DBMS(MARIA DB==MySQL)
Tool > HeidiSQL / 워크벤치 등등 완전 많음
p.10 : 관계형 데이터베이스
R-DB(고인물 DB, 구조 위주)
NoSQL(읽기 위주)
MongoDB(일반적), Cansandra(페이스북)
SQL = Structured Query Language
SQL문
스키마 : 타입을 어기면 안 됨!!
DCL(제어어), DDL(정의어) 등등...
CRUD -- 명령어(=DML / 조작어)
C - 쓰기 - Insert
R - 읽기 - Select(제일 어렵다)
U - 수정 - Update
D - 삭제 - Delete
0415/
객체 이름을 한글로 사용하지 마시오.
PK : NOT NULL, UNIQUE(중복된 값을 넣을 수 없음), INDEX
<테이블 생성>
CREATE TABLE productTBL(
productName CHAR(4) PRIMARY KEY,
cost INT NOT NULL,producttbl
makeDATE DATE,
company CHAR(5),
amount INT NOT null
);
--p.56 참고
CREATE TABLE memberTBL(
memberID CHAR(8) PRIMARY KEY, /PK 중요/
memberName CHAR(5) NOT NULL,/값 무시 불가/
memberAddress CHAR(20)
);
--varchar(8) 넣는 만큼만 사용 가능 <-> char(8) 8자리를 무조건 차지, 속도 빠름

SELECT*FROM t_exam;
UPDATE t_exam
SET age=35
WHERE i_exam=4;
DELETE FROM t_exam
WHERE i_exam=3;
CREATE TABLE t_exam(
i_exam INT PRIMARY KEY,
title VARCHAR(100),
jumin CHAR(13),
age INT(3) NOT NULL
);
DROP TABLE t_exam;
CREATE DATABASE java;
INSERT INTO t_exam
(I_EXAM, TITLE, JUMIN, AGE)
VALUES
(1,'ㅎㅇ','960131',25),
(2,'ㅇㄴ','960130',25);
INSERT INTO t_exam
(TITLE,i_exam,jUMIN, AGE)
VALUES
('hi',3,'961131',25),
('hey',4,'964130',25);
주석 다는 방법:
-- 주석
#주석
/주석/
SELECT*FROM t_exam;
CREATE TABLE indexTBL(
FIRST_name VARCHAR(14),
last_name VARCHAR(16),
hire_date DATE
);
INSERT INTO indextbl
(first_name,last_name,hire_date)
SELECT first_name, last_name, hire_date
FROM employees.employees
LIMIT 1000;
explain SELECT*FROM indextbl
WHERE first_name='Mary';
CREATE INDEX idx_indextbl_firstname
ON indextbl(first_name);
-- 169~171페이지 ch6
SELECT * FROM membertbl;
INSERT INTO membertbl
(memberID, memberName,memberAddress)
VALUES
('Dang','당탕이','경기 부천시 중'),
('Jiyeong','졍쓰','대구시 수성구'),
('Jieun','지으니','경상북도 영천시'),
('Suan','블레어','경상북도 창원시'),
('Jun','준블디','대구시 중구');
INSERT INTO producttbl
(productName, cost, MAKEDATE, company, amount)
VALUES
('냉장고',20,'2019-02-01','삼성', 19),
('세탁기',10,'2018-09-01','LG', 18),
('컴퓨터',5,'2017-01-01','애플', 17);
SELECT*FROM producttbl;
-- SELECT 컬럼명 FROM 테이블명
SELECT amount, cost, company
FROM producttbl;
SELECT*
FROM producttbl
WHERE company='LG';
SELECT*
FROM membertbl
WHERE memberName = '지으니';
SELECT*FROM producttbl
WHERE cost >= 10 or company ='lg';
SELECT
emp_no,emp_no AS 'eno'
FROM titles AS A;
SELECT*
FROM titles
WHERE emp_no>=10600
AND title='Staff';
SELECT*
FROM titles
WHERE emp_no between 10500
AND 20000;
SELECT*
FROM titles
WHERE title='Engineer' OR title='Staff';
SELECT*
FROM titles
WHERE title IN('Engineer','Staff','Senior Staff');
SELECT*FROM employees
WHERE first_name LIKE'G%'; -- g가 포함된 이름을 찾아줌
SELECT*FROM employees
WHERE last_name LIKE'%M';
SELECT*FROM employees
WHERE first_name LIKE'%MA%'; -- 양쪽다
SELECT*FROM employees
WHERE first_name LIKE'_MA%'; -- ma 앞에 한 글자만 있는 걸 호출함
-- 스칼라 값
SELECT*FROM employees
WHERE gender= (SELECT gender FROM employees WHERE emp_no=10066);
SELECT 'm' AS gender;
-- 정렬
SELECT*FROM salaries
ORDER BY salary ASC; -- asc는 오름차순 키워드 / desc 내림차순
SELECT*FROM salaries
ORDER BY emp_no, salary DESC;
SELECT*FROM dept_emp
ORDER BY dept_no DESC,emp_no; -- asc 꼭 안 적어줘도 된다
SELECT distinct dept_no FROM dept_emp;
SELECT emp_no, dept_no FROM dept_emp; -- 중복이 일어나지 않아서 결과가 같음
UPDATE salaries
SET salary = NULL
WHERE emp_no =17169
AND from_date = '1990-11-07';
SELECT DISTINCT salary FROM salaries
ORDER by salary;
SELECT*FROM salaries
ORDER BY salary
LIMIT 5; -- limit는 select문의 제일 마지막에 줘야 한다.
SELECT*FROM dept_emp
ORDER BY emp_no
LIMIT 10,50;
-- create, alter, drop
DROP TABLE t_exam;
SELECT DISTINCT
컬럼명|*
FROM 테이블명
WHERE 조건식(무한대)
GROUP BY 컬럼명(여러 컬럼명도 줄 수 있음)
HAVING 그룹 바이의 조건식
ORDER BY 레코드의 순서 조정
LIMIT 레코드 수 조정
-- ALL|DISTINCT|DISTINCTROW
-- all 기본, distinct 중복 제거
SELECT 열 이름
FROM 테이블 이름
WHERE 조건
/*USE employees;
SELECTFROM titles;/
SHOW DATABASES;
USE employees;
SHOW TABLES;
SHOW TABLE STATUS;
-- MyISAM 트랜직션 사용할 수 없다...? 더 빠르다...!
SELECT COUNT(emp_no)FROM salaries;
SELECT max(salary)FROM salaries;
SELECT min(salary)FROM salaries;
SELECT sum(salary)FROM salaries;
SELECT (SUM(salary)/COUNT(salary)) AS avg_salary
FROM salaries;
SELECT AVG(salary) AS avg_salary
FROM salaries;
SELECT AVG(salary) FROM salaries;
SELECT emp_no, MAX(salary) , MIN(salary), SUM(salary), COUNT(salary)
FROM salaries
GROUP BY emp_no
ORDER BY AVG(salary) DESC;
SELECT*FROM salaries;
SELECT emp_no, COUNT(salary), AVG(salary) AS avg_salary
FROM salaries
GROUP BY emp_no
ORDER BY count(salary) DESC, avg(salary) DESC;
SELECT b.first_name, b.last_name, a.emp_no, COUNT(salary), AVG(salary) AS avg_salary
FROM salaries a
LEFT JOIN employees b
ON a.emp_no=b.emp_no
GROUP BY a.emp_no
HAVING COUNT(salary)=10
ORDER BY COUNT(a.salary) DESC, AVG(a.salary) DESC;
SELECT emp_no,AVG(salary)
FROM salaries
GROUP BY emp_no
HAVING AVG(salary)>=90000
ORDER BY AVG(salary);
SELECT*FROM titles;
SELECT title, COUNT(title)
FROM titles
GROUP BY title
ORDER BY count(title) DESC
LIMIT 1;
SELECT*
FROM employees
WHERE gender='F'
AND first_name LIKE'S%'
AND hire_date>='1990-01-01';
0416
select 컬럼명
from 테이블명
join 테이블 조인
where 조건식(레코드 수 관련) (and, or)
group by~~별(통계 낼 때 사용)
having group by 의 조건식(and, or)
order by 뽑아낸 레코드의 순서
limit 제한 수(한 개 아니면 두 개 올 수 있음)
ex. limit 10(처음부터~10)
limit(10,20) - 10번째부터 20개
use 데이터베이스명;
select 1+1 as sum; ( as를 주면서 display시 일시적으로 sum으로 바꿔줌.)
from titles as a(as 있어도 되고 없어도 된다)
as를 where에서 사용할 수 없음. where 절에서는 원래 컬럼명을 사용해주어야 한다.
SELECT*FROM titles
WHERE title !='staff';
SELECT*FROM salaries
WHERE salary BETWEEN 70000 AND 80000; -- 결과가 7 이상 8이하로 나옴
like문은 문장들과 관련 있음.
=은 완벽히 같아야 하므로 like와 %를 같이 쓰면 된다.
selectfrom employees
where first_name like 'G%'(G로 시작하는 사람) '%G'(G로 끝나는 사람) 혹은 '%en%'이 포함된 사람 찾기 속도가 느리다
'_en%' en앞에 한 자리가 있는 경우 '__en%' en 앞에 두 자리가 있는 경우
SELECT*FROM titles
WHERE title='staff' -- 한 칼럼은 하나만 나올 수 있으므로 답이 안 나온다
or title='engineer';
-- 이걸 더 쉽게 쓰는 방법
SELECT*FROM titles
WHERE title IN ('staff','engineer');
where절과 in에 대해 알아보기
SELECT * FROM employees
WHERE gender='f';
SELECT gender FROM employees
WHERE emp_no=10110;
-- 서브 쿼리
SELECT * FROM employees
WHERE gender IN (
SELECT gender FROM employees
WHERE emp_no=10110);
SELECT * FROM employees
WHERE title IN ('Senior Staff','Staff');
SELECT*FROM titles
WHERE title IN(
select title from titles
where emp_no=10007); -- 여기서 = 사용 시 에러 뜬다
중복 제거(select distinct)와 중복 값 찾기
SELECT*FROM salaries
ORDER BY emp_no DESC, salary asc;
SELECT DISTINCT title FROM titles;
SELECT emp_no, title
FROM titles
GROUP by emp_no, title
HAVING COUNT(emp_no)>1;
SELECT*FROM titles
WHERE emp_no = 110386
AND title='technique leader'; -- 중복된 값을 보여줌
SELECT*FROM dept_emp
ORDER BY emp_no DESC
LIMIT 3; -- LIMIT한 값은 처음에서 부터 3개까지
-- DML : INSERT, SELECT, UPDATE, DELETE
SELECT * FROM employees
WHERE gender='f' AND
first_name LIKE 'S%'AND
hire_date >= '1990-01-01';
-- 현민이가 푼 문제
SELECT title FROM titles
GROUP BY title
HAVING COUNT(title)=(
SELECT MAX(A.cnt) FROM(SELECT COUNT(title) AS cnt FROM titles
GROUP BY title)A
);
> -- insert문
SELECT*FROM membertbl;
INSERT INTO membertbl
(memberID, memberName, memberAddress )
VALUES
('Kang','강성헌','대구 달성구 용산동');
> -- 수정(UPDATE 문)
SELECT*FROM testtbl2;
update testtbl2
set userName='지영', age=26
WHERE id=3; -- id는 pk라 한 줄밖에 선택 못 함
-- 웬만하면 다 pk값 들어감
-- where나 from절 앞에 , 가 있으면 안 된다!
CREATE TABLE testTBL2(
id INT AUTO_INCREMENT, -- primary key는 한 군데에만 주자
userName CHAR(3),
age INT,
PRIMARY KEY(id)
);
-- primary key에만 auto_increment을 줄 수 있다
INSERT INTO testTBL2
(username, age)
VALUES
(NULL,'지민',25),
(NULL,'유나',22),
(NULL,'유경',21);
INSERT INTO testTBL2
(username, age)
SELECT userName, age
FROM testTBL2;
SELECT userName, age
FROM testTBL2;
SELECT age FROM testtbl2;
-- 삭제(delete문)
delete from 테이블명
where 조건식
오라클, mySQL에서 다 먹힘
DELETE FROM testtbl2
WHERE id = 10;
DELETE FROM testtbl2;
TRUNCATE testtbl4; -- 이것도 삭제하는 방법! 속도는 더 빠르다
-- 복사하기
-- 스키마는 복사되지 않는다
CREATE TABLE testtbl3
AS
SELECT*FROM testtbl2;
CREATE TABLE testtbl4 (SELECT*FROM testtbl2);
-- ignore, 시간 찍기
INSERT ignore INTO testTBL2
(id,userName, age) VALUES (20, '유나',22);
INSERT INTO testTBL2
(id, userName, age) VALUES (25, '유경',21);
DROP TABLE if EXISTS testtbl2;
SELECT NOW();
SELECT CAST('2020-10-19 12:35:29'AS DATET0) AS d_TIME;
SELECT CAST('2020-10-19 12:35:29'AS DATETIME) AS d_dateTIME;
SELECT DATE_FORMAT(NOW(),'%m-%y-/%d/%h:%i:%s');
SELECT date_format (NOW(), %Y년 &d월 %일%H:%I:%S;);
-- %는 ㅡ
SELECT CAST('10' AS INT)+10, CONCAT('10')+10;
-- cast는 형변화 함수
-- concat은 문자열producttbl
SELECT CAST('10'AS INT),'a10'+'10',
concat('10','10','10'),'aaa'+'bbb';
-- case 문
SELECT emp_no, gender
,if(gender='m','남성','여성') AS GENDER2
,case when gender = 'M'
then '남성'
ELSE '여성'
END AS gender3
FROM employees;
SELECT salary, ifnull(salary,'널'), NULLIF(salary, 77057)
FROM salaries
WHERE salary IS NULL
OR emp_no=17170;
SELECT
case when,
case 컬럼 when ;
SELECT
case 10
when 1 then '일'
when 5 then '오'
when 10 then '십'
ELSE '?'
END AS c_case;
미션)
SELECT*FROM producttbl;


SELECT*,
case company
when '대우' then '탱크대우'
when 'LG' then '사랑해요 LG'
when '삼성' then '또 하나의 가족'
ELSE '바보ㅎ'
END
FROM producttbl;

결과>

CONCAT : () 안의 문자열을 다 더 해준다

결과>

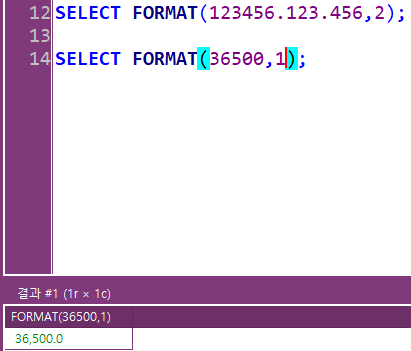
숫자 찍기:
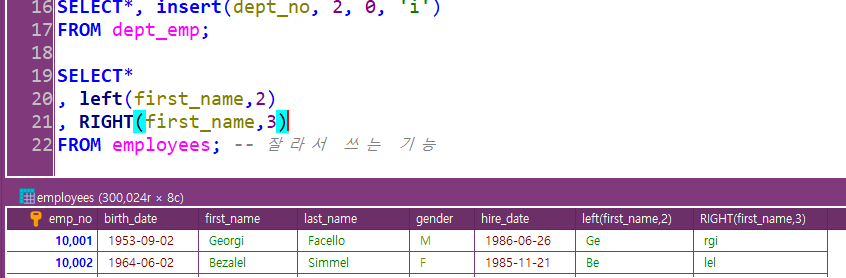
left, right로 잘라내기:
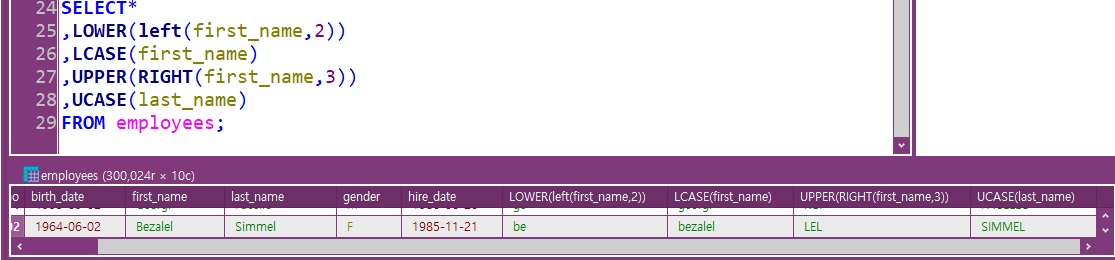
대강 이런 기능이 있다 :
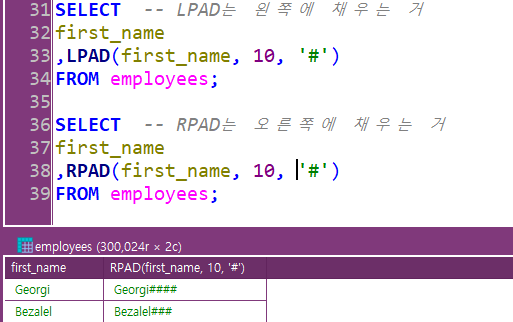
LPAD와 RPAD :
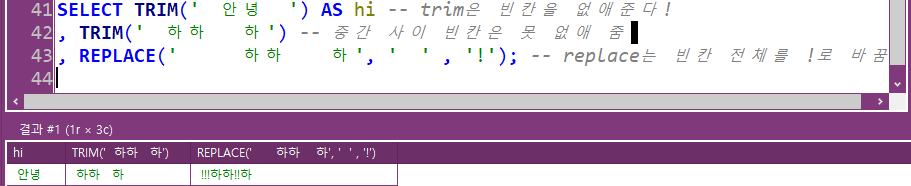
빈칸 없애주는 trim, replace :
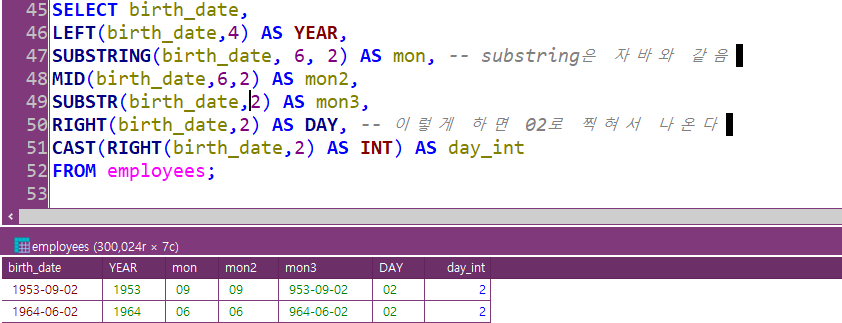
substring, 숫자 하나만 불러오기:
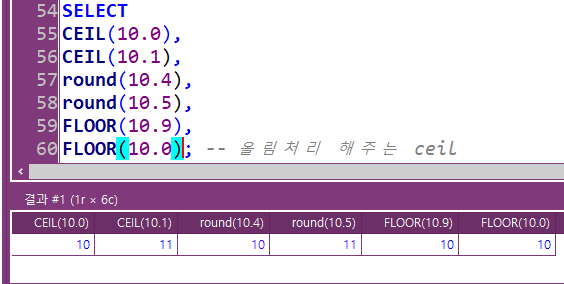
ceil, round, floor: