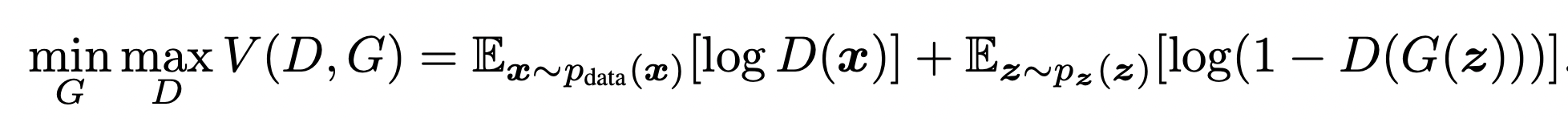
Generative Adversarial Network

GAN(생성적 적대 신경망)은 2014년에 처음 등장한 신경망 모델입니다.
진짜인지 판별하는 Discriminator와 가짜를 생성하는 Generator가 서로 속고 속이는 과정에서 학습하는 구조를 갖고 있습니다.
기존의 신경망 모델이 어떤 형태로든 특정 데이터를 입력으로 받고 그 데이터에 대한 분석 결과를 내놓는 형태였다면,
GAN은 아무것도 없는 무(無)의 상태에서 새로운 무언가를 만들고자 하는 시도였다고 볼 수 있겠습니다.
(정확하게는 아무런 의미가 없는 노이즈를, 특정한 의미를 갖는 이미지로 변환하는 모델입니다.)
Structure
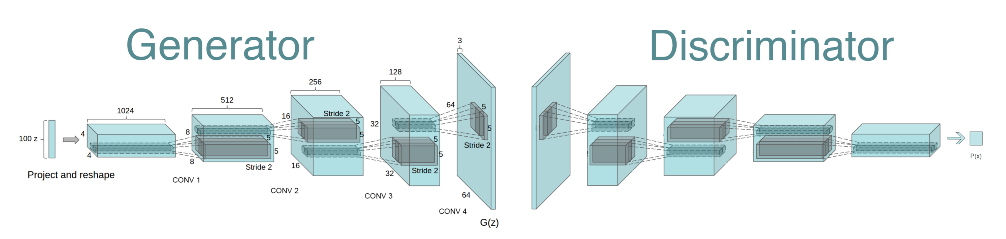
가장 기초적인 GAN의 구조는 위와 같으며 핵심 요소는 총 3가지 입니다.
1. 학습 데이터로 사용되는 실제 이미지 (Real image)
2. 가짜 이미지를 생성하는 생성자 (Generator)
3. 실제와 가짜를 구분하는 판별자 (Discriminator)
Training
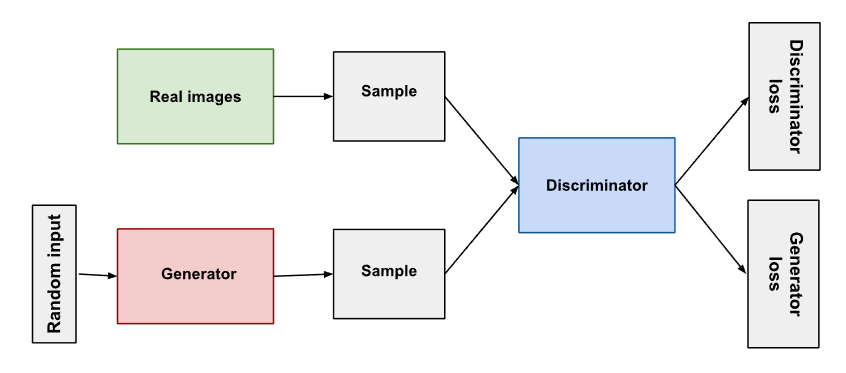
판별자와 생성자의 학습 프로세스는 별도로 구성됩니다.
이를 일련의 학습 파이프라인으로 병합하기 위해 GAN의 학습은 번갈아(Alternative) 진행됩니다.
이하의 내용은 최초의 GAN 논문에서 사용된 Minimax GAN Loss 기준으로 서술됐습니다.
1단계 판별자가 n회 이상의 epoch동안 학습합니다. (n ≥ 1)
2단계 생성자가 n회 이상의 epoch동안 학습합니다. (n ≥ 1)
3단계 1단계와 2단계를 반복하며 판별자와 생성자를 동시에 학습시킵니다.
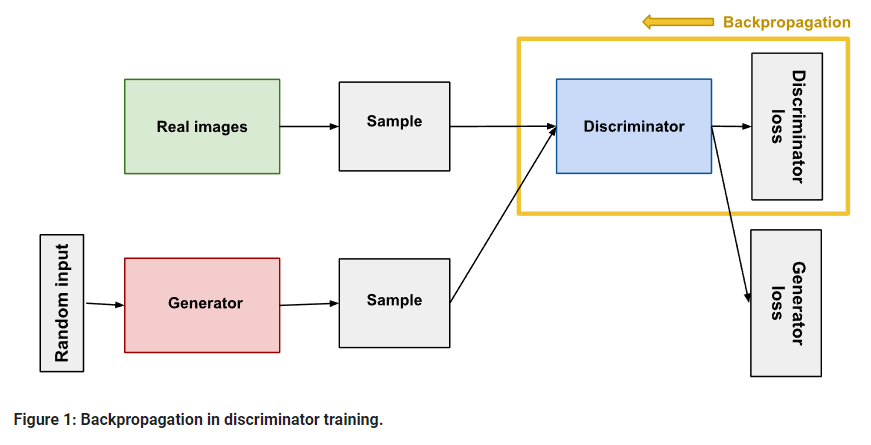
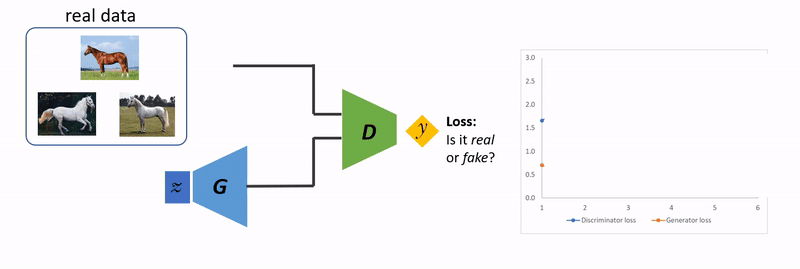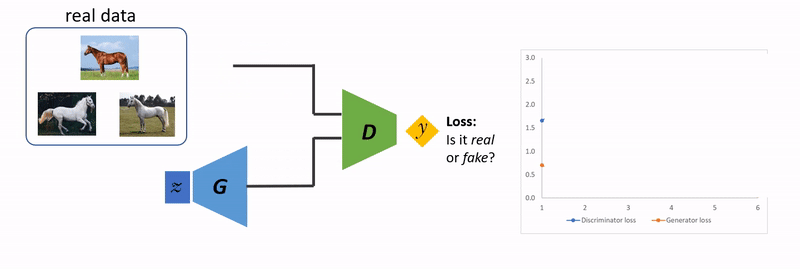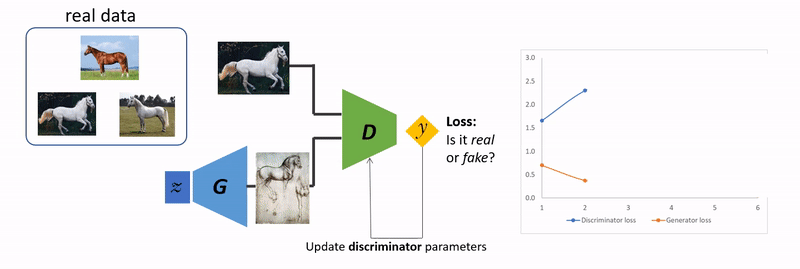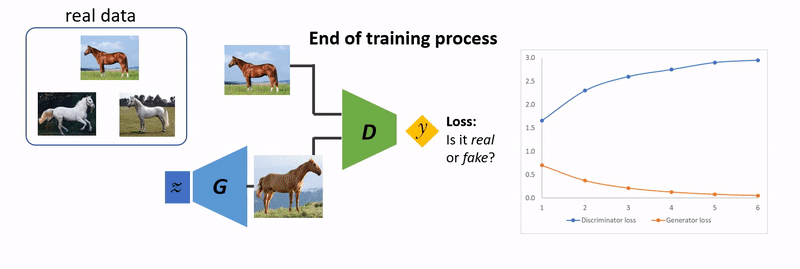
판별자 학습
1. 판별자의 손실함수(D_Loss)만 학습에 사용되며 최대한 D_Loss를 늘리는 방향으로 학습됩니다.
2. 역전파는 판별자에서만 이루어집니다. 이 때 실제 이미지와 1(real_label)에 대한 loss와 가짜 이미지와 0(fake_label)에 대한 loss를 더해 최종적인 D_Loss를 계산합니다.
3. 판별자의 학습이 진행되는 동안 생성자의 gradient가 고정됩니다. 만약 생성자의 gradient가 같이 업데이트 된다면 판별자의 분류 전략이 매우 자주 바뀌게 되고 gradient의 방향성이 분산되어 학습에 지장을 초래하기 때문입니다.
4. 판별자는 output으로 0~1 사이의 값을 가져야 하는 이진 분류 모델이므로 모델 끝단에 sigmoid함수가 위치하게 됩니다.
실제 이미지의 레이블을 1로, 생성자가 만들어낸 가짜 이미지의 레이블을 0으로 입력받아 이진 분류 학습을 수행합니다.
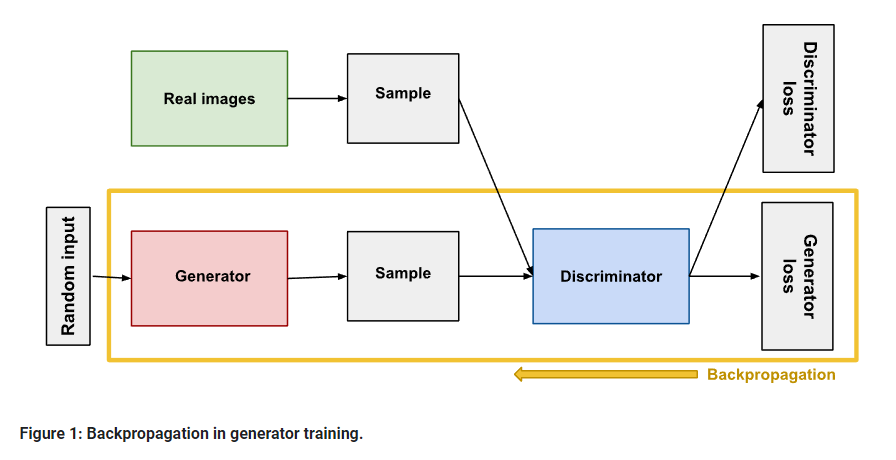
생성자 학습
1. 생성자의 손실함수(G_Loss)만 학습에 사용되며 최대한 G_Loss를 줄이는 방향으로 학습됩니다.
2. 역전파는 항상 판별자를 거쳐 생성자에 도달합니다. 즉, 판별자의 피드백에만 전적으로 의존하며 학습합니다. 하지만 생성자의 성능은 판별자에게 영향을 줄 수 있습니다. 이는 손실함수에서도 나타나는데, 판별자의 손실함수(D_Loss)에는 생성자의 예측(G(x) = x_hat)에 대한 항이 존재하여 생성자가 정교해질수록 판별자의 분류 전략도 고도화될 수 있게 됩니다.
3. 마찬가지로 생성자의 학습이 진행되는 동안 판별자의 gradient가 고정됩니다. 판별자의 줏대가 매번 바뀌면 생성자의 수렴 속도가 느려질 수 있기 때문입니다.
4. 생성자는 output으로 이미지를 표현해야 하므로 Deconvolutional Network로 이루어져 있습니다.
(Deconvolution은 output으로서 이미지를 원할 때 사용하는 신경망 구조입니다. 대표적으로 AutoEncoder의 Decoder블럭이 있습니다.)
일반적으로 판별자가 가짜 이미지에 대해 실제:가짜 = 50:50의 결론을 내리는 순간을 학습 종료 시점으로 봅니다.
그 이상으로 학습하게 되면 판별자가 생성자에 전달하는 피드백의 신뢰성이 낮아져 모델이 생성하는 이미지의 품질이 오히려 낮아질 수 있습니다.
LOSS

GAN기반 모델의 손실함수는 매우 다양하며, 지금도 활발하게 연구되고 있는 있는 분야입니다.
Standard GAN Loss Functions
Minimax GAN Loss (MM GAN Loss)
최초의 GAN 논문에서 제안된 손실함수입니다. (위의 사진은
판별자는 D_Loss를 최대한 높히고(maximize), 생성자는 G_Loss를 최대한 낮추는(minimize) 방향으로 학습되게 됩니다.
- 판별자의 입장에서 얻을 수 있는 이상적인 결과, 즉 최댓값은 0입니다.
실제 이미지 x에 대해 완벽하게 진짜라고 예측하면 D(x) = 1이 되어 첫번째 항은 0이 됩니다.
동시에 생성자가 만들어낸 가짜 이미지 G(z)에 대해 완벽하게 가짜라고 예측하면 D(G(z)) = 0이 되어 두번째 항은 log(1-0) = log1 = 0이 됩니다.
결국 V(D,G) = 0이 되며 이는 곧 판별자가 목표로 하는 loss값이 됩니다. - 생성자의 입장에서 얻을 수 있는 이상적인 결과, 즉 최솟값은 -∞입니다.
실제 이미지 x에 대해 가짜라고 예측하면 D(x) = 0이 되어 첫번째 항은 -∞로 발산하게 됩니다.
동시에 생성자가 만들어낸 가짜 이미지 G(z)에 대해 진짜라고 예측하면 D(G(z)) = 1이 되어 마찬가지로 -∞로 발산하게 됩니다.
결국 V(D,G) 또한 -∞로 발산하게 되며 이는 곧 생성자가 목표로 하는 loss값이 됩니다.
하지만 일반적으로 GAN의 학습은 판별자가 실제 이미지에 대해서도 50:50, 가짜 이미지에 대해서도 50:50으로 예측하게 되면 성능이 포화됐다고 보기 때문에 loss값이 0 또는 -∞로 발산하게 될 경우는 없습니다.
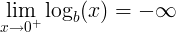
Non-Saturating GAN Loss (NS GAN Loss)

이전 MM GAN의 G_Loss는 생성자가 판별자만큼 빠르게 학습할 수 없으면 결국 판별자가 생성자를 압도하게 되어 학습이 제대로 진행되지 못하여 모델의 성능이 매우 떨어지게 포화되게 됩니다.
기존의 MM GAN G_Loss는 이미지가 가짜로 예측될 확률을 최소화하려는 반면, NS GAN G_Loss는 실제로 예측될 확률을 최대화하는 방향으로 관점을 바꾼 Loss입니다.
Alternate GAN Loss Functions
Least Squares GAN Loss
Wasserstein GAN Loss
GAN의 문제점
모델 훈련의 불안정성 (instability)
성능이 안정적으로 수렴하지 못하는 경우가 생깁니다.
판별자와 생성자가 고루 학습이 되어야하는데, 판별자가 생성자를 압도하는 경우가 발생합니다.
성능 평가의 어려움
GAN의 실질적인 성능은 사람의 눈으로 파악할 수 밖에 없습니다.
(PSNR, SSIM은 사람 입장에서의 평가를 대변하지 못함)
overfitting을 판단할 수학적 근거가 부족합니다.
Mode collapsing 문제
훈련된 multi-modal 데이터의 일부 mode가 누락된 문제
바꿔말해 판별자를 속이기 쉬운 데이터만 편파적으로 학습하게 됩니다.
Ex) 0~9의 숫자로 구성된 데이터셋(MNIST)로 학습한 경우에 특정 숫자(5)를 생성해내지 못합니다.
강아지의 제한된 색상과 특징을 생성하는 법을 학습할 수도 있습니다.
Mode collapsing 문제를 해결하기 위해 제안된 모델들이 있습니다.
