을 추적하고 사용자가 "뒤로 가기" 또는 "앞으로 가기" 버튼을 클릭할 때 이전 페이지로 돌아갈 수 있도록 한다. 이전에 방문한 페이지의 URL이나 상태를 스택에 저장하고, 사용자가 뒤로 가기를 요청하면 스택에서 이전 페이지 정보를 추출하여 브라우저에 표시한다.
-
파서(Parser) 및 컴파일러(Compiler): 파서와 컴파일러에서는 스택을 사용하여 구문 분석(Syntax Parsing) 및 컴파일 작업을 수행한다.
-
임시 데이터 저장: 데이터의 임시 저장이 필요한 경우 스택을 사용하여 일시적으로 데이터를 저장할 수 있다.
-
프로그램의 실행 흐름 제어: 조건문이나 루프에서도 스택을 사용하여 프로그램의 실행 흐름을 제어하는 데 활용할 수 있다.
4-4. JavaScript로 스택 구현하기 (예제 코드)
class Stack {
constructor() {
this.items = []; // 스택 요소를 저장할 배열
}
// 스택에 요소 추가
push(element) {
this.items.push(element);
}
// 스택에서 요소 제거 및 반환
pop() {
if (this.isEmpty()) {
return "스택이 비어 있습니다.";
}
return this.items.pop();
}
// 스택의 가장 위(마지막) 요소 반환
peek() {
if (this.isEmpty()) {
return "스택이 비어 있습니다.";
}
return this.items[this.items.length - 1];
}
// 스택이 비어 있는지 확인
isEmpty() {
return this.items.length === 0;
}
// 스택의 크기 반환
size() {
return this.items.length;
}
// 스택 내용을 문자열로 반환
toString() {
return this.items.toString();
}
}
// 스택 인스턴스 생성
const stack = new Stack();
// 스택에 요소 추가
stack.push(1);
stack.push(2);
stack.push(3);
// 스택 출력
console.log("스택 내용:", stack.toString()); // 출력: "1,2,3"
// 스택에서 요소 제거
console.log("pop 결과:", stack.pop()); // 출력: 3
// 스택의 가장 위(마지막) 요소 확인
console.log("peek 결과:", stack.peek()); // 출력: 2
// 스택 크기 확인
console.log("스택 크기:", stack.size()); // 출력: 2
// 스택이 비어 있는지 확인
console.log("스택이 비어 있는가?", stack.isEmpty()); // 출력: false
5. 큐 (Queue)
큐는 먼저 집어넣은 데이터가 먼저 나오는 선입선출(FIFO, First In, First Out)의 성질을 지닌 자료 구조이다. (후입선출(LIFO)의 성질을 가진 스택과 반대되는 개념이다)

5-1. 큐의 시간 복잡도
| 구분 | 접근 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 평균 | O(n) | O(n) | O(1) | O(1) |
| 최악 | O(n) | O(n) | O(1) | O(1) |
5-2. 큐의 장단점
-
장점
-
순차적 데이터 처리 및 순서 유지에 용이: 큐는 데이터를 선입선출(FIFO) 순서로 처리하므로 순차적으로 데이터를 처리하거나 순서를 유지하는 작업에 유용하다.
-
자료 구조 연산의 일관성과 안정성: 큐는 연산을 안전하게 수행할 수 있도록 도와주며, 삽입과 삭제가 정확한 순서로 이루어진다. 이는 데이터의 일관성을 유지하는 데 도움이 된다.
-
-
단점
-
빠른 데이터 접근이 어려움: 큐는 데이터를 선입선출 순서로 처리하므로, 중간에 있는 데이터에 접근하려면 처음부터 차례대로 데이터를 빼야 한다. 이로 인해 중간 요소에 빠르게 접근하는 데는 비효율적이다.
-
크기 제한: 일부 구현에서 큐의 크기를 제한할 수 있으며, 크기를 초과하려면 추가적인 작업이 필요하다. 이는 큐의 크기를 동적으로 확장하기 어렵게 만들 수 있다.
-
5-3. 큐는 언제 사용하는 것이 좋을까?
-
작업 대기열(Task Queue): 다양한 작업을 처리하는 작업 대기열을 구현할 때 큐를 사용할 수 있다. 프로세스 스케줄링, 스레드 풀 관리 등에서 큐를 활용하여 작업을 순서대로 처리할 수 있다.
-
이벤트 처리(Event Handling): 이벤트는 발생한 순서대로 큐에 추가되고 처리된다. 웹 애플리케이션에서 클릭, 키 입력, 타임아웃 등의 이벤트 처리에 사용할 수 있다.
-
캐시 관리(Cache Management): 캐시에서 오래된 데이터를 제거하고 새로운 데이터를 저장하기 위해 큐를 사용할 수 있다. 가장 오래된 데이터가 먼저 제거되어 캐시의 용량을 유지한다.
-
네트워크 통신(Network Communication): 네트워크에서 도착한 데이터 패킷을 큐에 추가하고 처리하는 데 사용할 수 있다. 데이터 패킷을 순서대로 처리하거나 재전송하는 데 유용하다.
5-4. JavaScript로 큐 구현하기 (예제 코드)
class Queue {
constructor() {
this.items = []; // 큐 요소를 저장할 배열
}
// 큐에 요소 추가 (Enqueue)
enqueue(element) {
this.items.push(element);
}
// 큐에서 요소 제거 및 반환 (Dequeue)
dequeue() {
if (this.isEmpty()) {
return "큐가 비어 있습니다.";
}
return this.items.shift();
}
// 큐의 가장 앞(첫 번째) 요소 반환
front() {
if (this.isEmpty()) {
return "큐가 비어 있습니다.";
}
return this.items[0];
}
// 큐가 비어 있는지 확인
isEmpty() {
return this.items.length === 0;
}
// 큐의 크기 반환
size() {
return this.items.length;
}
// 큐 내용을 문자열로 반환
toString() {
return this.items.toString();
}
}
// 큐 인스턴스 생성
const queue = new Queue();
// 큐에 요소 추가
queue.enqueue(1);
queue.enqueue(2);
queue.enqueue(3);
// 큐 출력
console.log("큐 내용:", queue.toString()); // 출력: "1,2,3"
// 큐에서 요소 제거
console.log("dequeue 결과:", queue.dequeue()); // 출력: 1
// 큐의 가장 앞(첫 번째) 요소 확인
console.log("front 결과:", queue.front()); // 출력: 2
// 큐 크기 확인
console.log("큐 크기:", queue.size()); // 출력: 2
// 큐가 비어 있는지 확인
console.log("큐가 비어 있는가?", queue.isEmpty()); // 출력: false
Reference.
