Detectron2를 이용한 Scene Text Detection

서론
1. 개발 배경 및 목표
컴퓨터 비전의 기술이 발전함에 따라 다양한 분야들이 늘어나고 있다. 주목받고 있는 분야 중 하나가 Scene Text Detection이다. Scene Text Detection은 복잡한 환경에서 글자를 감지하고 추출하는 것이다. 본 게시글에서는 Scene Text Detection을 수행하는 모델을 개발한다. 기본 모델은 Detectron2 Framework에서 제공하고 있는 Instance Segmentation의 Mask R-CNN을 사용하였고, 이를 기반으로 Text와 각 문자를 인식하는 모델을 개발한다.
2. 관련 지식
2-1. Detectron2
Detectron2는 FAIR(Facebook Artificial Intelligence Research)에서 제작한 PyTorch 기반 Object Detection, Semantic Segmentation을 위한 Training 플랫폼이다.
Detectron2를 쓰는 이유는 위의 사진을 통해 설명할 수 있다. 왼쪽 그림을 확인해보면 블록을 처음부터 쌓아 완성하는 작업은 굉장히 어렵다. 우리는 오른쪽 그림처럼, 이미 완성된 블록을 이용해 개발하면 편하게 완성할 수 있다. 블록은 하나의 Layer로 생각하면 된다.
Detectron2를 이용해 학습을 진행하면 우리가 직접 모델이 돌아갈 수 있는 환경을 구현하지 않고, 기본적으로 구현되어 있는 엔진을 바탕으로 진행한다. 이에 따라 연구자들은 모델이 돌아갈 수 있는 환경에 초점을 맞추는 것보다 모델 개발 자체에만 집중할 수 있다.
따라서 본 프로젝트에서는 Detectron2를 사용하여 학습을 진행한다.
2-2. Mask R-CNN
Mask R-CNN은 Instance Segmentation을 진행하기 위한 모델이다. 기존의 Faster R-CNN에서 조금 더 구조가 추가되었으며, 아래의 그림에서 Mask R-CNN의 구조를 확인할 수 있다.
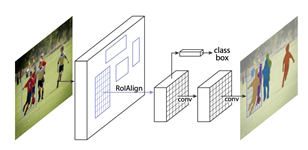
Mask R-CNN은 Faster R-CNN 구조에 간단하게 적은 FCN을 추가하여 다양한 컴퓨터 비전 분야를 개발할 수 있게끔 하였다. 그리고 비교적 연구 속도가 느린 Instance Segmentation을 중점으로 진행도어 본 연구의 질이 올라갔음을 확인할 수 있다.
Mask R-CNN에 대해 조금 더 자세히 알고 싶으면 Mask R-CNN 논문을 참고하면 된다.
개발 시스템
1. 최종 목표
Detectron2를 기반으로 Scene Text Detection을 진행하는 모델을 구현한다. 글자와 알파벳, 숫자를 최대한 많이 검출하는 것이 최종 목표이다.
2. 세부 목표
2-1. Dataset 수집
우선 Scene Text를 진행할 Dataset을 수집한다. 본 과제에서는 단순히 단어뿐만 아니라 알파벳도 검출할 예정이므로, Character형 Ground Truth가 존재하는 Dataset을 구해야한다. 이 중 Character형 Ground Truth가 존재하는 Dataset은 ICDAR 2013 Training Dataset과 Synth Text Dataset 총 두 가지였다. 본 프로젝트에서는, 이 두 가지 Dataset을 이용해 학습과 평가를 진행하였다.
1. ICDAR 2013 Training Dataset
ICDAR 2013은 Robust Reading Competition에서 제공되고 있으며, 본 데이터는 Text, Character 형식의 Annotation을 제공하고있다. Dataset을 다운 받기 위해서는 본 링크를 클릭하면 된다.

위의 그림을 살펴보면 왼쪽 그림은 Text, 오른쪽 그림은 Character형 정보임을 확인할 수 있다. Dataset의 개수는 Training이 총 229개이다. Test는 Character형 정보를 제공하지 않으므로, 사용하지 않았다.
2. Synth Text Dataset
Synth Text는 일반 이미지에 Text를 합성한 Dataset으로, 약 800만개의 합성 단어 Instance가 존재하는 858,750개의 이미지로 구성된다. 각 Text Instance에는 Text의 문자열, 단어, 문자의 Annotation이 존재한다. 본 Dataset을 다운받기 위해서는 링크를 클릭하면 된다.

위의 그림을 확인해보면 Text는 직사각형의 Bounding Box로 제공되지만, Character형은 문자의 끝점 4개를 이어서 제작하였다. 그래서 COCO Dataset에 부합하지 않아, Annotation을 제작할 때 약간의 수정을 거쳐 사용하였다.
3. 최종 Dataset의 개수
프로젝트 초반에는 Synth Text 전체를 학습시켰지만, Annotation을 읽는 과정 중 메모리가 부족해 프로세스가 Killed 되었다. 그리고 전체 학습을 진행할 때 1 Epoch 당 약 20시간정도 소요되어 시간이 부족하여 Dataset을 30,000개 선정한 후 학습을 진행하였다.
| Synth Text | ICDAR 2013 | Total | |
|---|---|---|---|
| Training | 30,000 | 0 | 30,000 |
| Test | 207 | 229 | 436 |
학습에는 Synth Text만 사용하였으며, 평가에는 Synth Text와 ICDAR 2013 각각 진행해보았다.
2-2. COCO Annotation
Detectron2에서 학습 및 평가를 진행하기 위해 COCO 형식의 Annotation이 필요하다. 위의 Dataset의 각 Text 정보를 바탕으로 COCO Annotation JSON 파일을 제작하고 생성하였다.

Annotation의 형식은 위의 그림에서 확인할 수 있다. 우선 images의 정보는 학습을 진행할 이미지의 이름, 크기, id가 존재해야 한다. 그리고 categories에는 학습을 진행할 Label(Class)들이 존재한다. 63개의 Label이 존재하며 각 알파벳의 소문자와 대문자, 그리고 숫자와 Text가 존재한다. 마지막으로 annotations에는 각 해당하는 데이터의 영역과 Bounding Box, 카테고리의 종류와 Segmentation과 같은 정보가 존재해야 한다.
앞서 언급했듯이, Synth Text의 Character형 정보에는 Bounding Box가 아닌 문자 기준 끝점 4개의 정보가 저장되어 있다. 이에 따라 Area가 음수값이 나오는 문제가 존재해 pycocotools를 사용해 해당 문자의 Area와 Bounding Box를 구했다. 그리고 끝점 4개의 정보는 Segmentation의 좌표로 지정하였다.
def area(rleObjs): # annotation에 들어갈 area
if type(rleObjs) == list:
return _mask.area(rleObjs).tolist()
else:
return _mask.area([rleObjs])[0].tolist()
def toBbox(rleObjs): # annotation에 들어갈 bbox
if type(rleObjs) == list:
return _mask.toBbox(rleObjs).tolist()
else:
return _mask.toBbox([rleObjs])[0].tolist()Area와 Bounding Box를 생성하는 관련 코드는 위에서 확인할 수 있다.
2-3. Detectron2 준비
훈련을 진행하기 위해 Detectron2 Framework를 Install하고 코드를 구현하였다.
우선 Detectron2에 필요한 라이브러리를 먼저 Install하였다.
pip install pyyaml==5.1기본적으로 opencv와 PyTorch는 깔려있으므로 따로 Install하지 않았다. 후에 Detectron2를 Install하였다.
pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html본인의 컴퓨터는 PyTorch Version이 1.7이므로, 이에 맞게 Install해주었다. PyTorch Version에 따른 Detectron2 Version은 Detectron2 Document에 나와 있으므로 참고하면 된다.
실험
1. 실험 시스템 환경
| Version | |
|---|---|
| OS | Ubuntu 18.04 LTS |
| CUDA | 11.0 |
| GPU | GTX 3090 |
| Python | 3.6 |
| PyTorch | 1.7.1+cu110 |
| Torchvision | 0.8.2+cu110 |
| Detectron2 | 0.4 |
훈련 및 평가를 진행한 실험 환경은 위의 표를 통해 확인할 수 있다.
2. 훈련 및 결과
많은 시행착오를 겪었지만, 최종적으로 나온 결과만 기재하였다. 앞서 설명했듯이, 모델은 Mask R-CNN을 기반으로 학습을 진행하였다. 우선 Synth Text 20,000개 데이터를 우선으로 학습을 진행하였다. 50 Epoch(500,000 Iteration)에 학습률은 0.00025로 진행하였고 총 학습 시간은 약 24시간이었다. Text Instance의 개수는 약 18만개, 전체 Instance는 88만개였다.
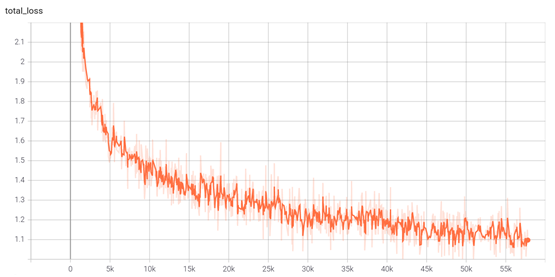
위의 그림에서 확인할 수 있듯이 전체적인 Loss는 0.9정도까지 하락하였다.

위의 결과를 확인해보면 Text는 모두 검출하였으며, 알파벳 또한 전체적으로 잘 검출함을 확인할 수 있다. 조금 아쉬웠던 점은 표지판 좌측상단에 존재하는 화살표를 글자로 인식했다는 점이다.
위의결과를 바탕으로 데이터를 10,000개 추가하여 총 30,000개로 학습을 진행하였다. 학습은 위의 본 모델에 이어 50 Epoch(750,000 Iteration)와 학습률은 위와 동일하게 0.00025로 지정하여 진행하였다. 약 35시간동안 학습이 이루어졌으며, Text Instance는 약 27만개, 전체 Instance는 130만개임을 확인할 수 있다.
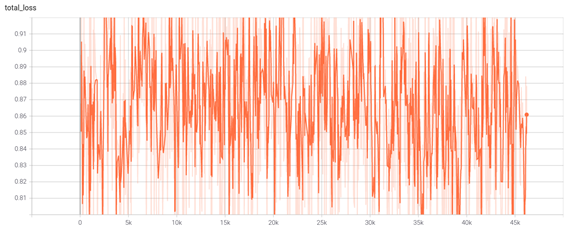
Loss는 이전 모델에 이어서 학습을 진행해 0.8과 0.6 사이를 반복하며 진동하였다. 데이터를 추가하면 Loss가 하락될 것을 예상하였는데, 많은 하락세를 보이지 않아 조금 아쉬웠다.

위의 사진을 확인해보면 이전의 모델보다 글자를 조금 더 명확히 추출하는 것을 확인할 수 있다. 하지만 성능이 아주 많이 개선되지 않았다.

다음 평가는 Synth Text에서 학습시키지 않은 데이터를 통해 진행해보았다. ICDAR 2013보다는 성능이 조금 더 높았으며, 위의 그림과 같이 글자를 잘 검출함을 확인할 수 있다.
결론
본 프로젝트에서는 FAIR에서 개발한 Detectron2를 이용해 Scene Text Detection 모델을 개발하였다. 모델의 Label로는 단어와 알파벳, 숫자 총 63개이며 Dataset으로는 Synth Text, ICDAR 2013을 사용하였다. 성능이 그렇게 높지 않아, 아쉬운 점이 많은 프로젝트였지만 기회가 된다면 성능을 향상하고 싶다.
부록
관련 코드
본 프로젝트 관련 코드는 Github에서 확인할 수 있다.
참고 문헌
(1) Detectron2 리뷰
(2) pycocotools Github
