[논문 리뷰] 내맘대로 정리하는 GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (1. Introduction)
T2I-GLIDE

Dall-E 기반 연구를 디벨롭하고 있다보면 OpenAI가 또 하나를 던져준다😭 대강 아키텍쳐 정도만 이해하고 "아 그렇구나! 세상엔 똑똑한 사람들이 너무많아!"라고 생각하며 아는 척 했던 논문만 수십개,, 이제 굵직한 논문들은 제대로 정리해보고자 한다.

OpenAI에서 GLIDE 이전에 발표한 Dall-E의 경우 Transformer 기반의 auto regressive model이라 DVAE 정도만 이해하면 그나마 쉽게 읽혔는데, 갑분 diffusion model.. 서론부터 힘들었다. 그래서 GLIDE는 (3)~(4)파트로 나누어서 포스팅하고자 한다.
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Paper: https://arxiv.org/pdf/2112.10741.pdf
주의🤚: Introduction을 완벽히 이해하고 논문을 읽자는 타입이다보니, Introduction은 거의 번역에 가깝습니다!
1. Introduction
이미지는 텍스트로 쉽게 설명될 수 있지만, 이미지를 만들기 위해서는 전문적 기술, 그리고 시간이 필요합니다. 따라서 텍스트를 prompt로 이미지를 generating 할 수 있는 기술(Text Driven Image Generating)은 인간에게 쉽게 풍부한 시각적 콘텐츠를 만들어 낼 수 있는 힘을 줍니다. 또한 Text driven image editing 기술은 이미지의 반복적인 개선과 세밀한 제어를 가능케 하며, 두 가지 모두 실제 application에서 매우 중요한 포인트입니다.
최근의 텍스트를 조건으로 한 이미지 generating 모델들은 자유 형식의 text prompt로 이미지를 합성할 수 있으며, 관련 없는 오브젝트들을 그럴듯하게 구성할 수 있습니다. 그러나 아직 text prompt의 '모든 측면'을 포착하는 photorealistic한 이미지를 생성할 수는 없습니다. 반면에, unconditional image model(text prompt 조건부 모델이 아닌, like unconditional GAN)은 photorealistic한 이미지를 합성할 수 있습니다. 따라서 Conditional한 이미지 모델에서 photorealism을 달성하기 위해 많은 노력이 있었습니다.
- augmented diffusion models with classifier guidance는 diffusion model을 classifier label의 condition으로 학습할 수 있는 기술입니다.(diffusion model이 무엇인가에 대한 이해가 없는 상태에서, introduction의 대부분은 이해되지 않을 것입니다. 2.Background를 이해하고 다시 introduction을 읽으시는 것을 추천합니다!) 분류기는 먼저 noising된 이미지에 대해 훈련되며, diffusion sampling process동안 분류기의 gradient는 sample을 라벨로 유도하는데에 사용됩니다.(noise뿐 아니라 gradient를 추가적 교란으로 활용함)
- classifier-free guidance입니다. 따로 학습된 분류기 없이도 비슷한 성능을 달성할 수 있었는데, 이는 레이블이 있는 diffusion model의 예측과 없는 diffusion model의 예측(score)에 선형 조합을 사용해 보간하는 guidance입니다.
Photorealistic한 샘플을 생성할 수 있는 guided diffusion model과 자유 형식 프롬프트를 처리할 수 있는 text to image 모델로, GLIDE에서는 text를 조건으로한 이미지 합성 문제에 diffusion model을 적용합니다. 그 방식은 아래와 같습니다.
- 텍스트 인코더를 사용하여 자연어 설명을 조건으로 하는 35억 파라미터의 diffusion model을 훈련합니다.
- diffusion model을 text로 guiding 하는 두가지 기술을 비교합니다. 첫번째는 CLIP guidance, 두번째는 분류기 없는 guidance입니다.
- Human evalutation과 automated evaluation을 사용하여, 논문에서는 분류기 없는 guidance(classifier-free guidance)가 더 높은 퀄리티의 이미지를 산출한다는 것을 발견합니다.

그림 1 분류기 없는 guidance로 guiding한 GLIDE에서 선택된 sample입니다. 해당 논문에서 제시된 모델이 그림자와 반사가 있는 photorealistic한 이미지를 생성할 수 있고, 올바른 방식으로 여러 concept(개념)들을 구성할 수 있으며, 새로운 concept의 예술 이미지를 생성할 수 있음이 관찰되었습니다.
paper에 의하면, 분류기 없는 guidance로 학습된 모델로 생성한 샘플들은 photorealistic할 뿐만 아니라 광범위한 세계의 지식들을 모두 반영하고 있었습니다. Human evaluation 결과, GLIDE의 샘플은 photorealistic하냐 안하냐에 대해 87%의 DALL-E 샘플보다 더 선호되고, 캡션 유사성(condition guiding 반영 정도)에 대해서도 69%의 DALL-E 샘플보다 선호되었습니다.
또한, 추가로 paper에서는 GLIDE의 editing 기능에 대해 언급합니다. GLIDE는 다양한(wide variety) 텍스트 프롬프트를 제로샷으로 렌더링할 수 있지만, "복잡한 프롬프트에 대해서"(결국은 한계) realistic한 이미지를 생성하는데에는 어려움을 겪을 수 있다고 합니다. 따라서, GLIDE 연구진은 이미지의 제로샷 생성 기능 외에도 "복잡한 프롬프트와 일치할 때까지 인간이 모델의 샘플을 반복적으로 개선"할 수 있도록 하는 editing 기능을 제안합니다.

그림 2 GLIDE의 Text driven Image Inpainting 예시. 녹색 영역이 지워지고 모델은 주어진 프롬프트를 기반으로 지워진 영역을 채웁니다. GLIDE는 주변의 스타일과 조명을 매치하여 사실적인 완성도를 낼 수 있습니다.
특히, 연구진은 텍스트 프롬프트를 사용하여 기존의 이미지를 사실적으로 편집할 수 있다는 것을 발견하여 Image inpainting(이미지의 누락된, 손상된 부분을 복원하는 것)을 수행하도록 GLIDE를 finetuning 했다고 말합니다. 모델에 의해 editing된 부분은 그림자, 반사를 포함한 주변의 스타일, 조명과 설득력 있게 매치됩니다. 연구진은 이러한 editing 기능을 제안함으로써 GLIDE가 인간이 전례 없는 속도와 용이함(ease)으로 설득력 있는 custom image를 만드는데 도움이 될 수 있다고 말합니다.
마지막으로 paper의 intro에서 명시되고 있는 부분은 윤리 측면입니다. paper에 따르면, GLIDE 악용시 설득력 있는 허위 정보/딥 페이크를 생성하는데 필요한 노력을을 크게 감소시킬 수 있습니다. 따라서, 연구진은 향후 연구를 하면서 이러한 악용 사례(허위 정보/딥 페이크)로부터 보호하기 위해, 필터링된 데이터셋에 대해 훈련된 소형 diffusion model과 noised CLIP 모델만을 공개합니다.
해당 paper에서 공개된 모델(시스템)은 GLIDE라고 불리며, 이는 Guided Language to Image Diffusion for Generation and Editing을 의미합니다. 또한 앞서 언급한 윤리적 이슈에 의해 공개된 작은 필터링된 모델은 GLIDE(filtered)라고 부릅니다.
2. Background
CLIP-guided, 혹은 Classifier-free guided Diffusion Model인 GLIDE를 이해하기 위한 간단한 Background를 소개하고 있다. 개괄적으로 설명할 주요 골자 4개는 다음(2.1~2.4)과 같으며, 대략적인 설명을 첨부한다.
2.1 Diffusion Models
위 수식은 diffusion model의 forward process q이다. 이는 노이즈가 하나도 없는 샘플 x0에 점진적으로 t step동안 가우시안 노이즈를 뿌려 x1~xt의 잠재변수를 만드는 과정이다. 각 step에서 추가된 noise가 충분히 작다면, forward process q를 따른 후의 xt는 가우시안 분포에 근사하고, xt가 가우시안 분포에 잘 근사된다면 reverse process p 학습 역시 가능해진다는 원리이다. -> 점진적으로 noise가 없는 x0을 생성하는 과정을 학습시킬 수 있다.
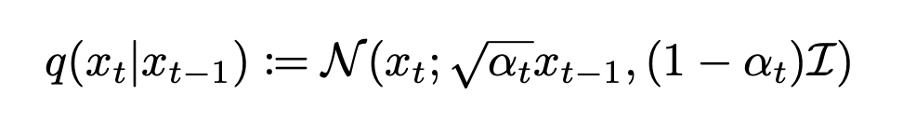
2.2 Guided Diffusion, 2.3 Classifier-free guidance, 2.4 CLIP guidance
참고 paper: https://arxiv.org/pdf/2105.05233.pdf
위 [Diffusion models beat gans on image Synthesis] paper를 읽는다면 GLIDE-2.Background-2.2 Guided Diffusion을 완벽히 이해할 수 있을 것이다. guided Diffusion은 말 그대로 Diffusion model을 label 정보로 guiding 한다는 맥락이다. 어떻게 guiding 할 수 있는가? classifier에 의해 예측된 target class y의 gradient를 활용한다. Guided Diffusion Model의 뮤와 분산은 기존 '노이즈' 뿐만 아니라 class classifier의 gradient에 대해서도 perturbed(동요, 교란)된다. 또한 2.3 Classifier-free guidance와 2.4 CLIP guidance는 GLIDE paper에서 비교한 text prompt guided diffusion model의 2가지 guiding 방식이며, 전자의 경우 별도의 classifier model을 학습할 필요가 없는 것이 특징이고, 후자의 경우 classifier를 CLIP 모델로 대체한 것이 특징이다. GLIDE paper에서는 전자(classifier-free guidance)의 성능이 더 좋다고 언급하고 있다.
자세한 설명은 다음 포스팅에!



2편은 언제 나오나요! ㅋㅋㅋㅋ