
참고
QA셋을 구축한 뒤, 해당 QA셋에 대한 Precision/Recall/MRR을 계산하여 수치 지표를 비교하는 중이다.
해당 용어들에 대해 자주 헷갈리고, 확실한 정리가 필요할 것 같아 아래에 정리해보고자 한다.
🔎 용어 매핑
-
정답(golden answer)
- → QA 평가 셋에서 사람이 만든 정답 문장/근거 (현재는 GPT5로 구축해둔 상태)
- → 즉, “이 질문에 대해 올바른 답변은 여기 문서의 이 부분이다”라고 지정해둔 것.
-
검색 결과(search results)
- → 사용자 질문을 임베딩(embedding) 해서 벡터 DB(Milvus 등)에 넣고,
- → 코사인 유사도 같은 metric으로 가장 가까운 상위 k개의 청크(chunk)를 가져온 것.
- → 즉, golden answer가 들어 있는 문서를 검색해서 잘 찾아올 수 있는지 보는 단계
-
📊 검색 평가
- 생성한 3차 QA셋에 대하여 컬렉션별로 평가를 진행한다.
- 페이지
- ① 검색된 청크의
page_id또는page_range가 gold set이 속한 페이지 번호와 겹치는가?
- ① 검색된 청크의
- 내용
- ② 검색된 청크의
text내에 gold set의 정답 문장이 포함되어 있는가?
- ② 검색된 청크의
- 페이지 + 내용
- ①과 ②를 동시에 만족하는가? (가장 엄격한 평가 기준, “정답 문장을 맞는 위치에서 찾았는가”)
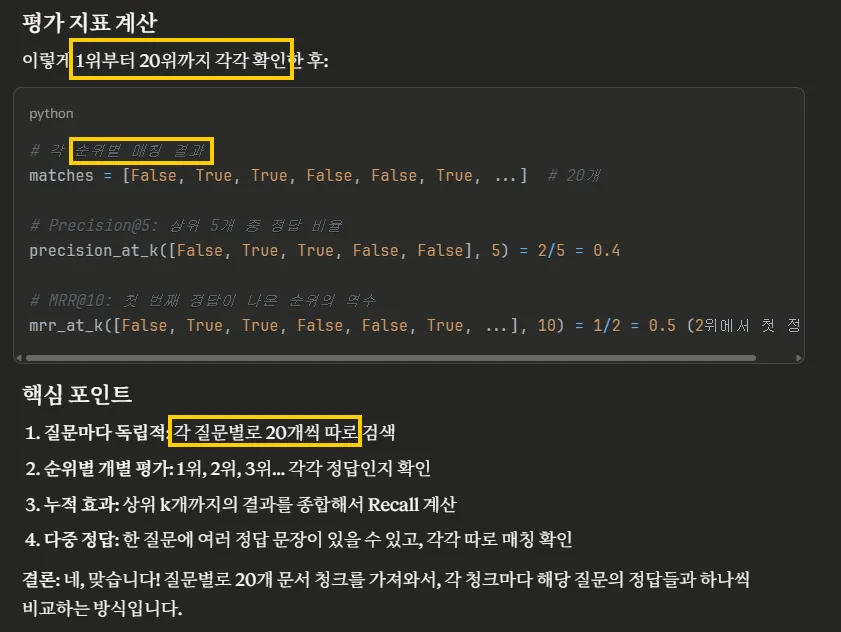
- 수치 지표: Precision, Recall, MRR @5/@10/@20 & AvgSim@10
- 종합적으로 수치들을 바라본 후, 최적의 컬렉션[청킹 방식]을 선택한다.
⭐ Recall

📌 Recall@k의 의미
recall@k는 검색된 청크 집합(top-k) 안에 golden answer가 포함되어 있는지 체크- 예:
- 질문: “서울시 주차정책의 문제점은?”
- golden answer: 보고서 28쪽~29쪽에 있는 문단
- 검색 top-5 청크: [p.10, p.27, p.28, p.30, p.45]
- → 여기서 p.28이 golden answer 범위에 포함되므로 hit = 1
=> 이걸 모든 질문에 대해 평균 내면 recall@k 값이 된다.
✅ 정리하면:
- 정답(golden answer) = 사람이 지정한 올바른 답변(문장/근거)
- 검색 결과 = 질문 임베딩 기반으로 벡터 검색된 top-k 청크들
- recall@k = golden answer가 top-k 청크에 포함된 비율
📌 해석 방법
recall@5 = 0.5793라는 것은:- 전체 질문(테스트 케이스) 중 약 57.93%에서 정답이 상위 5개 검색 결과 안에 포함되었다는 뜻
- 예를 들어 100개의 질문이 있다면, 그중 57~58개의 질문에서 정답이 top-5 안에 있었던 것.
- 개별 질문이 정답을 몇 개 포함했는지를 세서 평균 낸 값이 아니라, 정답 포함 여부를 0/1로 체크한 뒤 평균한 값
- 전체 질문(테스트 케이스) 중 약 57.93%에서 정답이 상위 5개 검색 결과 안에 포함되었다는 뜻
⭐ Precision

⭐ MRR

📚 정리
| 지표 | 초점 | 계산 단위 | 공식/정의 | 해석 포인트 |
|---|---|---|---|---|
| Recall@k | 포함 여부 | 질문 단위 | 정답이 top-k 안에 있으면 1, 없으면 0 → 평균 | 정답을 아예 못 찾는 케이스 비율 파악 |
| Precision@k | 비율 | 검색 결과 단위 | (top-k 중 정답 청크 개수) / k | 검색된 결과 중 정답의 “밀도” |
| MRR | 순위 | 질문 단위 | 첫 정답 위치의 역수 평균 | 정답이 얼마나 상위에 빨리 뜨는가 |
📚 예시


공부 기록용 & 프로젝트 회고용 24.08.05~ #AI/LLM #RAG