저장 프로시저란,
SQL Server에서 제공되는 프로그래밍 기능.
쿼리문의 집합으로서, 어떠한 동작을 일괄 처리하는 용도로 사용된다.
즉, 인자 값만 전달하여 동일한 로직의 복잡한 쿼리문을 하나의 함수로 실행할 수 있도록 한다.
예시
- 일반적인 쿼리문
SELECT * FROM `user` WHERE name ='네이버';
SELECT * FROM `user` WHERE name ='라인';
SELECT * FROM `user` WHERE name ='토스';- 저장 프로시저
CREATE PROC SELECT_BY_NAME
@NAME NVARCHAR(3)
AS
SELECT * FROM USER WHERE NAME =@NAME;저장 프로시저의 동작방식
📍 일반 SQL 동작방식
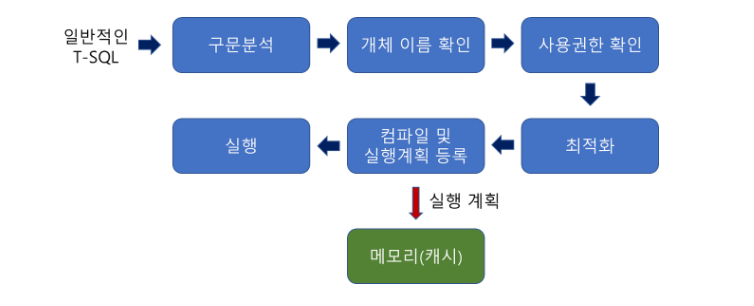
SELECT 'ID' FROM 'USER'해당 쿼리를 예시로 처음 실행한다고 가정하자.
- 순서
- 구문자체에 오류가 없는지 분석, 오타가 있다면 오류메시지 반환
- 개체 이름 확인은 USER라는 이름의 테이블이 현재 DB에 있는지 확인을 하고, 있다면 그 안에 ID라는 컬럼이 있는지 확인
- 현재 접근한 사용자가 USER테이블에 접근 권한이 있는지 확인
- 최적화 단계에서는 해당 쿼리가 가장 좋은 성능을 낼 수 있는 경로를 설정한다. 인덱스 사용여부에 따라서 경로가 달라질 수 있기 때문에 테이블 스캔, 클러스터 인덱스 스캔이 진행됨
- 최적화 결과를 토대로 결과를 캐시에 저장
- 저장한 컴파일 결과를 실행
해당 쿼리를 다시 실행하면,
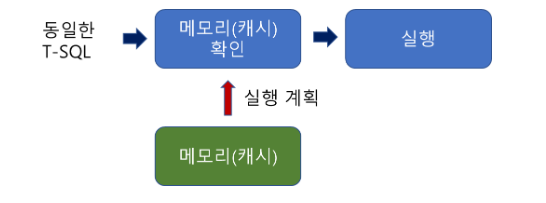
- 순서
- 캐시에 해당 쿼리에 대한 결과가 있는지 확인
- 실행
🔎 다만 여기서 한글자라도 이전 쿼리와 달라진다면 처음부터 다시 동작한다.
📍 저장 프로시저 동작방식
저장 프로시저를 정의했을 때의 동작방식
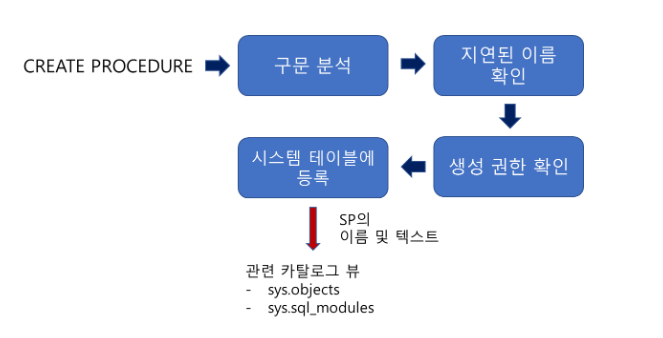
- 구문자체에 오류가 없는지 분석, 오타가 있다면 오류메세지를 반환
- 지연된 이름 확인 과정은 저장 프로시저의 특징 -> 해당 테이블이 존재하는지를 판단하는 것은 프로시저
실행시점에 확인이 가능하므로 정의할 때는 같은 개체가 존재하는지 확인하지 않음 - 현재 접근한 사용자가 저장프로시저를 생성할 권한이 있는지를 확인
- 시스템 테이블 등록을 진행. 저장 프로시저의 이름과 코드가 관련 시스템 테이블에 등록됨.
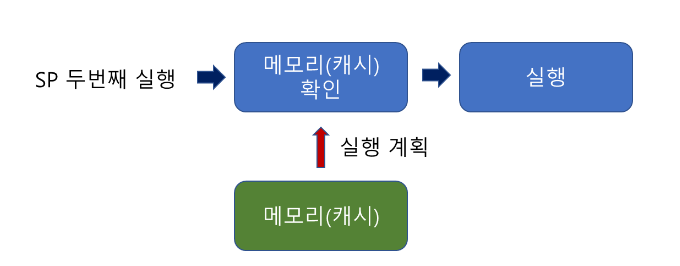
저장프로시저를 처음으로 실행할 때의 동작방식
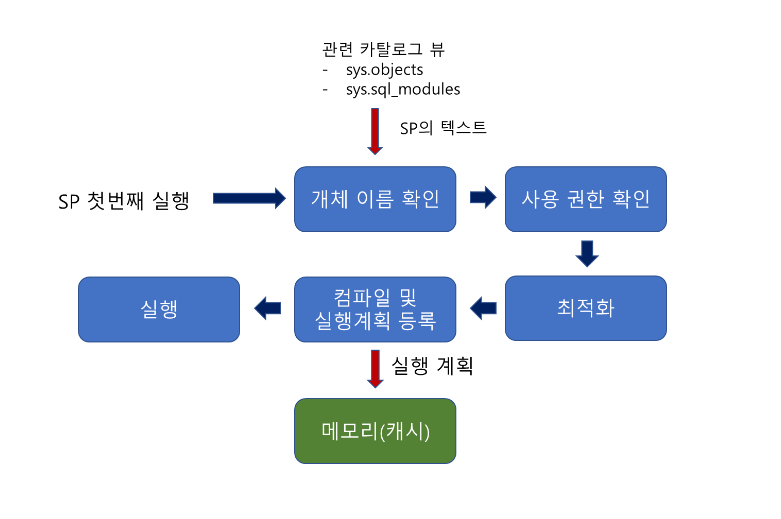
일반적인 쿼리의 동작방식과 비슷하다.
정의할 때 지연된 이름 확인을 개체이름 확인단계에서 진행한다.
저장프로시저를 두번째로 실행할 때는 캐시만 확인하면 된다.
장단점
✨ 장점
- 보안성 향상 : 프로시저 단위로 권한을 주므로, 보안사고에 대한 대처가 유연하다
- 네트워크 소요시간 절감 : 쿼리를 다중으로 실행할 때, 한번의 호출을 통해 다중의 쿼리가 실행되므로 네트워크 소요시간을 줄일 수 있다.
- 운영배포 용이성 : 별도의 WAS서버 재가동 없이, SP(Stored Procedure의 약자로 저장프로시저)수정만으로 조회, 수정, 추가 등의 가벼운 소스 변경 등이 가능하며 긴급배포 시에도 용이하다.
- SQL Server의 성능 향상 : 저장 프로시저를 처음에 실행하면 최적화, 컴파일 단계를 거쳐 그 결과가 캐시에 저장되는데, 이 후에는 해당 저장 프로시저를 실행하면 캐시에 있는 것만 가져와서 사용하므로 실행속도가 빨라지게 된다.
- 유지보수 및 재활용 용이 : 자바, C#등으로 만들어지 응용프로그램에서 직접 SQL문을 호출하지 않고 저장 프로시저의 이름을 호출하도록 설정해서 사용하는데, 이때 개발자는 수정 요건이 있을 때 저장프로시저만 수정하면 되므로 유지보수 측면에서 유리해진다.
🤔 단점
- 수정에 따른 낮은 처리 성능 : 앞에서 저장 프로시저를 실행할 때 최적화 단계를 수행한다고 했지만, (최적화 단계에서 인덱스를 사용할지 안할지를 결정) 인덱스를 사용한다고 항상 수행결과가 빨라지지 않는다.
만약에 가져올 데이터가 다량인데 인덱스를 사용하면 오히려 성능이 나빠지게 된다.
저장 프로시저는 첫번째 수행 시에 최적화가 이루어져서 인덱스 사용여부가 결정되어 버린다.
만약에, 첫번째 수행때 데이터를 몇건만 가져오도록 파라미터가 설정되어 있다면, 인덱스를 사용하도록 최적화되어 컴파일 됐을 것이다.
그런데 두번째 수행에서 많은 건수의 데이터를 가져오도록 파라미터가 들어가면 안타깝게도 저장 프로시저는 그냥 인덱스를 사용하는 프로시저를 실행한다.
이렇게 되어 버리면 성능에 크게 문제가 된다.(이를 방지 하기 위해서는 저장 프로시저를 다시 컴파일 해주어야 함.) - 디버깅의 어려움 : APP에서 저장 프로시저를 호출하는 경우, 문제가 생겨도 해당 이슈 추적이 쉽지 않다.

Drill처럼 파고들자 🔥