Day1
개발환경
cd {} : {} 으로 이동
ls : 현재 위치에 어떤 파일이 있는지
pwd : 현재 위치 정보
touch {파일 이름.확장자} : {} 파일 생성 ex. new_file.db / new_file.pygit clone https://github.com/{github_id}/ds-sa-simple-git-flow
git add .
git commit -m '메시지'
git push origin mainconda deactivate
conda create -n ds-sa-simple-git-flow python=3.8pip list
Day2
SQL - 01
In-Memory: 파이썬에서 프로그램을 다룰 때에는 프로그램이 실행될 때에만 존재하는 데이터가 있음
-> 프로그램 실행이 종료되면 사용하던 데이터도 같이 없어짐
File I/O: 파일을 읽어오는 방식으로 작동하는 형태, 엑셀 시트나 CSV와 같은 형태는 파일을 매번 읽어와야 하고 파일이 손상되거나 여러 개의 파일을 동시에 다뤄야 하는 등 복잡하고 데이터량이 많아질수록 힘들어짐
관계형 데이터베이스: 하나의 CSV파일이나 엑셀시트를 한 개의 테이블로 저장할 수 있고 한번에 여러 개의 테이블을 가질 수 있어SQL을 활용해 데이터를 가져오기 수월
SQL
- 정의 & 특징
- Structured Query Language
- 질의문
- 데이터베이스 언어의 기준으로 주로 관계형 데이터베이스에서 사용
- ex. MySQL, Oracle, SQLite, PostgreSQL 등
- 데이터베이스 용 프로그래밍 언어
- 데이터베이스에 쿼리를 보내 원하는 데이터만을 가져올 수 있게 함
-
SQL JOIN
-
문법 작성 순서 & 실행 순서

# 작성 순서
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
# 실행 순서
FROM
ON
JOIN
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
ORDER BYDB
DataBase를 왜 써야할까?
- 데이터 단위로 작업가능
- 동시에 접근하는 경우 훼손되지 않음
기본키와 외래키는 무엇일까?
- 기본키 : 테이블의 기준이 되는 키(유니크한 값을 가짐, Null 값은 안됨, 다른 테이블에서 외래키가 될 수 있음)
- 외래키 : 두 개의 테이블을 연결해주는 다리 (외래 테이블에서 기본키여야 함 - join을 했을 때 하나의 결과만 가져올 수 있어야함)
- 관계형 데이터베이스 특징
- relational database(RDB)
- 테이블을 사용하는 데이터베이스
keyword- 데이터 : 각 항목에 저장되는 값
- 테이블 (혹은 relation) : 사전에 정의된 행과 열로 구성되어 있는 체계화된 데이터 = 엔티티
- 필드 (혹은 column) : 테이블의 열
- 레코드 (혹은 tuple) : 테이블의 한 행의 저장된 정보 = instance
- 키 : 테이블의 각 레코드를 구분할 수 있는 값. 각 레코드마다 고유값이어야 하며 기본키 (primary key) 와 외래키 (foreign key) 등이 있을 수 있음
- ERD : 사전적으로 정리한 것 ( =! 스키마)
- 관계종류
-
1:1 관계
테이블의 레코드 하나당 다른 테이블의 한 레코드와 연결되어 있는 경우
 한 개의 전화번호당 한 명의 유저를 가지고 그 반대도 동일
한 개의 전화번호당 한 명의 유저를 가지고 그 반대도 동일 -
1:N 관계
테이블의 레코드 하나당 여러 개의 레코드와 연결되어 있는 경우
가장 흔하게 사용되는 관계
 한 유저가 여러 전화번호를 가질 수 있지만 반대는 성립 X = 한 전화번호는 한명의 유저만
한 유저가 여러 전화번호를 가질 수 있지만 반대는 성립 X = 한 전화번호는 한명의 유저만 -
N:N 관계
여러 개의 레코드가 여러 개의 레코드를 가지는 관계
조인 테이블을 만들어 관리
양방향에서 다수를 가질 수 있는 경우
 한 고객은 여러 개의 여행상품을 가질 수 있고 한 여행 상품 또한 여러 개의 고객을 가질 수 있음
한 고객은 여러 개의 여행상품을 가질 수 있고 한 여행 상품 또한 여러 개의 고객을 가질 수 있음- 'customer_package' 테이블의 역할은 그저 customer_id 와 package_id 를 묶어주는 역할
- 이 테이블을 통해서 어떤 고객이 어떤 여행 상품들을 가지고 있는지 혹은 어떤 여행 상품이 어떤 고객들을 가지고 있는지 등을 확인할 수 있음
- 중요한 것은 이를 따로 테이블로 생성했을 때에도 동일하게 기본키가 있어야 하는 것
-
자기참조 관계(Self referencing relationship)
 한 유저당 하나의 추천인을 가질 수 있음 하지만 추천인 입장에서는 여러 개의 유저를 가질수 있음 = 복수 추천 가능
한 유저당 하나의 추천인을 가질 수 있음 하지만 추천인 입장에서는 여러 개의 유저를 가질수 있음 = 복수 추천 가능- 1:N 관계와 비슷
- 데이터베이스 스키마
스키마 : 데이터베이스에서 데이터가 구성되는 방식과 서로 다른 엔티티 간의 관계에 대한 설명, 데이터베이스의 청사진데이터 모델링을 한다 = 스키마를 짠다
Day3
SQL - 02
관계형 데이터베이스를 더 강력하게 만드는 특징
-
트랜잭션
- 데이터베이스의 상태를 변화시키는 작업의 모음
- 통상적으로 정보의 교환이나 데이터베이스 갱신 등 일련의 작업들에 대한 연속처리단위를 의미
- 데이터베이스의 무결성이 보장되는 상태에서 요청된 작업을 완수하기 위한 작업의 기본 단위로 간주
- 주로 데이터베이스의 상태를 변화시키는 INSERT, DELETE, UPDATE 중 한개 이상의 DML(Data Manipulation Language)과 같이 사용
COMMIT
트랜잭션은 확정 신호를 알려줘야 데이터베이스에 반영
확정신호를 보내지 않으면 데이터베이스 내용에 변화X
확정신호 = COMMITROOLLBACK
COMMIT 과 반대 개념
앞으로 변경될 작업에 대한 내용을 취소한다는 의미
= 트랜잭션 수행 중에 지금까지 수행한 내용을 모두 취소하겠다- 각 트랜잭션은 하나의 특정 작업으로 시작해 묶여 있는 모든 작업들은 다 완료해야 끝남
- 하나의 작업이라도 실패하게 되면 전부 실패
- 트랜잭션은 성공 혹은 실패 두가지 결과만 존재
- 데이터베이스 트랙잭션의 정의는 ACID 특성들을 가지고 있음
- ACID(Atomicity, Consistency, Isoloation, Durabillity)
- 데이터베이스에서 일어나는 하나의 트랜잭션의 안전성을 보장하기 위해 필요한 성질들
Atomicity 원자성
하나의 트랜잭션을 구성하는 작업들은 전부 성공하거나 전부 실패야한 함
Consistency 상태 일관성
하나의 트랜잭션 이전과 이후 데이터베이스 상태는 이전과 같이 유효해야 함 = 데이터베이스의 제약이나 규칙에 의거한 데이터베이스여야 함
Isolation 고립성
하나의 트랜잭션이 다른 트랜잭션과 독립되어야 함 = 동시에 실행될 때와 연속으로 실행될 때의 데이터베이스 상태가 동일해야 함
Durability 지속성
하나의 트랜잭션이 성공적으로 수행되었다면 해당 트랜잭션에 대한 로그가 남고 런타임 오류나 시스템 오류가 발생해도 해당 기록은 영구적이어야 함
- 데이터베이스에서 일어나는 하나의 트랜잭션의 안전성을 보장하기 위해 필요한 성질들
GROUP BY
분할 -> 적용(집계연산) -> 결합
WHERE vs HAVING
WHERE 은 GROUP BY 전에 실행되기 때문에 집계연산이 안됨정규화
테이블을 효율적으로 구성하는 법
제1정규화 ~ 제5정규화 , 반정규화
보통 제3정규화까지 함
https://mr-dan.tistory.com/10
Day4
DB API
- DataBase Application Programming Interface
- 파이썬과 데이터베이스의 상호작용을 돕는 어떤 약속
DBeaver실행 : cursor,SQL실행 : connection
클라우드 데이터베이스
- 원격으로 관리되는 데이터베이스
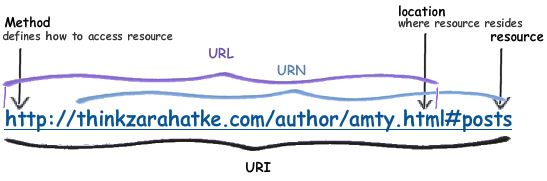
- 보통 원격으로 연결을 할 때에는 URI 형식 으로 연결
- URI 는 논리적 혹은 물리적 리소스를 찾을 때 사용
- URI 는 네트워크에서 정보를 찾거나 받아올 때 사용
서비스://유저_이름:유저_비밀번호@호스트:포트번호/경로
- DB API 를 왜 쓸까?
데이터베이스의 데이터를 활용하기 위해서
- 파이썬과 데이터베이스를 연결하기 위해서는 어떤 메스드를 사용해야 할까?
connect
세션을 열면 바로 쿼리를 날릴 수 있을까?
connect 메소드로 연결을 한다 = 세션을 열었다
connect은 데이터베이스와 연결된 하나의 세션을 보관
해당 세션을 통해 데이터베이스와 소통하기 위한cursor를 만들어 쿼리를 날림쿼리를 날리려면 어떤 메소드를 사용해야 할까?
cursor.execute
- 클라우드 데이터베이스란 무엇일까?
클라우드 서비스를 사용하는 데이터베이스
- 클라우드 데이터베이스는 왜 사용할까?
외부의 접근성이 높고 관리비용이 낮음, 어디로든 확장가능, 유지비용 낮음
BUT 보안문제, 속도, 클라우드가 죽으면 클라우드 쓰는 모든 서비스가 안됨(=관리할 수 없는 리스크)해당 세션을 통해 데이터베이스와 소통하기 위한cursor를 만들어줌
# db 테이블에 csv데이터 넣기
import psycopg2 # db연결
connection = psycopg2.connect (
host =
user =
password =
database =
)
cur = connection.cursor()
cur.execute("""CREATE TABLE table_name(
id INTEGER PRIMARY KEY,
name VARCHAR(4));
""")
import csv
index = 0 # 첫 열이 인덱스일때
with open('file_name.csv' ,'r') as file:
row = csv.reader(file)
next(row) # 다음 인덱스부터 읽기
for i in row:
cur.execute(f"INSERT INTO table_name (columns name ---) VALUES({index},{i[0]} ---);")
index += 1
connection.commit()
cur.close()
connection.close()
csv : https://m.blog.naver.com/pjok1122/221590220300
# cursor.fetchone
## 한번 호출에 하나의 row만을 가져올 때 사용, fetchone()을 여러 번 호출하면 호출할 때마다 한 row씩 데이터를 가져오게 됨
# cursor.fetchall
## 모든 데이터를 한꺼번에 가져올 때 사용
# cursor.fetchmany(n)
## n개 만큼의 데이터를 한꺼번에 가져올 때 사용