CARD: Channel Aligned Robust Blend Transformer for Time Series Forecasting (24.04 ICLR) Paper Review
CARD(Channel Aligned Robust Blend Transformer)는 시계열 예측을 위한 특별한 transformer 모델
CI (Channel-Independent) 방식 Transforemer의 주요 단점 해결하고자 설계 (new robust loss function 중요)
Multi-Channel 즉, Multivariate Time series task에 적용시킨다면 매우 유용할 것으로 보여짐
- 관련 코드 https://github.com/wxie9/CARD
- 관련 논문 CARD: Channel Aligned Robust Blend Transformer for Time Series...
0. Background
Channel-Independent Strategy
- CI 전략, 시계열 예측에서 훈련의 안정성 높이기 위한 각 채널(변수)을 독립적으로 처리
- 즉, 각 채널(feature)들을 개별적으로 예측
- 장점
- train 단계에서, 모델의 robustness 향상
- 특정 채널의 noise나 anomaly 다른 채널에 미치는 영향 줄임
- overfitting risk 줄어듬
- train 단계에서, 모델의 robustness 향상
- 단점
- 채널 간의 상관관계 아예 무시 (critical)
- real time-series data에서는 변수들 사이에 서로 영향 주고받는 경우 多
1. Introduction
-
Channel-Dependent (CD) 방식으로 다변량 시계열 예측에서 서로 다른 변수 간의 상호 의존성을 고려하여 예측 성능을 높이지만, 최근 연구에서 일반적으로 CI이 CD보다 성능이 더 좋다는 것을 입증함. (시계열 데이터 특성상, 변수 간의 의존성이 복잡하기에 노이즈가 많으므로, 오히려 CD 모델에서 overfitting 가능성이 매우 높음.)
-
CARD 모델은 채널 간의 의존성을 활용하면서, 과적합 문제를 줄이는 새로운 Transformer 모델
- Channel Aligned Attention map: 시간적 상관관계와 채널 간의 동적 의존성 모두 포착
- 예측 변수(채널) 간의 상관관계 파악 (채널 간 attention)
- 각 토큰 내의 local information align (Hidden Dimension Attention)
- Token Blend Module: 다양한 resolution의 token 생성, Multi-Scale 지식을 효율적으로 활용
- Mutil-head Attention에서 동일한 위치의 토큰을 다른 head에 걸쳐 병합하는 대신, 동일한 head 내에서 인접한 토큰을 결합하여 새로운 토큰 생성
- Robust Loss Function: 예측 불확실성 기반, 예측 중요도를 가중하여 과적합 문제 완화
- 과적합 측면에서 기존 query, key token에 Exponential Smoothing 적용시, 더 나은 성능을 보인, ETSformer 연구를 활용함
- 모든 차원에 대해 동일하게 유지되는 고정된 EMA 파라미터를 사용하는 것으로 충분히 훈련 과정을 안정화할 수 있음을 발견
즉, 학습 가능한 파라미터를 포함하지 않는 EMA를 사용하여도 충분한 효과를 얻을 수 있다는 점을 제시하고 있음.
- 모든 차원에 대해 동일하게 유지되는 고정된 EMA 파라미터를 사용하는 것으로 충분히 훈련 과정을 안정화할 수 있음을 발견
- 과적합 측면에서 기존 query, key token에 Exponential Smoothing 적용시, 더 나은 성능을 보인, ETSformer 연구를 활용함
- Channel Aligned Attention map: 시간적 상관관계와 채널 간의 동적 의존성 모두 포착
2. Related Work
- Transformers for time-series forecast
- LogTrans
- Informer
- AutoFormer
- FEDformer
- Pyraformer
- PatchTST
- Crossformer
- RNN, MLP, CNN for time-series forecasting
3. Model Architecture
-
The architecture of CARD
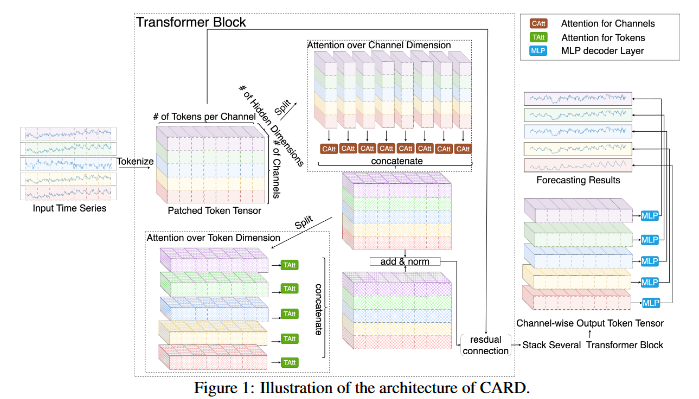
-
Input
time-series data
-
Tokenize
시계열 데이터 작은 patch 단위로 나눠서 이를 토큰으로 처리
이 때, 각 채널별로 독립적으로 처리
여기서 토큰화된 데이터는 "패치된 토큰 텐서"라는 형태로 표현
이 텐서는 여러 채널(Channels), 즉 여러 변수에 대한 시계열 정보 포함
- 최종 input size 설명
- 필요한 요소들
-
채널 수 (C)
다변량 시계열 데이터의 변수 개수를 의미합니다. 각 변수는 독립적인 시계열 데이터를 나타냅니다 (예: 온도, 습도, 압력).
-
패치 길이 (P)
각 토큰이 포함하는 시계열 데이터 포인트의 개수를 의미합니다. 예를 들어, 패치 길이가 16이면 각 토큰은 16개의 연속적인 데이터 포인트를 포함합니다.
-
스트라이드 (S)
토큰을 생성할 때, 각 토큰이 이전 토큰에서 얼마나 이동하는지를 나타냅니다. 스트라이드가 작을수록 토큰 간에 겹치는 부분이 많아집니다.
-
입력 시퀀스 길이 (L)
모델에 입력되는 전체 시계열 데이터의 길이를 의미합니다. 예를 들어, 96시간 동안의 데이터를 입력으로 사용한다면 입력 시퀀스 길이는 96이 됩니다.
-
히든 차원 (d)
토큰이 dense MLP layer를 거쳐 최종적으로 갖게 되는 차원입니다.
-
- 필요한 요소들
- 최종 input size 설명
-
Attention
- 이미지
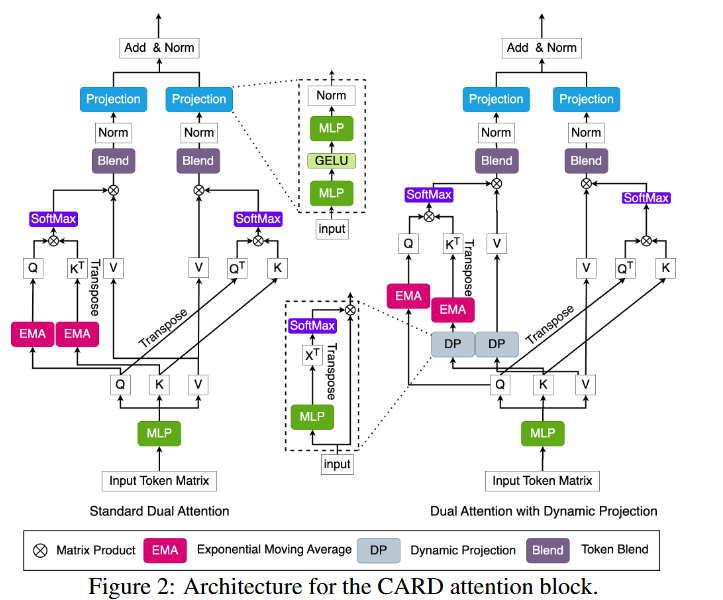
3.1 Attention over Channel Dimension
- 서로 다른 채널(변수) 간의 상관관계 파악
- Process
- 데이터 준비
- tokenize로 얻은 “패치된 토큰 텐서” (C,N,P)
- C : 채널 수, N: 토큰 개수, P: 패치 길이
- tokenize로 얻은 “패치된 토큰 텐서” (C,N,P)
- Q, K, V 생성
- Dynamic Projection 기법 사용
- MLP layer에서 head dimension을 줄여 “요약된” 토큰 정보 얻음
- attention 연산의 computational cost 줄이기 위함
- dynamic에 대한 추가 설명
- 모든 정보를 동일하게 취급하여 단순히 차원을 축소하는 것이 아니라, 데이터의 특성에 따라 중요한 정보는 보존하고 불필요한 정보는 제거하는 방식으로 차원을 축소
- 차원 축소를 통해 attention 연산의 computational cost가 줄어든다고 봄
- input data에 따라 동적으로 중요한 정보를 선택
- 시계열 데이터의 각 시점(time step)마다 중요한 채널이 다를 수 있다는 점을 고려
- 모든 정보를 동일하게 취급하여 단순히 차원을 축소하는 것이 아니라, 데이터의 특성에 따라 중요한 정보는 보존하고 불필요한 정보는 제거하는 방식으로 차원을 축소
- DP block module에서의 작동원리
def dynamic_projection(self,src,mlp): src_dp = mlp(src) src_dp = F.softmax(src_dp,dim = -1) src_dp = torch.einsum(’bnhef,bnhec -> bnhcf’,src,src_dp)- K (Key)와 V (Value) 텐서 처리:
DP Block은 어텐션 연산에 사용될 Key (K)와 Value (V) 텐서를 입력으로 받음 - MLP 레이어 적용:
DP Block 내의 MLP 레이어 및 는 Key와 Value 텐서의 head dimension을 줄이는 역할
이때, MLP 레이어는 각 차원의 중요도를 학습하고, 중요한 정보는 보존하고 불필요한 정보는 제거 - Softmax 정규화:
MLP 레이어를 통과한 텐서에 소프트맥스 함수를 적용하여 각 차원의 가중치를 정규화, 이를 통해 각 차원의 중요도를 0과 1 사이의 값으로 표현 - 요약된 토큰 생성:
정규화된 가중치를 사용하여 Key와 Value 텐서를 가중합, 이를 통해 head dimension이 축소된 "요약된" 토큰을 생성 - 어텐션 연산:
요약된 토큰은 어텐션 연산에 사용되어 계산 복잡도를 줄이면서도 중요한 정보를 보존
- K (Key)와 V (Value) 텐서 처리:
- MLP layer에서 head dimension을 줄여 “요약된” 토큰 정보 얻음
- attention score 계산
- softmax 함수 적용
- Value와 같이 weighted sum 진행
- output - 새로운 tensor 형태 (C,N,P)
- 데이터 준비
3.2 Attention over Token Dimension
-
토큰 간의 temporal dependency 파악하고 이를 모델링에 활용
-
시계열 데이터, 시간적 의존성 파악하는 것 매우 중요
-
Process
-
데이터 준비
- 3.1 에서 진행한 채널 차원에서의 어텐션 최종 output을 input으로 사용
- 이 tesnor (C, N, P)의 형태 가짐
- 3.1 에서 진행한 채널 차원에서의 어텐션 최종 output을 input으로 사용
-
Q, K, V 생성
-
Exponential Moving Average (EMA)
- EMA를 Q와 K에 적용하여 각 query 토큰이 더 많은 key 토큰에 대해 더 높은 attention score 얻음
는 smoothing factor로 0~1 사이의 값, 값이 클수록 최근 값에 더 큰 가중치 부여
→ 현재 시점에서의 정보 뿐만 아니라 과거의 정보까지 포함 (즉, 더 넓은 시간 범위의 정보를 “기억”)
→ 이는 Q, K attention score 연산 시, 각 query 토큰은 더 많은 key 토큰들과 유사한 패턴 공유하게 됨.
→ 결국 두 토큰이 유사한 패턴을 가진다면, 더 높은 attention score를 가지게 됨.
→ 이는 각 query 토큰은 자신과 관련된 정보를 더 많이 활용할 수 있게 됨.
→ EMA는 최근 값에 더 큰 weight를 주기 때문에 과거의 이상치가 현재 attention score에 미치는 영향이 크지 않음.
→ 이는 anomaly에 robust한 예측 가능하게 함.
-
attention score 계산
-
softmax 함수 적용
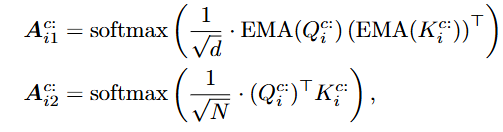
-
Value와 weighted sum 진행
-
outout - 토큰 차원에서의 어텐션 결과는 각 채널별로 시간적 의존성이 고려된 새로운 텐서가 됨
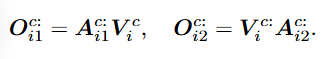
-
CARD 모델은 3.1 채널 차원에서의 어텐션 연산과 3.2 토큰 차원에서의 어텐션 연산 번갈아가면서 수행
- 채널 간의 inter-dependency와 temporal-dependency를 모두 고려해서 시계열 데이터의 복잡한 구조 학습
- information fusion 서로 다른 채널의 정보와 시간적 정보를 융합
- robustness
- 이미지
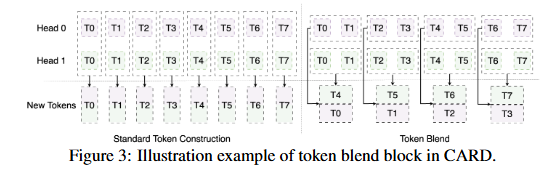
- Standard Token Construction은 사실 new token 만드는 게 concat에 불과함.
- 하지만 Token Blend Module은 output token에 대해서 tensor 형태도 rearrange해서 인접한 토큰들이 섞이도록 함.
- 즉 Token Blend 작업은 텐서의 차원을 재배열하여 인접한 토큰들의 정보를 섞는 과정,이는 multi-scale 정보를 효과적으로 활용하기 위한 특별한 방식
- 코드
def forward(self, src, *args,**kwargs): # construct Q,K,V B,nvars, H, C, = src.shape qkv = self.qkv(src).reshape(B,nvars, H, 3, self.n_heads, C // self.n_heads).permute(3, 0, 1,4, 2, 5) q, k, v = qkv[0], qkv[1], qkv[2] if not self.over_channel: attn_score_along_token = torch.einsum(’bnhed,bnhfd->bnhef’, self.ema(q), self.ema(k ))/ self.head_dim ** -0.5 attn_along_token = self.attn_dropout(F.softmax(attn_score_along_token, dim=-1) ) output_along_token = torch.einsum(’bnhef,bnhfd->bnhed’, attn_along_token, v) else: # dynamic project V and K v_dp,k_dp = self.dynamic_projection(v,self.dp_v) , self.dynamic_projection(k,self. dp_k) attn_score_along_token = torch.einsum(’bnhed,bnhfd->bnhef’, self.ema(q), self.ema( k_dp))/ self.head_dim ** -0.5 attn_along_token = self.attn_dropout(F.softmax(attn_score_along_token, dim=-1) ) output_along_token = torch.einsum(’bnhef,bnhfd->bnhed’, attn_along_token, v_dp) # attention over hidden dimensions attn_score_along_hidden = torch.einsum(’bnhae,bnhaf->bnhef’, q,k)/ q.shape[-2] ** -0.5 attn_along_hidden = self.attn_dropout(F.softmax(attn_score_along_hidden, dim=-1) ) output_along_hidden = torch.einsum(’bnhef,bnhaf->bnhae’, attn_along_hidden, v) # token blend output1 = rearrange(output_along_token.reshape(B*nvars,-1,self.head_dim), ’bn (hl1 hl2 hl3) d -> bn hl2 (hl3 hl1) d’, hl1 = self.n_heads//self.merge_size, hl2 = output_along_token.shape[-2] ,hl3 = self.merge_size ).reshape(B*nvars,-1,self.head_dim*self.n_heads) output2 = rearrange(output_along_hidden.reshape(B*nvars,-1,self.head_dim), ’bn (hl1 hl2 hl3) d -> bn hl2 (hl3 hl1) d’, hl1 = self.n_heads//self.merge_size, hl2 = output_along_token.shape[-2] ,hl3 = self.merge_size ).reshape(B*nvars,-1,self.head_dim*self.n_heads) # post_norm output1 = self.norm_post1(output1).reshape(B,nvars, -1, self.n_heads * self.head_dim) output2 = self.norm_post2(output2).reshape(B,nvars, -1, self.n_heads * self.head_dim) # add & norm src2 = self.ff_1(output1)+self.ff_2(output2) src = src + src2 src = src.reshape(B*nvars, -1, self.n_heads * self.head_dim) src = self.norm_attn(src) src = src.reshape(B,nvars, -1, self.n_heads * self.head_dim) return src
-
4. Signal Decay-Based Loss Function
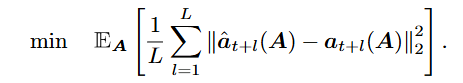
-
overall objective loss
-
기본적인 MSE 손실 활용 (l2 norm의 제곱) —> 모든 예측 시점에 대한 오차를 동일하게 취급 . 하지만, 실제로는 먼 미래의 예측은 불확실성이 더 크기 때문에 이 점을 고려한 loss식 필요
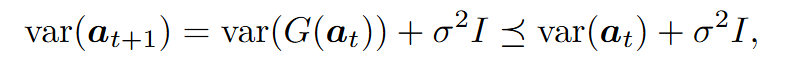
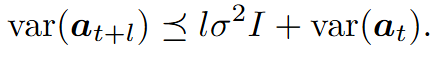
-
초기 loss 함수 (Negative Log-likelihood estimation)
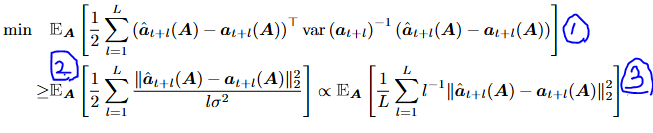
-
1번 식에 markov process 가정 및 분산 추정 적용 (1차 Markov Process 따른다고 가정) 이는 예측 시점이 멀어질수록 불확실성이 커진다는 것을 의미 은 noise의 분산 는 identity matrix 활용
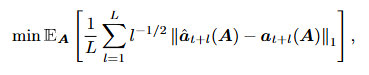
- 최종 loss function
- 위 3번식에서 도출
5. Experiments
5.1 Long Term Forecasting
기존 SOTA 모델 혹은 baseline 모델들 대비 특히 일부 데이터셋에서 높은 성능을 보임.
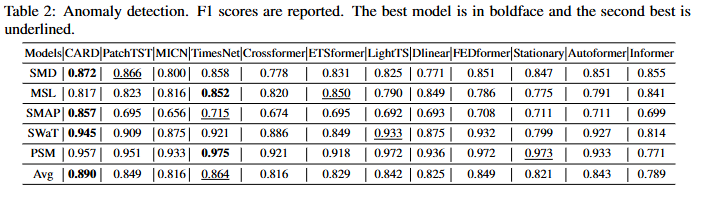
5.2 Reconstruction based Anomaly Detection
특정 데이터셋에서는 TimesNet 혹은 PatchTST 모델이 높은 성능을 보였지만, 전체 평균 Avg에 대한 성능 결과는 CARD가 압도적이다.
5.3 Boosting Effect of singal Decay-Based Loss Function
Signal Decay-Based Loss Function의 효과
- MSE 감소 효과, 기존의 MSE 손실함수 대신 이 손실 함수를 사용 했을 때, Transformer, CNN, MLP에서 3~12% loss 감소
- 제안하는 손실 함수는 특히 주파수 영역 정보를 많이 활용하는 FEDformer와 Autoformer의 성능을 향상
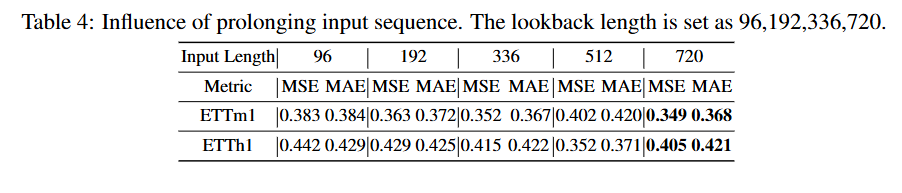
5.4 Influence of Input Sequence Length
기존의 long term forecasting 트랜스포머 모델들은 긴 입력 시퀀스를 효과적으로 활용 x
input length가 길어짐에 따라 성능 저하되는 문제점 보임
→ 하지만 CARD는 이런 단점 본질적인 문제 x / input sequence가 더 길고, 노이즈가 많은 과거 시퀀스 입에서도 robust한 성능 유지 설명
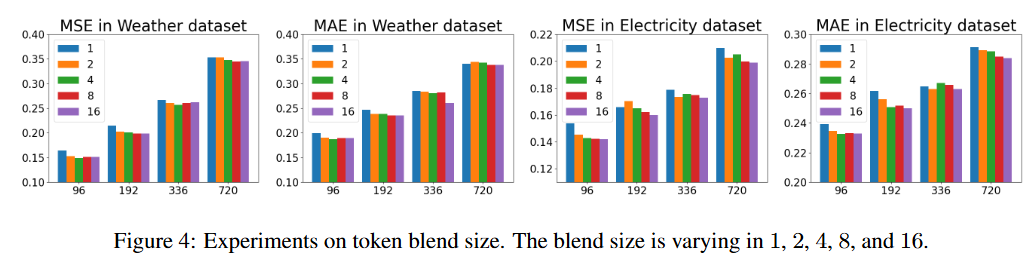
5.5 Influence of Token Blend Size
일반적으로 token blend가 1에 가까울수록 즉, 표준 token blend일 경우 loss가 높게 나오는 경향 보임
→ 따라서 token blend size를 키울수록 성능 향상에 도움이 됨
6. Conclusion
-
새로운 Transformer 모델 (CARD): 이 논문에서는 시계열 예측을 위한 새로운 Transformer 모델인 CARD를 소개
-
채널 의존적 (Channel-dependent) 모델: CARD는 채널 의존적인 모델로, 다양한 변수와 숨겨진 차원 (hidden dimensions) 간의 정보를 효과적으로 정렬
-
Attention 메커니즘 개선: CARD는 토큰과 채널 모두에 attention을 적용하여 기존 Transformer를 개선
-
Attention 메커니즘 설계: 새로운 attention 메커니즘 설계는 각 토큰 내의 로컬 정보를 탐색하여 시계열 예측에 더 효과적
-
토큰 블렌드 모듈 제안: 시계열 데이터에서 다중 스케일 정보 지식 (multi-scale information knowledge) 활용을 위한 토큰 블렌드 모듈을 제안
-
Robust 손실 함수 도입: 시계열 분석의 중요한 문제인 과적합 (overfitting) 문제를 완화하기 위해 robust 손실 함수를 도입
-
우수한 성능: 다양한 수치 벤치마크를 통해 제안된 모델이 최첨단 모델보다 성능이 우수함을 입증
