예전에 공부했던 KFServing v0.4에 대해 정리해 본다.
지금은 버전업데이트 되어서 이름이 KFServe로 이름이 바뀌고 Kubeflow 프로젝트에서 떨어져 독립 프로젝트로 된거 같다.
개요
Kubeflow 프로젝트의 일부로 K8s에서 inference를 지원하는 serving 도구
기능
- 오토스케일링, 네트워킹, 헬스체크, 모델 배포(canary rollout)등
- 모델에 대한 prediction, processing, explanation 제공
Model Server
- TensorFlow
- Nvidia TRTIS
- PyTorch
- XGBoost
- SKLearn
- ONNX
Storages
- AWS/S3
- GCS
- Azure Blob
- PVC
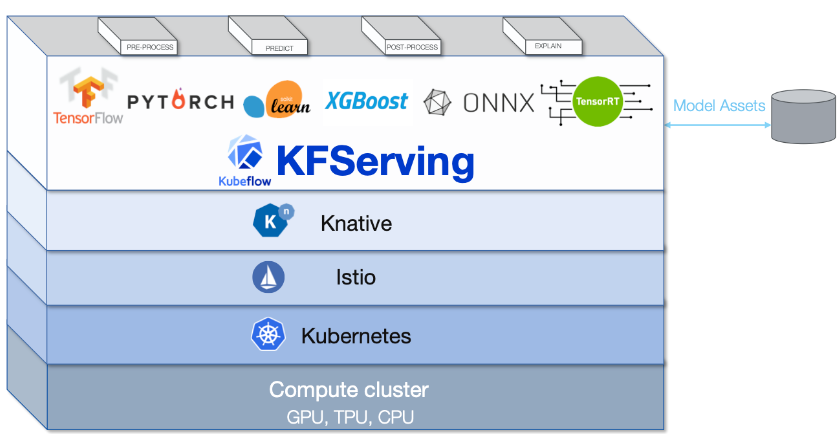
KFServing Stack
Kubeflow와 함께 설치되지만 별도로 설치할 수 있다.
KFServing은 Auto-scaling, canary rollout을 위해 Knative와
Traffic routing과 ingress를 위해 Istio가 필요하다.
1) Knative
서버리스(serverless) application을 빌드, 배포, 관리하기 위해 K8s 기반 플랫폼
*서버리스는 개발자가 서버를 관리할 필요 없이 어플리케이션을 빌드하고 실행할 수 있도록 하는 클라우드 네이티브 모델을 말함
Knative는 크게 Serving과 Eventing 2개의 기능이 있다.
Serving
컨테이너의 신속한 배치, 오토 스케일링, 복잡한 배포(rolling/canary)등을 지원
Istio를 백엔드로 Knative 서비스를 라우팅
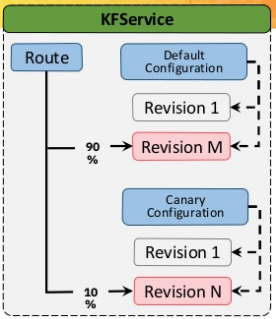
- Configuration
Knative Serving으로 배포되는 서비스를 정의
컨테이너 경로, 빌드 설정, 환경변수, 오토스케일링 설정등을 정의
Configuration에 정의된 빌드 설정을 통해서 새로운 컨테이너를 빌드해서 배포할 수도 있음
KFServing에서 기본적으로 default, canary Configuration을 정의 - Revision
코드와 Configuration의 snapshot
Configuration을 생성할때마다 새로운 Revision 생성
이전 Revision으로 rollback하거나 저장된 다른 버전으로 트래픽을 분할해서 serving할 수도 있음 - Route
서비스로 들어오는 트래픽을 Revision으로 라우팅하는 역할
최신버전의 Revision으로 라우팅하거나 Canary 테스트와 같이 여러 Revision으로 라우팅할 수도 있음
Eventing
다양한 이벤트 소스로 부터 이벤트를 받아 처리할 수 있는 메세지 처리 모듈
이벤트 소스(구글 클라우드 pub/sub, AWS SQS, cronjob, websocket)
브로커(버킷), 채널(Kafka, NATS), 이벤트 Trigger 기능이 있다.
2) Istio
마이크로서비스를 서로 연결, 관리, 보안기능을 제공하는 오프소스 플랫폼
주요 기능
- 트래픽 라우팅, 분할(Canary 테스트)
- 서비스 헬스체크, 디스커버리
- 요청 retry, timeout
- 트래픽 보안, 서비스 간 인증
- 모니터링
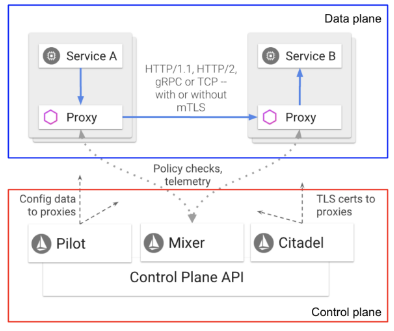
논리적으로 data plane과 control plane으로 나뉨
Data plane
마이크로서비스 사이의 네트워크 통신을 조정하고 제어
서비스 pod에 Envoy Proxy를 사이드카 형식으로 배포하고 서비스로 들어오고 나가는 트래픽을 통제
Knative는 Envoy를 감싸서 만들어 졌다.
- Envoy
C++로 개발된 프록시로 모든 서비스에 대한 in/outbound 트래픽을 관리
서비스 discovery, 로드 밸런싱, TLS 인증서 처리, HTTP/2, gRPC 프록시, 헬스 체크
Control plane
Data plane에 배포된 Envoy를 컨트롤 하는 부분
Pilot, Mixer, Citadel로 구성
- Pilot
서비스 Endpoint 주소들을 관리(서비스 discovery 제공)
서비스간 트래픽 경로 컨트롤
서비스 안정성 제공(timeout, retry) - Mixer
Access 컨트롤, 정책 통제
ex. 서비스의 총 처리량을 지정하여 일정 이상의 요청은 거절하게 함, 특정 헤더값이 일치해야 요청을 받을 수 있게 함
모니터링 지표 수집
응답시간, 평균 처리량등의 지표 수집 - Citadel
보안 담당 모듈
서비스 사용을 위한 Authentication, Authorization
통신 암호화(TLS/SSL), 인증서 관리
구성도
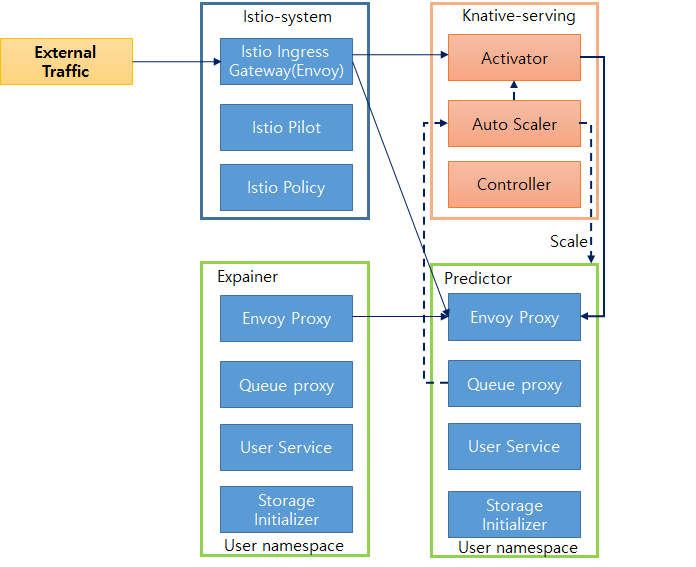
InferenceService 구성도
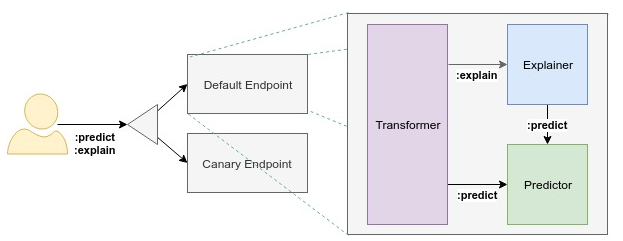
Endpoint
InferenceService는 2개의 endpoint를 가짐(Default, Canary)
Canary endpoint는 옵션
Predictor
InferenceService의 핵심
단순히 모델이자 모델 서버
Explainer
Model explanation을 제공
KFServing은 Alibi 같은 explainer를 제공
Transformer
Prediction과 explanation 워크플로우 전에 pre and post processing 기능
주요 기능
1) Autoscaling
Inference 서비스의 동시 요청수에 따른 서비스 scaling 기능
Kubernetes에서 지원(HPA)되는 기능 이외에 Knative(KPA)에서 지원되는 기능도 포함된다.
Knative에서는 대표적으로 gpu, concurrency 요청 기반으로 Autoscalin을 할 수 있다.
Pod당 동시 request의 평균을 1로 설정(default), 그 이상 들어오면 Pod를 늘림
ex) 5 concurrent requests, try to scaling up 5 Pods
"autoscaling.knative.dev/target" : target concurrency
2) Custom Model
KFserving 인터페이스를 상속받아 사용자 모델을 정의한 후 KFserving에 배포할 수 있다.
사용자가 커스텀하게 모델서빙을 하기 위해 사용한다.
모델 프레임워크와 KFServing 인터페이스 구현체를 모두 작성해서 Dockerfile로 생성해 배포한다.
3) Logging
추론에 대한 Request, response 로깅 제공
EFK(Elasticsearch - Fluent - Kibana) 구축해서 수집 가능
