
트랜잭션 격리 수준이란,
- 트랜잭션에서 일관성이 없는 데이터를 허용하도록 하는 수준
- ACID(원자성/일관성/고립성/지속성)성질 중 고립성을 구현하는 개념
- 한 트랜잭션에서 데이터가 수정되는 과정이 다른 트랜잭션과는 독립적으로 진행되어야 하는 특성
- 격리 수준 : 각기 다른 트랜잭션들이 서로에게 어느 정도로 격리되어야 하는지를 나타냄
격리 수준의 필요성
-
데이터베이스는 ACID 같이 트랜잭션이 원자적이면서도 독립적인 수행을 하도록 한다.
-
그래서 Locking 개념이 등장
📍
Locking이란,
트랜잭션이 DB를 다루는 동안 다른 트랜잭션이 관려하지 못하게 막는 것 -
하지만 무조건적인 Locking은 옳지 않음 -> 동시에 수행되는 많은 트랜잭션들을 순서대로 처리하면 DB성능이 떨어지게 됨
-
반대로 Locking 비율을 너무 줄인다면 -> 응답성은 높겠지만, 잘못된 값이 처리될 여지가 높음
격리 수준 종류

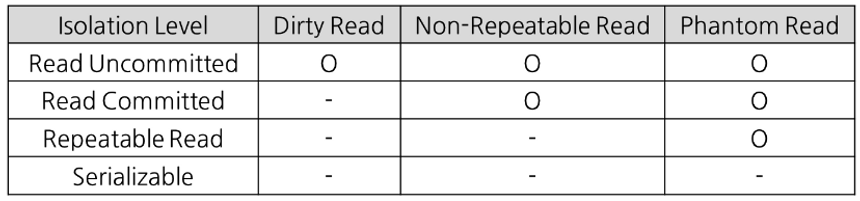
Read Uncommited (Level 0)
- SELECT문장이 수행되는 동안 해당 데이터에
Shared Lock이 걸리지 않는 계층 - 트랜잭션이 처리중이거나, 아직 commit되지 않은 데이터를 다른 트랜잭션이 읽는 것을 허용
- 그래서 데이터베이스의 일관성이 유지되는 것이 불가능함
Read Commited (Level 1) - 기본값
- SELECT문장이 수행되는 동안 해당 데이터에
Shared Lock이 걸리는 계층 - 트랜잭션이 수행되는 동안 다른 트랜잭션이 접근할 수 없어 대기 하게 됨. Commit 된 트랜잭션만 조회 가능
- SQL 서버가 기본적으로 사용하는 격리 수준임
Repeatable Read (Level 2)
- 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에
Shared Lock이 걸리는 계층 - 트랜잭션이 범위 내에서 조회한 데이터 내용이 항상 동일함을 보장함.
- 다른 사용자는 트랜잭션 영역에 해당되는 데이터에 대해 수정이 불가능
Serializable (Level 3)
- 트랜잭션이 완료될 때까지 SELECT문장이 사용하는 모든 데이터에
Shared Lock이 걸리는 계층 (Repeatable Read와 동일) - 완벽한 읽기 일관성 모드를 제공함
- 다른 사용자는 트랜잭션 영역에 해당되는 데이터에 대해 수정 및 입력이 불가능
✔ 참고
- 레벨을 높게 조정할 수록 비용이 높아진다!
동시성,데이터무결성이 연관되어 있으므로 잘 고려해야 한다.
낮은 격리 수준을 이용하면 생기는 현상
1. Dirty Read
- Commit되지 않은 수정 중인 데이터를 다른 트랜잭션이 읽을 수 있도록 허용할 때 발생.
- 어떤 트랜잭션이 아직 실행이 끝나지 않은 다른 트랜잭션에 의한 변경 사항을 보게 되는 경우
2. Non-Repeatable Read
- 한 트랜잭션에서 같은 쿼리를 두 번 이상 수행할 때 그 사이에 다른 트랜재션이 값을 수정 또는 삭제함으로써 여러 쿼리의 결과가 상이하게 나오는 비일관성 현상
3. Phantom Read
- 한 트랜잭션 안에서 일정 범위의 레코드를 두 번 이상 읽을 때, 첫 번째 쿼리에서 없던 레코드가 두 번째 쿼리에서는 나타나는 현상
- 트랜잭션 도중에 새로운 레코드가 삽입되는 것을 허용 시 발생함.
트랜잭션 사용 시 주의사항
-
가능하다면 트랜잭션 각각의 범위는 최소화하자
: 모든 작어벵 트랜잭션이 필요하다고 해서 한 단위로 묶어버리는 것은 좋지 않다. 여러 개의 트랜잭션으로 쪼개서 각 범위를 최소화해야 한다. -
트랜잭션이 필요한 기능 범위는 최소화하자
: 일반적인 데이터베이스 Connection은 개수가 제한적이므로, 각 Connection이 프로그램에 오래 머물 수록 병목현상이 일어날 확률이 높아진다. -
외부 자원과의 연결 작업은 제거하자
: 메일 전송, FTP 파일 전송, 네트워크 통신 등, 해당 작업이 실패하거나 시간이 오래 걸리는 경우 프로그램 전체가 위험할 수 있다.

Drill처럼 파고들자 🔥
저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!