기수정렬(Radix sort)
기수정렬은 낮은 자리수부터 비교하여 정렬해 간다는 것을 기본 개념으로 하는 정렬 알고리즘입니다. 기수정렬은 비교 연산을 하지 않으며 정렬 속도가 빠르지만 데이터 전체 크기에다가 기수 테이블의 크기만한 메모리가 더 필요합니다.
정렬방식
- 0~9 까지의 Bucket(Queue 자료구조의)을 준비한다.
- 모든 데이터에 대하여 가장 낮은 자리수에 해당하는 Bucket에 차례대로 데이터를 둔다.
- 0부터 차례대로 버킷에서 데이터를 다시 가져온다.
- 가장 높은 자리수를 기준으로 하여 자리수를 높여가며 2번 3번 과정을 반복한다.
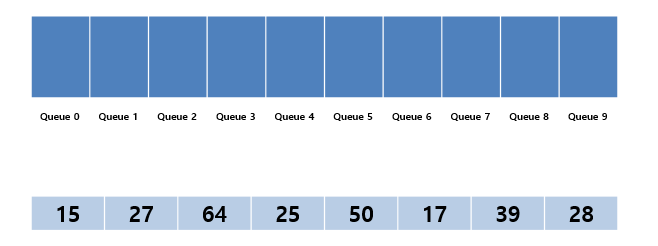
위의 그림과 같이 각 숫자에 해당하는 Queue공간을 할당하고 진행합니다.

먼저 1의 자리 숫자부터 시도를 합니다. 데이터 순서대로 각 1의 자리에 해당되는 Queue에 데이터가 들어가게 됩니다. 15같은 경우는 1의 자리가 5이므로 Queue 5에 들어가는 방식입니다.

위의 그림처럼 다시 0번 Queue부터 차례대로 데이터를 가지고 와서 원래의 배열에 넣어주게 됩니다.
1의 자리에 대한 정렬이 완료되었습니다. 다음으로는 10의 자리에 대하여 같은 작업을 반복합니다.
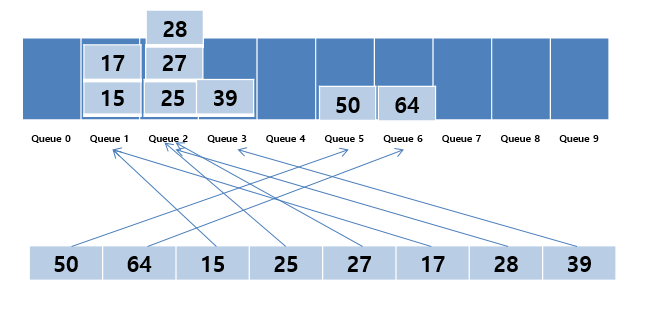
마찬가지로 각 데이터의 10의 자리에 해당되는 Queue에 데이터를 위치 시킵니다. 그런 다음 0번 Queue부터 차례대로 다시 데이터를 가지고 옵니다.
정렬 최종 결과
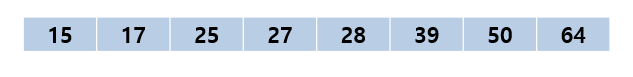
- 시간 복잡도 : O(d * (n + b))
-> d는 정렬할 숫자의 자릿수, b는 10 (k와 같으나 10으로 고정되어 있다.)
( Counting Sort의 경우 : O(n + k) 로 배열의 최댓값 k에 영향을 받음 )
-
장점✨ : 문자열, 정수 정렬 가능
-
단점🧐: 자릿수가 없는 것은 정렬할 수 없음. (부동 소숫점), 중간 결과를 저장할 bucket 공간이 필요함.
계수정렬(Counting sort)
정렬방식
- 계수 정렬(counting sort)는 정렬되지 않은 배열의 수들이 몇 번 나왔는지 적어둔다.
- 몇 번 나왔는 지 기록한 배열을 count 배열이라 하면, count 배열을 앞부터 순회하여, 자신이 정렬된 배열에서 몇 번째에 나와야 하는 지 기록한다.
- 정렬된 배열에서 자신이 몇 번째에 나와야하는 지 기록한 배열을 sum 배열이라 하면, sum 배열의 맨 마지막 값부터 순회하여, 정렬 배열에 값을 써둔다.
- 값을 쓸 때, count배열과 sum배열의 값을 하나씩 줄이고 0 될 때 까지 반복한다.

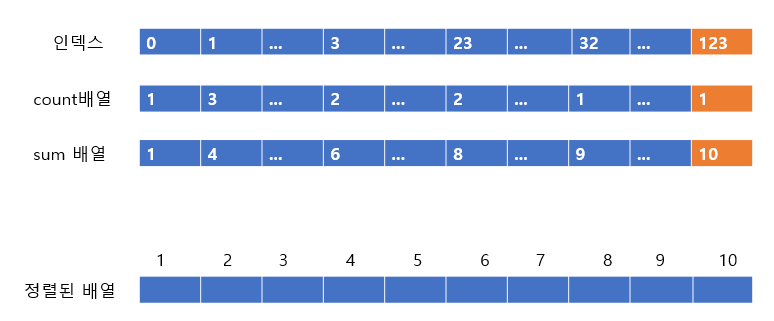
위의 그림과 같이 정렬되지않은 배열이 있다고 하면 count배열은 아래와 같다.
count = [
0 : 1개
1 : 3개
3 : 2개
23 : 2개
32 : 1개
123 : 1개
]
위의 그림과 같이 count 배열이 나오게 된다. 이제 count 배열을 통해 sum 배열을 만들어준다. (*sum 배열은 내 앞에 숫자가 몇 개 있느냐를 세어주는 것이다. + 자신포함)
0 : 1개
1 : 4개
3 : 6개
23 : 8개
32 : 9개
123 : 10개
시간복잡도 분석
O(n)
WHY?
count 배열을 만드는 데 필요한 시간은 O(n)이다. 왜냐하면 정렬되지 않은 배열을 쭉 돌아서 해당 값이 몇 개 있는 지 count만 하면 되기 때문이다.
sum 배열을 만드는 데 필요한 시간 역시 O(n)이다. 왜냐하면 count 배열을 앞에서부터 순회하여 앞에서 더한 값을 현재 값과 더해주기만 하면되기 때문이다.
그럼, sum배열과 count배열을 뒤부터 순회하여 값을 채우는 것은 얼마나 시간이 들까?? 이것도 O(n)이다. 결국 sum배열의 0이 나올 때까지 반복하게 되는데, sum배열의 count배열의 합이고, 이는 결국 n과 똑같다. 따라서 O(n)이다.
-
장점✨ :O(n) 의 시간복잡도
-
단점🧐: 배열 사이즈 N 만큼 돌 때, 증가시켜주는 Counting 배열의 크기가 큼.(메모리 낭비가 심함)
