
벡터 DB에서 인덱싱·벡터·메트릭·검색은 어떻게 연결될까?
벡터 DB를 접하면 이런 의문이 생긴다.
- 인덱싱은 정확히 뭘 하는 걸까?
- 벡터는 왜 필요한가?
- 메트릭은 언제 쓰이는 건가?
- 검색할 때 실제로 어떤 기준으로 문서가 선택되는 걸까?
이 글에서는 문서 저장부터 검색 결과가 나올 때까지의 전체 흐름을
하나의 파이프라인으로 정리해본다.
1. 벡터 DB에서의 “문서”란 무엇인가?
먼저 용어부터 정리하자.
벡터 DB에서 문서(document)는 컬렉션에 저장된 하나의 row(entity)다.
예를 들어 Milvus 컬렉션에 아래와 같은 데이터가 있다면:
| id | text |
|---|---|
| 1 | 상품 추천 시스템을 개발하고 있습니다 |
| 2 | 결제 시스템 안정화 작업 |
| 3 | 추천 알고리즘 성능 개선 |
여기서
id=1이 하나의 문서id=2도 하나의 문서
즉, 파일 단위가 아니라 “행 단위”가 문서다.
2. 문서를 벡터로 바꾸는 이유
컴퓨터는 문장을 그대로 비교하지 못한다.
그래서 문서를 숫자 벡터로 변환한다.
대표적으로 두 가지 방식이 있다.
2-1. Dense Vector (의미 중심)
- 임베딩 모델(BERT, OpenAI embedding 등) 사용
- 문서 전체 의미를 고정 길이 벡터로 표현
"상품 추천 시스템"
→ [0.12, -0.44, 0.98, ...]👉 의미가 비슷한 문장은 벡터 공간에서도 가깝다.
2-2. Sparse Vector (키워드 중심)
- 문장을 토큰화
- 키워드별 중요도를 계산 (BM25 등)
- (키워드 : 가중치) 형태로 표현
"상품 추천 시스템"
→ {
"상품": 1.8,
"추천": 2.4,
"시스템": 3.1
}👉 정확한 키워드 매칭에 강하다.
- 스파스 벡터는 청킹된 각 데이터 행(row)마다 개별적으로 생성되지만, 그 가중치 계산에는 전체 청크 집합에서의 등장 빈도(IDF)가 반영된다.
Milvus의 BM25 Function은
- 컬렉션에 포함된 모든 텍스트 필드를 기준으로 IDF 통계를 구성하고,
- 각 데이터 행(row)의 텍스트에 대해 BM25 가중치를 계산하여 Sparse Vector를 생성한다.
- BM25에서 말하는 전체 문서(Corpus)는 모든 행의 토큰을 하나로 합친 텍스트가 아니라, 각 행을 하나의 문서로 간주해 구성한 문서 집합이며,
- IDF는 특정 토큰이 이 문서 집합 중 몇 개의 문서에 등장했는지를 기준으로 계산된다.
이 Sparse Vector는 전체 어휘 공간을 공유하지만,
- 실제로는 해당 행에 등장한 키워드 차원만 값을 가지는 희소 표현(one-hot vector ❌)
- 차원 수는 컬렉션별 텍스트 분포에 따라 달라질 수 있다
- 데이터 삽입 시점에 실행되어 각 문서의 Sparse Vector를 미리 계산하고 저장하며,
- 검색 시점에는 쿼리만 벡터화한 뒤 역색인 기반으로 공통 키워드의 가중치를 빠르게 합산해 점수를 산출한다.
3. Sparse Vector와 BM25의 관계
BM25는 검색 알고리즘이 아니라 점수 계산 공식이다.
역할 분담
- Sparse Vector: 키워드와 가중치를 담는 표현 방식
- BM25: 각 키워드의 중요도를 계산하는 수식
결과적으로 BM25의 출력값을 모아 만든 것이 Sparse Vector다.
4. 인덱싱이란 무엇인가?
인덱싱은 검색을 빠르게 하기 위해 미리 만드는 자료구조다.
저장을 위한 구조가 아니라, 검색을 위한 구조다.
4-1. 인덱싱은 누가 수행하며, 어디에 저장되고, 누가 들고오는가?
- Milvus에서 인덱스는 “원본 데이터와 분리되어, QueryNode가 접근 가능한 전용 스토리지에 저장”된다.
- 원본 데이터와 인덱스는 역할과 저장 위치가 분리되어 있다.
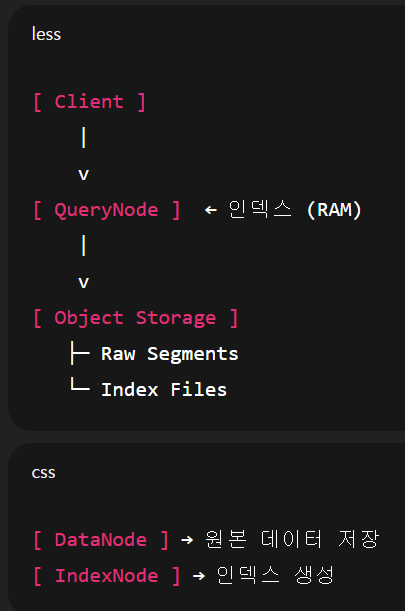
✅ 검색은 “메모리에 로드된 인덱스”로 수행
collection.load()호출- QueryNode가 인덱스 파일을 Object Storage에서 읽어 RAM에 로딩
- 이후 검색은 전부 메모리 기반
🔚 최종 한 문장 정리
Milvus에서 인덱스는
- IndexNode가 생성해 Object Storage에 저장되고,
- 검색 시 QueryNode가 이를 메모리에 로드해 사용한다.
- 원본 데이터와 인덱스는 역할과 저장 위치가 분리되어 있다.
📌 그래서: 인덱스 크기 = 메모리 사용량 -> 인덱스 설계가 매우 중요
4-2. Dense Vector 인덱싱
Dense Vector는 보통 근사 최근접 탐색(ANN) 인덱스를 사용한다.
대표적인 인덱스:
- HNSW
- IVF
- FLAT
예를 들어 HNSW는:
- 벡터를 그래프로 연결
- 검색 시 모든 벡터를 보지 않고
- “가까울 가능성이 높은 벡터만” 탐색한다
4-3. Sparse Vector 인덱싱 = 역색인
Sparse Vector는 역색인(Inverted Index) 구조를 사용한다.
정방향
문서1 → ["추천", "시스템"]
문서2 → ["결제", "시스템"]역색인
"추천" → [문서1]
"시스템" → [문서1, 문서2]
"결제" → [문서2]👉 “이 키워드가 들어 있는 문서가 무엇인가?”를 즉시 알 수 있다.
Milvus에서 BM25 기반 Sparse Vector의 IDF 통계는
- 인덱스 빌드 시점에 고정되며,
- 이후 새 데이터가 삽입되더라도 기존 문서의 IDF는 재계산되지 않고,
- 인덱스 리빌드 시에만 전체 문서 기준으로 다시 계산된다.
5. 메트릭(metric)은 언제 쓰일까?
메트릭은 두 벡터가 얼마나 비슷한지 계산하는 기준이다.
Dense Vector 메트릭
- Cosine Similarity
- Inner Product
- L2 Distance
Sparse Vector 메트릭
- BM25
- Inner Product (BM25 weight 기반)
📌 메트릭은 인덱스 위에서 점수를 계산할 때 사용된다.
| 구분 | Dense | Sparse |
|---|---|---|
| 기준 | 의미 | 키워드 |
| 매칭 | 전체 벡터 | 겹치는 토큰만 |
| 메트릭 | Cosine / IP | BM25 / IP |
| 강점 | 의미 유사 | 정확한 키워드 |
| 약점 | exact match 약함 | 의미 확장 약함 |
- Dense는 임베딩 벡터 간의 방향(의미)이 얼마나 비슷한지를 코사인 유사도로 계산하고,
👌
- 방향이 비슷할수록 점수 ↑
- 단어가 달라도 의미가 비슷하면 높은 점수
- Sparse는 키워드가 겹치는 문서만 대상으로 각 키워드의 BM25 가중치를 곱해 합산한 점수로 계산한다.
👌
- 겹치는 키워드가 많고, 그 키워드의 중요도가 클수록 점수 ↑
6. 검색 시 실제로 일어나는 과정
이제 전체 흐름을 하나로 묶어보자.
6-1. 문서 저장 시
-
문서 텍스트 입력
-
토큰화 또는 임베딩
-
Dense Vector / Sparse Vector 생성
-
벡터 저장
-
인덱싱 수행
- Dense → ANN 인덱스
- Sparse → 역색인
6-2. 사용자 쿼리 입력 시
예시 쿼리:
"추천 시스템 개발"- 쿼리도 동일한 방식으로 벡터화
- 쿼리 벡터를 기준으로 검색 수행
- 인덱스를 통해 후보 문서 선택
- 메트릭으로 점수 계산
- 점수 기준으로 top_k 문서 반환
7. Sparse Vector 검색에서 “매칭”이란?
Sparse 검색에서의 매칭 조건은 단순하다.
쿼리 키워드와 문서 키워드가 겹쳐야 한다.
예:
- 쿼리:
["추천", "시스템"] - 문서1:
["추천", "시스템"]→ 매칭 ⭕ - 문서2:
["결제", "시스템"]→ 부분 매칭 ⭕ - 문서3:
["배송"]→ 매칭 ❌
그 다음 단계에서:
- 가중치(BM25)가 클수록 점수 상승
- 점수가 높은 문서만 top_k에 포함
8. Dense + Sparse Hybrid 검색
실무에서는 보통 둘을 같이 쓴다.
- Sparse: 키워드 정확성
- Dense: 의미 유사성
최종 점수 =
α × Dense score +
β × Sparse score👉 RAG, 검색, 추천 시스템의 표준 구조
9. 전체 흐름 한 문장 요약
벡터 DB의 검색은
✅ 문서를 벡터로 변환하고,
✅ 검색에 최적화된 인덱스를 만들고,
✅ 쿼리를 같은 공간으로 변환한 뒤,
✅ 메트릭으로 유사도를 계산해
✅ 가장 점수가 높은 문서를 반환하는 과정이다.
마무리
인덱싱, 벡터, 메트릭, 검색은
각각 독립적인 개념처럼 보이지만
사실은 하나의 검색 파이프라인을 이루는 톱니바퀴다.
RAG에서의 전체 흐름
- 컬렉션 생성 후
- 검색 대상 필드와 인덱스·메트릭을 설정하고 데이터를 저장한 다음,
- 사용자 쿼리를 동일한 벡터 공간으로 변환해 인덱스를 통해 후보를 탐색하고
- 메트릭 점수 기준으로 top_k 문서를 선별해 응답한다.
메트락 계산 시
- Dense 검색은 임베딩 벡터 간 코사인 유사도로 의미적 근접성을 계산하고,
- Sparse 검색은 키워드가 겹치는 문서만 대상으로 BM25 가중치를 곱해 합산한 점수로 순위를 매긴다.
- RRF는 Dense 검색과 Sparse 검색에서 각각 매긴 “순위”를 점수로 변환해 합산한 뒤, 종합 순위를 다시 매겨 top_k를 선택하는 방식이다.
