Introduction
문제 정의: 이전의 접근 방식
embedding 학습을 위해 classification과 verification을 이상적인 전략으로 제안했다.
1) 특징을 학습하기 위한 하나의 네트워크
2) 이 특징을 분류하고 특징들이 얼마나 유사한지를 평가하는 다른 네트워크
이런 구조였다.
문제는 final embedding을 생성하기 위한 복잡성과 비용이다.
제안
변형된 triplet loss가 최종 단계에서 좋은 결과를 낼 수 있고, 추가적인 학습 단계를 불필요하게 만들 수 있다고 제안했다.
Two main contributions
1) Batch Hard loss라는 변형된 Triplet loss에 대한 평가와 이것의 soft margin version
2) 사전 학습된 가중치 사용이나 처음부터 학습한 특별한 층이나 추가적인 네트워크 없는 일반적인 CNN의 Triplet loss는 표준 벤치마크 datasets에서 최첨단 결과를 얻을 수 있다는 것을 증명함
문제점
데이터셋이 커질수록 triplet의 가능한 수가 기하급수적으로 커져서, 긴 training을 비실용적으로 만든다.(n^3의 차수로 증가함) => 그래서 실제로 트리플릿의 계산이 사용되지 않음
[classical implementation]
B triplets 세트가 선택되면 anchor B개, positive B개, negative B개로 총 3B의 batch로 stack되고 3B 임베딩이 계산된다. 그러면 결과적으로 B개의 항목이 loss에 기여한다. 근데 3B 이미지들에서 6B^2-4B개의 가능한 조합들이 나오는데 이 중에 B개만 사용하는건 낭비이다.
해결법
세 가지의 다른 loss를 제안했다.
1. Batch Hard
P개의 클래스들로 랜덤하게 샘플링하고, 각 클래스에서 K개의 이미지를 무작위로 샘플링해서 총 PK개의 이미지의 배치를 낸다.
각 배치 내의 샘플 a에 대해서 loss를 계산하기 위해 가장 어려운 positive와 가장 어려운 negative 샘플을 고를 수 있다.
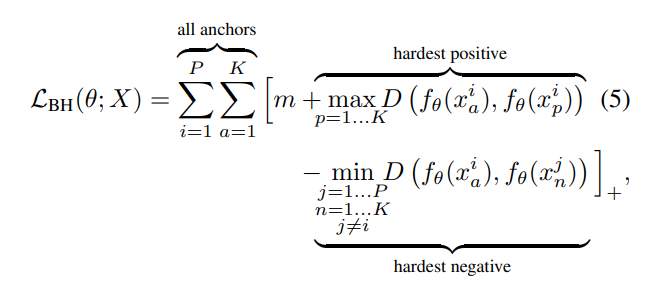
- 각 sample anchor 'a'에 대해서 같은 클래스의 다른 모든 sample들 중 max 거리를 가지는 positive sample을 찾는다.
- 비슷하게 다른 class에서 다른 모든 sample들을 탐색해서, sample 'a'와의 거리가 min인 negative sample을 찾는다.
- margin은 positive sample(같은 class)과 negative sample(다른 class)가 얼마나 떨어져 있어야 하는지를 의미한다.
이걸 PK개의 이미지에 대해 반복해서, 전체 dataset에 걸처 semi hard triplets으로 간주될 수 있는 총 PK개의 triplet을 training에 사용하게 된다.
2. Batch All
Batch Hard를 확장해서 PK개의 이미지 batch에서 가능한 모든 triplet 조합을 생각한 것이다.
PK(PK-K)(K-1)개의 triplet을 이용한다.
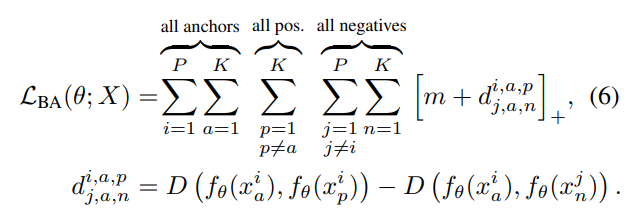
anchor인 sample 'a'에 대해서, 모든 positive와 negative에 대한 거리를 계산한다.
이걸 모든 sample에 대해 반복한다.
그리고 PK개의 이미지를 이 과정을 모두 반복한다.
3. Lifted Embedding Loss
Batch All과 유사한데, 거리의 합에 log를 취한다.
Lifted structured loss를 기반으로 한다.
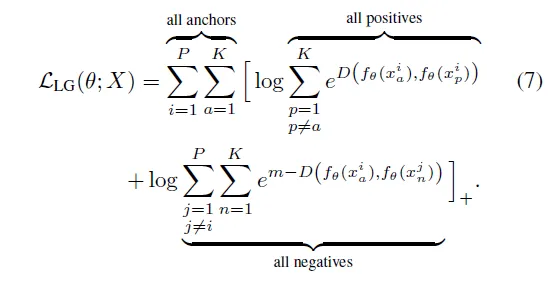
Distance Measure
여기서 사용되는 거리인 metric D는 제곱된 유클리드 거리가 아니라 실제 유클리드 거리 training metric이다.
(squared Euclidean distance가 train 중에 더 쉽게 붕괴되고, actual Euclidean distance는 안정되기 때문)
Soft-margin
hinge 함수인
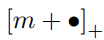 의 역할은 "already correct" triplets을 피하기 위한거다.
의 역할은 "already correct" triplets을 피하기 위한거다.
하지만 person ReID에서는 동일한 클래스의 sample을 같이 가져오는게 좋을 수 있다.
Softplus 함수는 hinge 함수와 비슷하게 동작하지만 급격한 차단(hard cut-off)대신 기하급수적으로 감소한다. (soft-margin formulation이라 한다.)
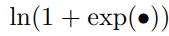
Experiments
3가지의 main experiemnts를 했다.
1) 다양한 hyper-parameters를 포함한 triplet loss의 다ㅇ른 변형들을 평가해서 person ReID를 위한 최적의 학습법을 알아내고, 이것을 MARS training set을 가지고 평가했다.
2) triplet loss의 여러가지 변형의 성능을 평가했다.
사전 학습된 네트워크와 처음부터 학습한 네트워크를 기반으로 CUHK03과 Market-1501, MARS test sets에서 최적의 결과를 보여준다.
3) 실제 사용 사례와 관련해서 model을 처음부터 훈련하는 것의 장점에 대해 말한다.
사용 datasets
1) Market-1501
2) MARS
Model
1) TriNet(Pretrained)
ResNet-50 architecture와 Heetal에 의해 제공된 가중치를 사용했다.
마지막 layer와 두개의 fully connected layer를 추가했다.
처음은 배치 정규화와 ReLU를 사용하고, 두번째는 최종 임베딩 차원을 사용했다.
2) LuNet (Trained from Scratch)
ResNet-v2 스타일을 따르지만 leaky ReLU 비선형성을 사용하고, strided convolutions 대신 stride 2의 3x3 max pooling을 여러 번 사용한다. 최종 feature-maps의 average pooling 대신 채널 축소를 위한 final res-block을 사용한다.
이 네트워크는 pretrained model보다 훨씬 가볍다.
Result
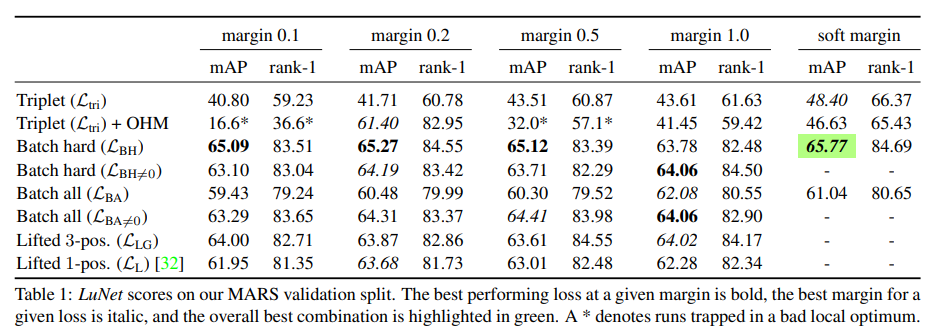
LuNet 스코어(MARS validationsplit)
가장 좋은 score는 the soft-margin variation of the batch hard loss에서 나타났다.
이 방법은 person ReID에서는 좋은 성적을 내지만 다른 domain에서는 그렇지 않을 수도 있다.
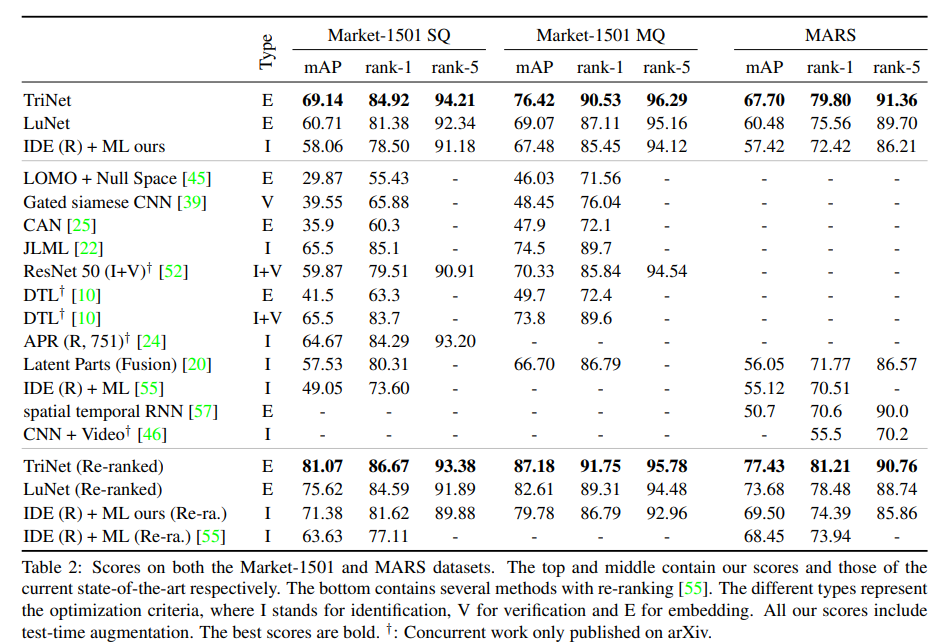
실제 성능 향상이 다른 design의 선택이 아니라 triplet loss에 의해서 얻어진 것을 보여주기 위해, Indentification(I)와 Verification(V)를 포함한 classification loss로 ResNet-50 model을 train했는데 성능이 낮았다.
- Identification model: 사람 ID를 분류하도록 훈련된 식별 모델
- Verification model: 이미지 쌍이 동일 인물을 나타내는지를 학습하는 검증 모델
To Pretrain or not to Pretrain?
Pretrained 네트워크는 deep learning의 새로운 발전을 시도하거나 네트워크에 특정 수행에 맞춘 변경을 적용하는 유연성을 감소시킨다. (LuNet model으로 처음부터 학습시켰는데 좋은 점수를 얻을 수 있음을 볼 수 있다.)
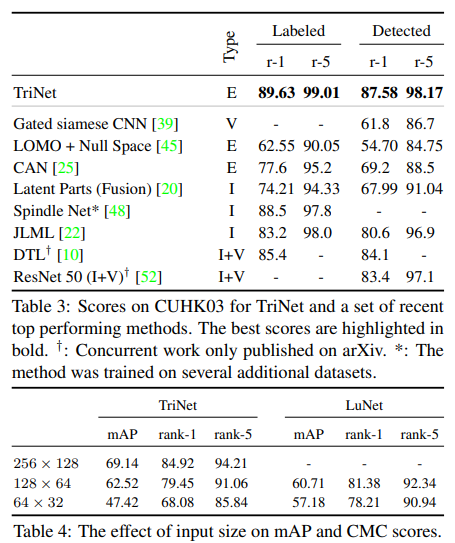
Pretrained model의 한계
사전 학습된 네트워크는 보통 정확성에 중점을 두고 설계되었다. 따라서 메모리 사용량이나 실행 시간을 최적화하지 않았다.
사전 학습된 모델을 새로운 과제에 맞게 조정하려면 image 크기를 모델이 학습된 크기로 맞춰야한다. (더 작은 이미지를 이용하면 성능이 떨어진다.)
처음부터 학습한 LuNet은 작은 이미지에서도 성능의 큰 저하 없이 작동한다.
Conclusion
- 기존의 일반적인 생각들과 달리, triplet loss가 person ReID에 좋은 tool임을 보였다.
- 거의 추가적 cost없이 offline hard negative mining이 필요하지 않은 변형을 제안했다.
