목차
0. Abstract
1. Introduction
2. Related Works
3. Methodology
4. Experiments
5. Conclusion
Paper Overview
- LLM의 뛰어난 지식과 추론 능력을 활용하여 설명가능한 금융 시계열 예측을 다룬 새로운 연구 제안
- Finance domain에 대한 LLM의 Potential을 탐구하려고 시도
- Stock price data, Company profile data, Finance/Economy news data 등 Stock price forecasting에 영향을 줄 수 있는 다양한 modality의 Data를 통합하여 사용
- GPT-4를 통한 Zero-shot 만으로도 다른 Statistical, ML 모델들보다 더 뛰어난 성능 보임 확인
0. Abstract
💡 Finance domain에서 ML & DL 모델을 사용하기 위해 고려해야 할 부분- Cross-Sequence reasoning and inference
- Time-Series data가 가지는 복잡한 dependence 특징을 포착해야 한다.
- 데이터 내의 Temporal pattern을 이해하는 것은 정확한 예측을 하는 데에 있어서 필수적이다.
- Complex multi-modal finance temporal data
- 정확한 주가 예측을 수행하기 위해, 단순히 numerical seqeunce로 이뤄진 주가 뿐만 아니라, 해당 주식에 관련된 다른 금융 데이터(과거 뉴스, 거시경제 시장 지표, 차트 흐름 등)을 함께 처리해야 함.
- Interpretability and explainability
- DL 모델의 Black Box는 의사결정을 하는 데에 적은 부분의 insight밖에 주지 못함
- 투명성 부족 ← 신뢰성에 대한 우려 발생 + 사용자의 신뢰 저하 가능 / 이는 막대한 투자와 자산이 걸려있는 금융 관련 분야 더욱 중요
1. Introduction
앞서서 언급된 3가지 문제점에 대해서 LLM을 활용함으로써 얻을 수 있는 장점 및 해결
- Cross-Sequence reasoning and inference
- Transformer 계열의 모델은 input으로 들어온 text sequence 간의 관계를 모두 고려한다, 따라서 데이터의 복잡한 관계 또한 학습할 수 있음.
- LLM은 시계열 데이터 내의 complex relation을 학습할 수 있다고 봄.
- Complex multi-modal finance temporal data
- LLM은 학습 시에 다양한 주제, 스타일, 형식을 아우르는 많은 양의 데이터로 학습
- Numerical market data, textual news, articles, social media post 등 서로 다른 source 가지는 데이터가 많은 financial forecasting task에서 유용하다.
- Interpretability and explainability
- LLM은 인간이 이해할 수 있는 형태의 설명을 생성하는 능력이 있습니다. 이는 모델의 예측에 대한 신뢰를 높이고, 추론 과정에 대한 명확한 설명을 제공한다.
2. Related Works
2.1 Traditional Statistical / Econometric Methods
- ARMA-GARCH 모델 → 전통 통계적/계량경제학적 기법, 오랜 기간 financial time-series 예측의 핵심 방법으로 자리잡음
- 이런 모델 → 금융 시계열에서 의존성과 변동성 군집을 capture하는 능력 널리 사용
- 모델 종류
- 벡터 자기회귀 모델(Vector Autoregressive Models, VAM)
- 상태 공간 모델(State-Space Models)
- 칼만 필터(Kalman Filter)
- 확산 모델(Diffusion Models)
- 벡터 오류 수정 모델(Vector Error Correction Model, VECM)
- 동태적 확률 일반 균형(DSGE)
2.2 Machine Learning Techniques
- Decision Tree, SVM 등과 같은 설명력이 충분한 기법들이 적극적으로 사용 됨
- 그러나 최근 RNN, CNN, Transformer 계열의 모델과 같은 딥러닝 모델이 이 작업에 적용 → 이는 복잡하고 비선형적인 관계를 더욱 더 잘 표현할 수 있다.
2.3 Large Language Models
- GPT-3, GPT-4, LLaMA(Alpaca, Vicuna 등 포함)가 대표적인 LLM
3. Methodology
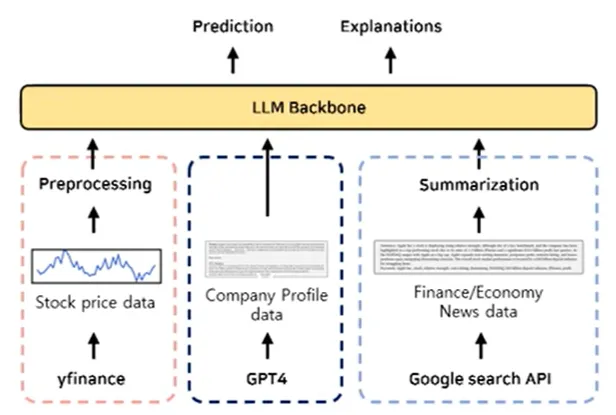
3.1 Data
-
input
3.1.1 : NASDAQ-100 stock price data (from yfinance)
- Numerical price time-series를 percentage-change time series로 Normalize 진행, Percentage Change를 bin로(범주화) 분류
- 주간 예측 예시 (이번 주와 지난 주 사이의 가격 변화를 12개 구간으로 나눔
- "D5+", "D5", "D4", "D3", "D2", "D1", "U1", "U2", "U3", "U4", "U5", "U5+”
D5+는 5% 이상 하락,U5+는 5% 이상 상승을 의미- Di는 (i-1)%에서 i% 사이의 가격 하락 의미
- Bin의 숫자는 granularity(주,월 등)에 따라 달라짐
-
3.1.2 : Company Profile data : GPT 4를 이용
- company description - general positive/negative factors (description) - 예시 이미지(figure 1)
- 회사 설명: Apple은 아이폰, 아이패드, 애플 워치 등의 제품을 제조하는 미국 캘리포니아에 본사를 둔 기술 회사입니다.
- 긍정적인 요인: 경제 성장, 기술 혁신, 성공적인 제품 출시, 법적 규제 완화 등.
- 부정적인 요인: 인플레이션, 기술 혁신 지연, 환경 규제 등.
- 회사 설명: Apple은 아이폰, 아이패드, 애플 워치 등의 제품을 제조하는 미국 캘리포니아에 본사를 둔 기술 회사입니다.
-
3.1.3 : Finance/Economy News data : GPT 4 이용
- Google Custom Search API 사용 → NASDAQ-100 주식에 대한 주간 뉴스 상위 5개 가져옴 - 위와 같은 방식으로 Macro economy와 현재 금융 현황에 대해서 똑같이 진행 - 예시 이미지(figure 2)
- 한 주 모든 뉴스 요약과 키워드 ← 메타 요약으로 통합한 예시 제공 (figure 3) - 예시 이미지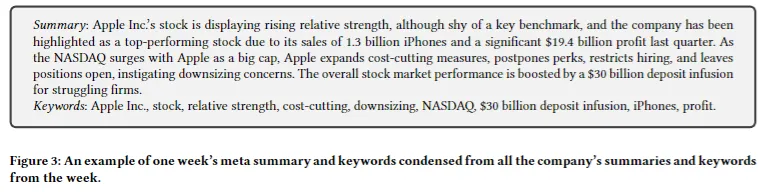
3.2 Instruction-Based Zero-shot/Few-shot Inference with LLMs
zero-shot, few-shot inference 실험에서 다음 instruction-based prompt 사용

- instruction-based prompt 이미지
-
Prompt 구조
- Instruction
- Company Profile
- 과거 뉴스 요약 및 키워드
- Categorized stoch price
- cross-sequence few-shot learning example 포함
-
Cross-sequence few-shot learning example ?
→ 예측하고자 하는 종목과 유사한 종목의 주가 의미
- 이 논문에서는 “AAPL”를 기준으로 GPT-4를 통해서 예시 도출
→ “AAPL”과 가장 유사한 나스닥 주식 상위 3개 ⇒ “MSFT”, “GOOGL”,”AMZN”
-
- Prompt 구조와 Instruction은 경험적으로 고정
3.3 Insturction-based Fine-tuning with Open LLaMA
- LLaMA 13B를 통해서 Instruction based fine-tuning 진행
- LLaMA 13B 특징
- zero-shot에서 보통 Prompt에 대한 명령들을 효과적으로 실행 x → 그저 Prompt의 일부를 복제하는 경향 있음
- 따라서 Fine-tuning 과정 거치지 않는다면, 정상적인 Inference 불가능하다.
- Binary Classification에 대해서 GPT4와 대등한 성격 보이나, D5+, U5+와 같은 극단적인 예측을 더 생성하는 경향있어서 Higher Squared Error 발생함.
- fine-tuning된 LLaMA의 output 예시

해석
요약: 주식 시장은 Apple의 비용 최적화와 신제품 출시 및 시장 확장을 통한 수익 창출에 긍정적으로 반응할 가능성이 높습니다. 규제 문제에도 불구하고, 회사의 환경적 책임 이행과 금융 상품의 다양화 노력은 장기적인 전망에 긍정적인 영향을 미칠 것으로 예상됩니다. 결과적으로 Apple의 주가는 또 한 번의 강력한 성장 주를 보일 것으로 예상되며, 예상 수익률은 U5+입니다.
키워드: 비용 절감, 신제품 출시, 확장, 규제, 공급망
주가 수익률: U5+
4. Experiments
4.1 Experiment Setup
- Data time window
- Baseline 모델과 LLaMA 모델 모두 training이 필요함
- 2017/06/12~2022/06/05까지의 5년치 데이터 사용하여 Training
- ++ 2022/06/05 ~ 2023/06/04까지의 52주간의 데이터를 통해 Evaluation
- Baseline 모델과 LLaMA 모델 모두 training이 필요함
- Baseline Models
- ARMA-GARCH (p=q=1) → 통계 기반
- LightGBM
- Gradient-boosting tree model
- Eval metrics
- Binary precision : 등락( D or U )을 정확하게 맞추는 것
- Bin precision : 등락률 (D1, D2, … )을 정확하게 예측하는 것
- MSE of consecutive bin ordinals : -6(D5+) ~ 5(U5+)까지의 MSE 계산
- GPT 4가 도출하는 summary 및 keyword 들에 대해서 ROUGE 1 및 ROUGE 2 도출
- ROUGE 설명 https://ariz1623.tistory.com/307
- ROUGE 설명 https://ariz1623.tistory.com/307
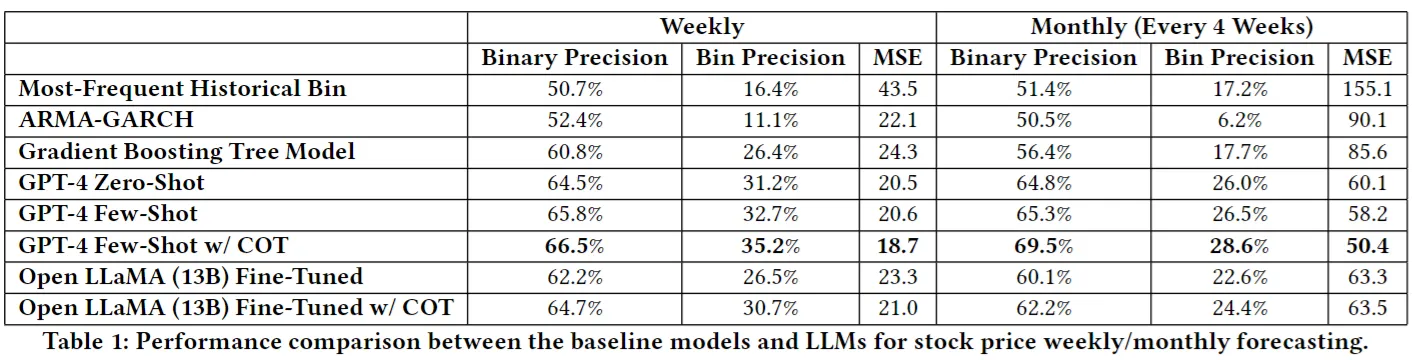
Forcasting stock return
- LLM 기반 모델들이 baseline model들 보다 더 나은 성능 보이고 있음
- 특히 GPT-4 Few-Shot w/ COT 모델이 가장 좋은 성능 보임, MSE가 10대로 떨어지는 것을 봤을 때, prediction direction에 관한 예측 뿐만 아니라 더 정확하게 변화를 포착함
- LLaMA
- Fine-tuning 이후 bin Precision 성능이 좋지 않음 → fine-grained Reasoning 능력 부족
- MSE 값이 높은 것으로 봤을 때, 예측 시 양 극단적인 값을 예측하는 경우가 많은 것으로 판단 가능

Explanations generated by the LLM
- LLM이 생성한 Summary(S)와 Keyword(K)에 대해서 평가
- GPT-4 few-shot with COT가 가장 높은 ROUGE score 달성
5. Conclusion
- 기존 ML/DL 모델들이 금융 도메인에서 data를 다룰 때 어려움을 겪는, Cross-Sequence reasoning or inference, Complex multi-modal data, 설명력 부족 등에 문제점 → LLM을 통해 극복하고자 함.
- Point-wise 예측이 아닌, 등락 및 등락률 (주간 예측 기준 12개의 등락/등락률로 나눔)을 예측하고자 한 점이 인상 깊음 → 현실적으로는 정말 point-wise 보다는 등락/ 등락률만을 정확하게 예측하더라도 실제로 유의미한 결과를 얻을 수 있다고 생각
- 처음 이 금융 도메인에서 LLM을 이용한 것에 대한 potential을 보이는 것에 contribute를 가짐
- DSBA 세미나 유튜브 영상을 참고해서 작성한 내용입니다.
