AE -> VAE -> AAE
정의에서 부터 어떤 특징(장단점)이 있고 어떤 식으로 모델이 발전해 나가는 지 파악해보자.
Auto Encoders
- 정의
입력과 출력이 동일한 형태를 가지는 신경망이며 차원 축소를 목적으로 feature detection, classification을 비지도 학습의 형태로 학습하는 신경망입니다.
비지도 학습이므로 라벨이 없이 데이터만 주어진 상황에서 학습한다.
목적: Encoder가 Latent Feature를 뽑아내기 위함.
Encoder, Decoder, Latent Feature로 이루어져있습니다.
Decoder는 latent feature가 제대로 추출되었는 지 확인하는 역할을 하고 backpropagation으로 검사 및 확인합니다.
latent feature는 신경망 내부에서 추출된 특징적 값들입니다.
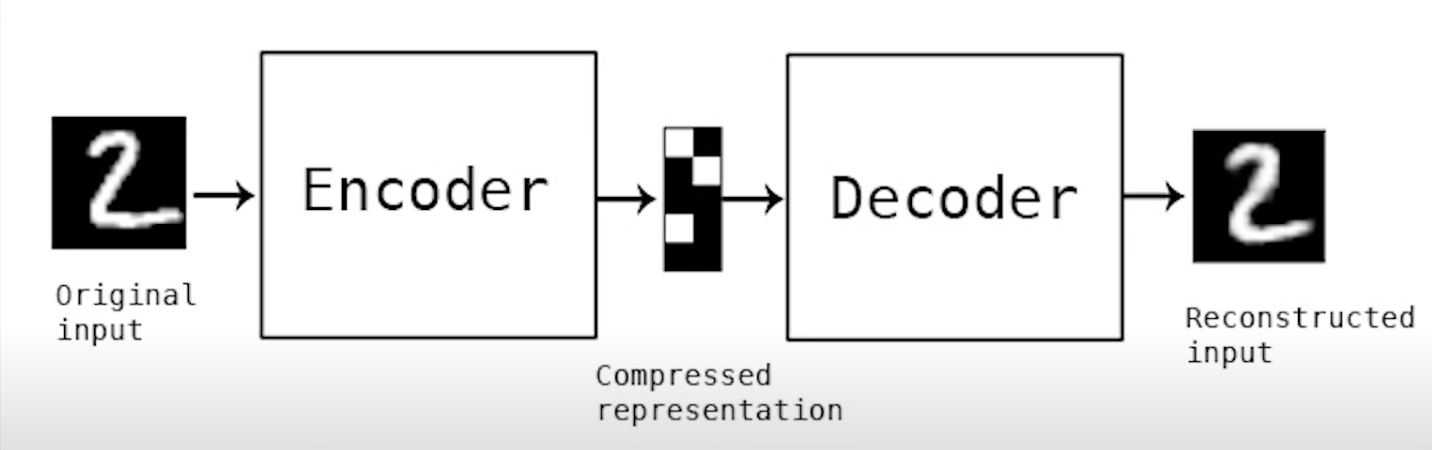
- 차원을 축소하는 것이 일반적으로 학습에 도움이 되는 이유
차원의 저주?
고차원 공간의 데이터를 분석하거나 측정할 때 저차원 공간에서는 나타나지 않았던 여러 문제들이 발생하는 것을 말합니다.
특징 방향, 방향성을 예측하기 어려움.

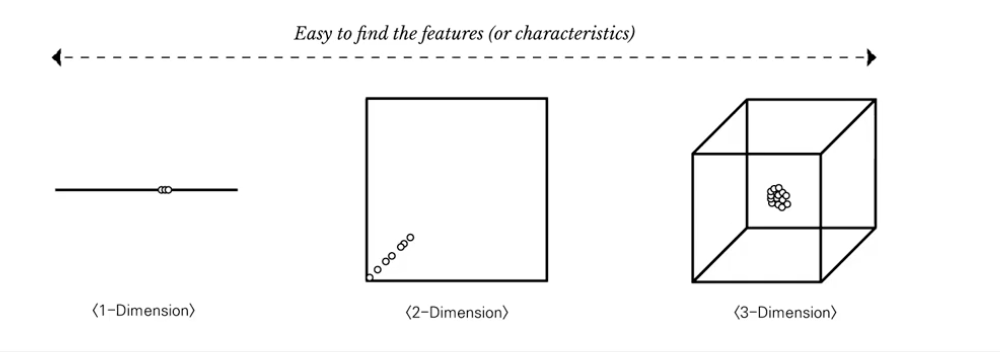
- 차원 축소 해도 문제가 없나?
손실은 있을 수 있지만 복원할 수 있다는 것은 Latent Vector가 많은 정보를 잘 담고있음을 보여줄 수 있다.
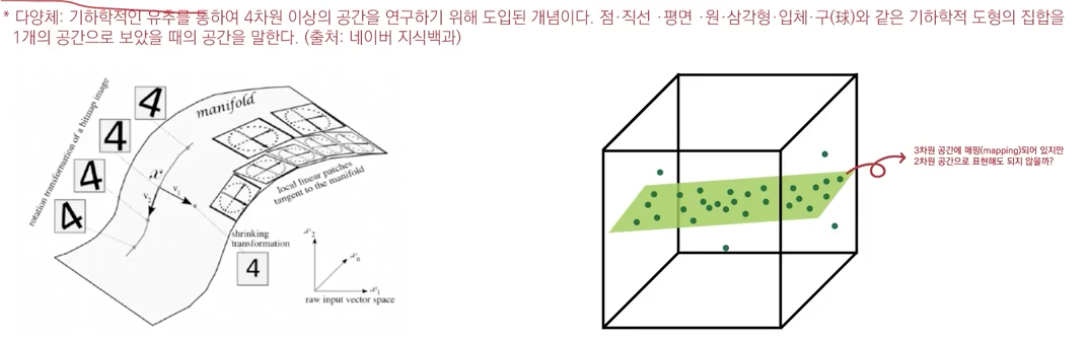
- Manifold Hypothesis
sparse한 고차원 데이터를 간추려서 보다 저차원 공간으로 나타낼수 있다.
SPARSE implies a thin scattering of units.
manifold: 다차원 데이터에서 실질적으로 의미를 가지는 특징을 모아둔 조밀한 특성공간을 뜻하며, 실제 데이터를 통해 스스로 학습하는 딥러닝 비지도 학습이 이러한 manifold를 스스로 찾아냅니다.
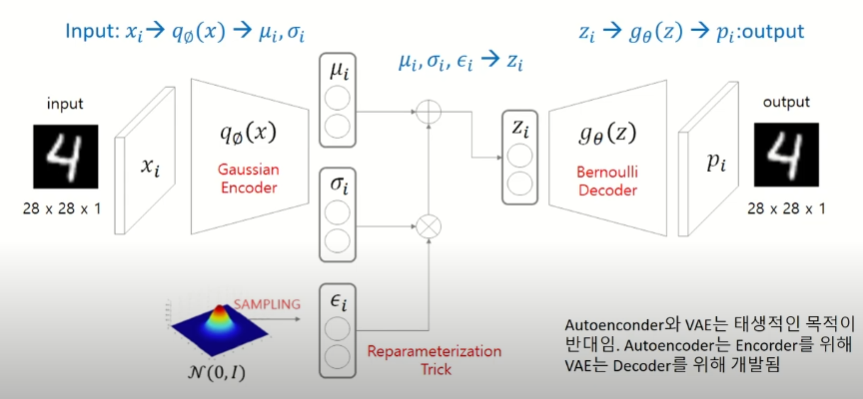
Variational Auto Encoder
목적: Decoder로 새로운 데이터를 생성하기 위해서 개발된 모델이다.
- 구조
인코더는 평균과 표준편차를 변환한다.
평균과 표준편차로 부터 정규분포를 만들고 이를 활용해서 데이터를 샘플링해서 z를 만든다.
z가 디코더를 통과하면 입력과 동일한 출력을 복원한다.
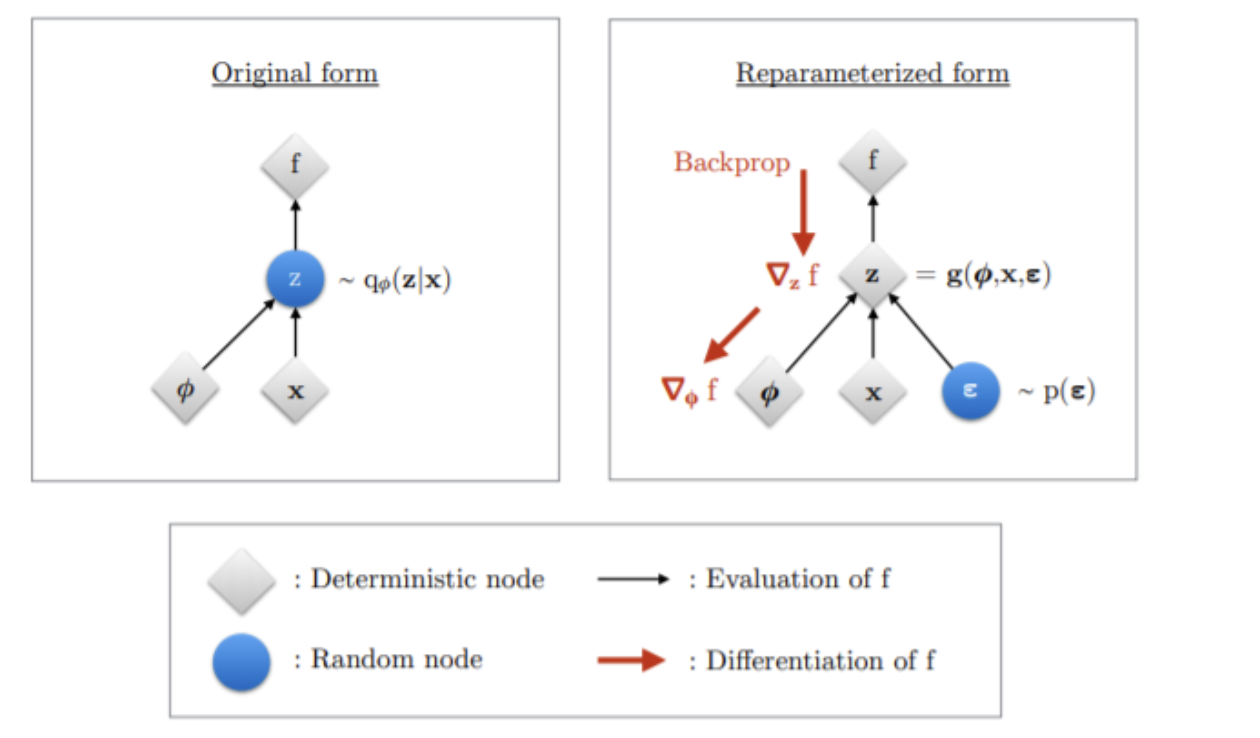
Reparameterization Trick:
간단히 말하자면, Backpropagation, 정규분포는 미분 불가능한데 이를 가능하게 해주는 기법.
ϵ을 N(0,1)에서 샘플링해서 std에 곱해주고 mean과 더해주는 방법으로 샘플링을 직접 하는 것을 막는 방법이다. 이것을 사용하지 않으면 출력된 mean과 std에 대한 가우시안 분포에서 직접 샘플링을 해야 하는데 그렇게 되면 deterministic하지 않기 때문에 역전파가 불가하다.
최소화해야하는 Loss Function은 아래 두 가지의 합으로 나타난다.
1. Reconstrution Error의 식은 output이 베르누이 확률을 따른다고 가정하면 cross entropy식으로 나타낼 수 있다.
2. Regularization 식은 인코더를 통과한 확률이 우리가 가정한 정규분포에 가까워질 수 있도록 KL divergence를 최소화하기 위한 식으로 나타낼 수 있다.
- VAE의 특징
Decoder가 최소한 학습 데이터는 생성해 낼 수 있게 된다.
Encoder가 최소한 학습 데이터는 잘 latent vector로 표현할 수 있게 된다.
-> 현재는 GAN이 나오면서 VAE는 인코더의 역할로 사용된다.
Adversarial Auto Encoder
최적화란?
KL의 qΦ를 p(z)의 차이를 최소화하여 같아지게 만드는 것을 말한다.
KL Divergence의 최적화 방식이 GAN의 학습방법과 동일하다.GAN에서 Traget distribution이 있을 때 generation의 분포가 target distribution과 같게 만들어주는 방식과 KL term의 학습방법이 같기 때문에 이를 GAN으로 대체하는 방법이 바로 AAE(Adversarial AutoEncoder)입니다.
P(prior)에서 만든 sample은 진짜 sample입니다.
q(GAN)에서 만든 sample은 가짜 sample입니다.
Discriminator에게 이상적인 sampling함수에서 생성된 값이 prior에 가깝게 요청한다.

참고자료
https://www.youtube.com/watch?v=Rdpbnd0pCiI
https://www.youtube.com/watch?v=YxtzQbe2UaE&t=253s
https://www.youtube.com/watch?v=GbCAwVVKaHY
VAE와 AAE의 차이 blog
AAE논문
VAE논문
GAN논문
Reparametrization
KL divergence
Manifold Hypothesis
