상품 "몰스킨" 검색, 쇼핑 정보 취득과정
1. gen_search_url()
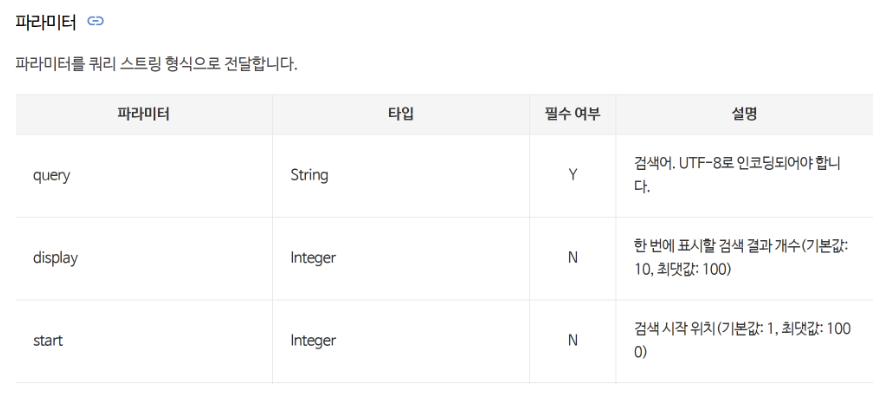
- 검색 요청 URL 생성하는 함수
- 파라미터들을 URL에 포함시켜야 함
- 한번에 표시될 수 있는 검색 결과(display)의 최대 수 - 100개
- 만약 1000개의 데이터 얻고자 하면 start 파라미터 이용해 시작갑 start = 1, start = 101,..., start = 901 방식으로 분리해 지정
import urllib
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
gen_search_url("shop", "Test", 10, 3)
// 'https://openapi.naver.com/v1/search/shop.json?query=Test&start=10&display=3'get_result_onepage()
- url로 웹에 접근해 내용을 json으로 가져와 글자로 decode 해 줌
import json
import datetime
from urllib.request import Request, urlopen
def get_result_onepage(url):
client_id = "*************"
client_secret = "******"
request = Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urlopen(request)
print("[%s] URL Request Success" % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))
url = gen_search_url("shop", "몰스킨", 1, 5)
one_result = get_result_onepage(url)
one_result<결과>
3. get_fields()
- 검색 정보를 pandas DataFrame으로 만듬
import pandas as pd
def get_fields(json_data):
title = [each["title"] for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mall_name = [each["mallName"] for each in json_data["items"]]
# title / lprice / link / mall이 디스플레이됨
result_df = pd.DataFrame({
"title": title,
"lprice": lprice,
"link": link,
"mall": mall_name,
})
return result_df
get_fields(one_result)4. delete_tag()
title 부분 텍스트에 붙어 있는 태그 제거
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>", "")
return input_str
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mall_name = [each["mallName"] for each in json_data["items"]]
result_df = pd.DataFrame({
"title": title,
"lprice": lprice,
"link": link,
"mall": mall_name,
})
return result_df
get_fields(one_result)5. actMain()
지금까지 과정을 통해 1000개의 데이터를 모두 모음
def actMain(api_node, search_text):
total_result = []
# 1부터 1000까지 100개씩
for n in range(1, 1000, 100):
url = gen_search_url(api_node, search_text, n, 100)
json_result = get_result_onepage(url)
df_result = get_fields(json_result)
total_result.append(df_result)
total_result = pd.concat(total_result)
return total_result
result_molskin = actMain("shop", "몰스킨")
result_molskin6. EXCEL로 저장
- 파이썬으로 엑셀을 다루는 xlsxwriter 모듈 이용해 데이터 저장
writer = pd.ExcelWriter(
"./result_data/06_molskin_diary_in_naver_shop.xlsx",
engine="xlsxwriter"
)
result_molskin.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
worksheet.set_column("A:A", 4)
worksheet.set_column("B:B", 70)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 50)
worksheet.set_column("E:E", 30)
worksheet.set_column("F:F", 10)
worksheet.conditional_format("C2:C1001", {"type": "3_color_scale"})
writer.close()7. 시각화
- 몰스킨 제품이 팔리는 쇼핑몰 별로 보여줌
plt.figure(figsize=(15, 7))
sns.countplot(
data=result_molskin,
x=result_molskin["mall"],
palette="RdYlGn",
order=result_molskin["mall"].value_counts().index
)
plt.xticks(rotation=90)
plt.show()
Data Science 스터디로그