Kafka Streams 분석 내용
개요
• Stream Processing은 데이터들이 지속적으로 유입되고 나가는 과정에서 이 데이터에 대한 일련의 처리 혹은 분석을 수행하는 것을 의미한다.
• Kafka Streams는 Kafka Streams API를 사용하여 Kafka에 저장된 데이터를 처리하고 분석하기 위해 개발된 클라이언트 라이브러리이다.
• Kafka에서 제공하는 본래의 기능들을 모두 활용함으로써 간단하게 핵심 기능을 개발할 수 있고 매우 가볍
• 직관적인 DSL을 사용하여 프로세싱 토폴로지를 정의할 수 있다.
• Java, Scala 지원한다.
1) 단순 라이브러리, 실행 프레임워크가 아니기 때문에 사용자가 수동으로 구동해야 함
2) 특정 프레임워크에 탑재하여 실행할지 public static void main()을 쓸지 여부는 전적으로 개발자가 결정
다.
특징
• 레코드별 Stream 처리를 밀리세컨드 latency로 지원
• Stateless 프로세싱, Stateful 프로세싱, Windowing 연산을 지원
• Java 어플리케이션 코드를 작성하고 실시간으로 마이크로 서비스를 처리할 수 있음
• Scalable, Fault-tolerant
Stream Processing의 장점
- 이벤트에 즉각적으로 반응한다. 이벤트 발생 후 조치까지 지연시간이 거의 없으며 분석은 항상 최신의 데이터를 반영한다.
- 정적 분석보다 더 많은 데이터를 분석한다. (저장 후 분석하지 않는다.)
- 지속적으로 유입되는 데이터 분석에 최적화된다.
- 대규모 공유 데이터베이스에 대한 요구를 줄일 수 있어 인프라에 독립적으로 수행할 수 있다.
카프카 스트림즈는 사용자 앱에서 라이브러리를 사용하고 원하는 만큼 앱 인스턴스를 시작하면 kafka는 이러한 인스턴스에 대해 작업을 분할하고 균형을 유지한다. (프레임워크가 필요없다.)
더 자세히 보자면
- Kafka Streams는 스트림 처리 클러스터 없이 kafka와 나의 애플리케이션만 포함하는 완전히 내장된 라이브러리로 개발한다.
- 상태 테이블의 개념을 이벤트 스트림과 완전히 통합하고 이 두가지를 단일 개념 프레임워크에서 사용할 수 있도록 한다.
- 스트림 아키텍처에서 움직이는 조각의 총 수를 줄이기 위해 Kafka가 제공하는 핵심 추상화와 완전히 연결된 처리 모델을 제공한다.
Task는 Kafka Consumer의 fault-tolerant 기능을 활용하여 오류를 처리한다.
아키텍처
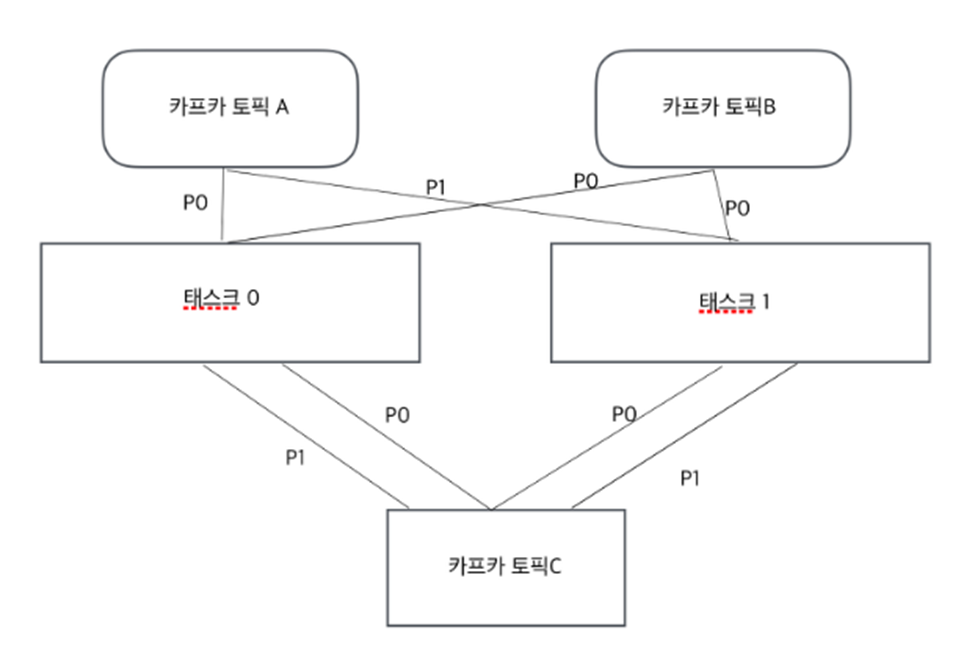
- Kafka Streams에 들어오는 데이터는 카프카 토픽의 메시지이다.
- 각 스트림 파티션은 카프카의 토픽 파티션에 저장된 정렬된 메시지이고, 해당 메시지는 key-value형태이다.
- 또한 해당 메시지의 키를 통해 다음 스트림(카프카 토픽)으로 전달된다.
- 위의 그림에서 보듯 Kafka Streams는 입력 스트림의 파티션 개수만큼 태스크를 생성한다.
- 각 태스크에는 입력 스트림(카프카 토픽) 파티션들이 할당되고, 이것은 한번 정해지면 입력 토픽의 파티션에 변화가 생기지 않는 한 변하지 않는다.
- 마치 컨슈머 그룹 안의 컨슈머들이 각각 토픽 파티션을 점유하는 것과 비슷한 개념이다.
프로세서 토폴로지
• 토폴로지는 어플리케이션의 스트림 프로세싱 계산 로직을 정의, 즉 입력 데이터를 출력데이터로 변환하는 방법
용어

예제
WordCount 예제 package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WordCount {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
// "streams-plaintext-input" 토픽을 데이터 Input으로 설정
KStream<String, String> source = builder.stream("streams-plaintext-input");
// 데이터를 Split하고 단어별로 GroupBy, Count
// "streams-wordcount-output" 토픽에 결과 저장
source.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
.........
streams.start();
}
}Serving 연동 아키텍처
1) 임베디드 모델을 사용한 스트림 처리
• Kafka Streams Application내에 ML 모델을 포함하는 방법
-Inference 요청에 대해 리모트보다 Latency가 좋음
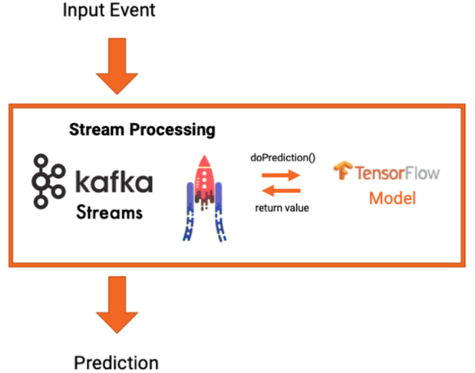
• Kafka Streams Application내에 모델 Inference 기능을 같이 구현할 경우
-KFServing 같은 추론 도구(Serving, Model관리, Monitoring등)를 구현해야 한다.
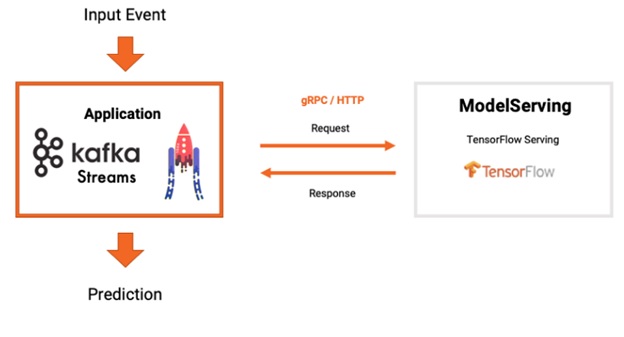
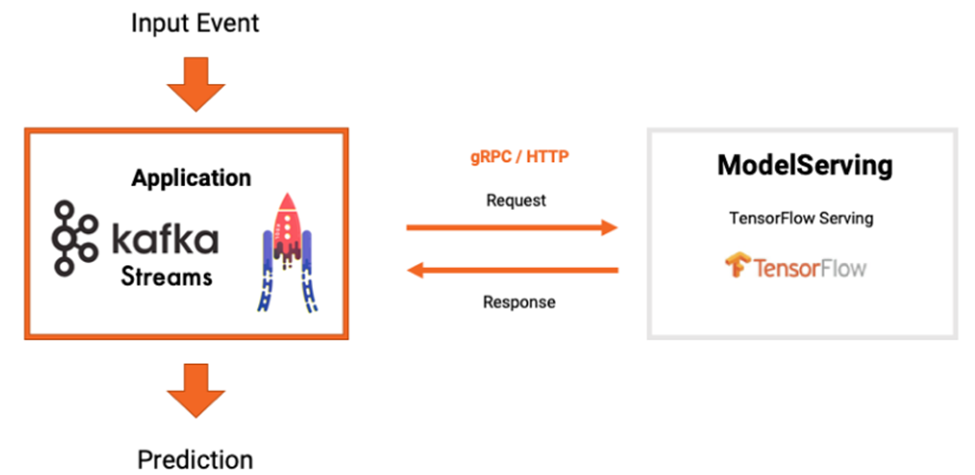
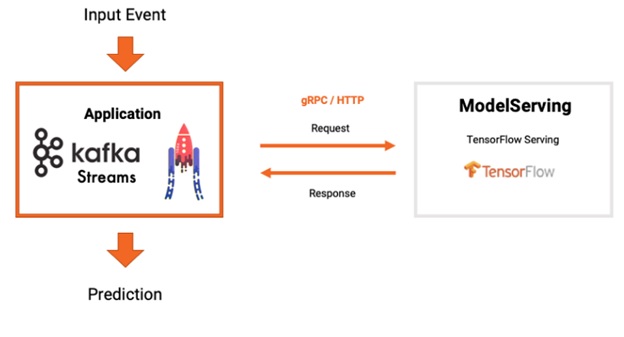
2) 모델 서버 및 RPC를 사용한 스트림 처리
• Kafka Streams Application에서 Topic의 데이터를 조회해 Serving 서비스로 Prediction 요청
• Kafka Application이 Prediction 결과를 Serving 서비스로부터 전송받아 Topic에 저장
• 장점
o 모델 버전관리, A/B 테스트등 Serving 서비스의 기능을 그대로 사용할 수 있다.
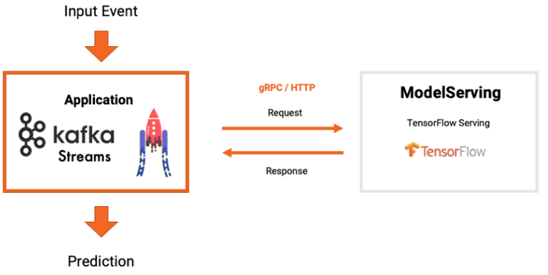
• Kafka Streams와 KFServing을 연동할 경우
-Kafka Streams에서 Kafka 토픽의 데이터 조회 후 KFServing에 Predict 요청
-요청 결과를 다시 Kafka Streams를 통해 Kafka 결과 토픽에 저장
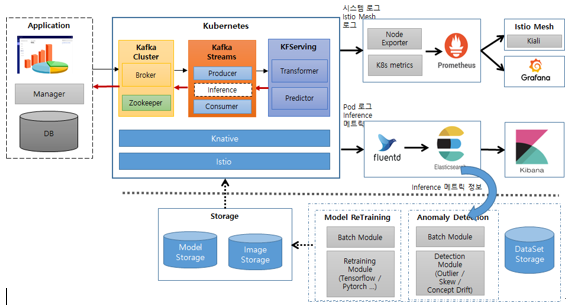
참고
https://engineering.linecorp.com/ko/blog/applying-kafka-streams-for-internal-message-delivery-pipeline/
https://docs.confluent.io/current/streams/architecture.html#streams-architecture
http://www.kwangsiklee.com/2020/03/kafka-stream-api%EB%9E%80/
https://kafka.apache.org/26/documentation/streams/tutorial
https://coding-start.tistory.com/138
https://gunju-ko.github.io/kafka/kafka-stream/2018/04/28/KafkaStream-Architecture.html
