기본적으로 통계에서 사용하는 추정은 당연히 data기반 입니다. ( 가설 검정도 마찬가지 )
즉, data given ( 표본집단 ) -> find parameter ( 모집단 )
Likelihood function
가능도 함수라고 합니다. X∼f(x;θ)라는 확륜변수가 있다고 하겠습니다. 이때 θ는 parameter입니다.
그리고 (X1,X2,⋯,Xn)∼X라고 하겠습니다.
그러면 가능도 함수를 다음과 같이 정의합니다. L(θ)=f(X1,X2,⋯,Xn∣θ) 이때 f는 확률변수 X의 pdf이므로 X1,X2,⋯,Xn가 변수입니다. 하지만 이때 observed data x1,x2,⋯,xn를 넣어서 L(θ)=f(x1,x2,⋯,xn∣θ)를 만들어 준다면 θ만이 변수가 됩니다.
즉, L(θ)=f(θ∣x1,x2,⋯,xn)라고 다시 쓸 수 있습니다. 또한 iid이므로 L(θ)=∏if(xi)θ가 됩니다.
즉, 이제 우리는 θ=θargmaxL(θ)을 구할 수 있습니다.
이때 보통 log를 이용하여 L∗(θ)=logL(θ)=∑ilogfθ(xi)으로 나타내 계산합니다.
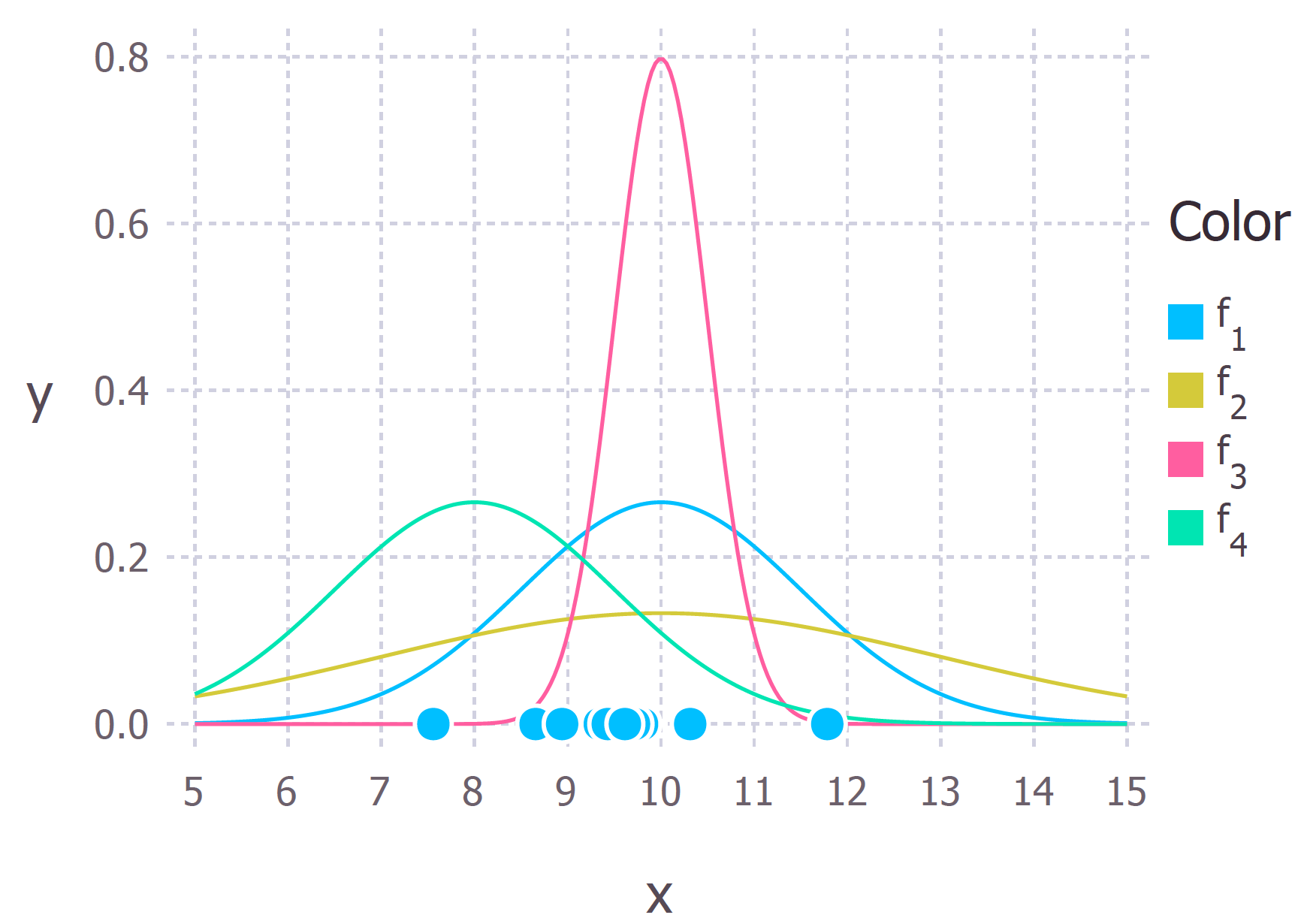
위의 처럼 joint pdf로 하는것이 맞지만 이해가 안된다면 다음과 같이 이해해도 됩니다. f(x)는 분포의 높이입니다. 즉, 여러개의 f(x)의 곱이 최대가 되려면 f의 모양 ( 분포 )는 x들이 가장 나올법한 모양이어야 합니다.
이 그림을 보면 직관적으로 이해가 됩니다.

.png)